
原文:Sunny Weather Forecast for ARM’s Cost of Solution in Cloud HPC Published 25/08/2020 By Branden Moore
クラウド HPC における ARM のソリューションコスト(nAG 技術者ブログ記事)
クラウドコンピューティングの主要な推進要因の一つは、社内では容易に利用できないアーキテクチャやシステムへのアクセスです。その一例として、AWS が最近、独自にカスタム設計した Graviton 2 プロセッサ を導入したことが挙げられます。このプロセッサは、Intel や AMD の x86 ベースのアーキテクチャではなく、ARM アーキテクチャをベースにしています。当社では、多くのクライアントから、ARM が HPC のニーズにどの程度適しているのかについて問い合わせを受けています。公開されているベンチマークはいくつかありますが、私は午後の時間を利用して自分で試してみることにしました。
このために、私は天気コード WRF v3.9.1.1 をベンチマークすることにしました。 WRFv3 には、異なる解像度(12km と 2.5km の解像度)の2つの「伝統的な」ベンチマークがあります。どちらのベンチマークも3時間のシミュレーションを行います。小さい方のベンチマーク(解像度 12km)は一般的に数百コアまで、大きい方のベンチマーク(解像度 2.5km)は数千コアまでスケールします。しかし、今回のベンチマークでは、単一のノードで実行しました。また、今回のテストは自分の好奇心を満足させるためだけのものなので、統計的変動を捉えるために通常行うような複数回の再実行は行いませんでした。
私はベンチマークのハードウェアとして、Intel、AMD、ARM の各製品を比較してみたいと思っていました。AWS は現在、大手クラウドプロバイダーの中で唯一、AWS Graviton 2 プロセッサを搭載した ARM ベースのインスタンスを提供しています。そのため、今回のベンチマークでは、AWS 上の C5、C5a、C6g のインスタンスタイプにたどり着き、"フルノード" を得るために、利用可能な最大のインスタンスタイプを選択しました。ベンチマークに使用したシステムはすべて、OS として Amazon Linux 2 を使用し、GCC 9.3.0 をインストールし、WRF の依存関係[1] を構築するために Spack を使用したので、ARM 向けのビルドは Intel や AMD 向けのビルドと比較して特に難しいという事はありませんでした。WRF 自体をビルドする際に、デフォルトのコンパイル設定を変更したのは、GNU/Linux の設定セクションに 'aarch64' アーキテクチャを追加することと、ターゲットプラットフォームに最適化するためのチューニングパラメータ(-march=native -mtune=native)を指定する事だけでした。

図1を見れば、このベンチマークは完全な比較ではないことは明らかです。C5(Intel)インスタンスはデュアルソケット構成ですが、C5a(AMD)と C6g(ARM)インスタンスはどちらもシングルソケットです。C5 と C5a の両方に SMT(別名、ハイパースレッディング)がありますが、C6g にはありません。しかし、基盤となる CPU 構成ではなく、各インスタンスが提供するパフォーマンスを比較することを検討すると、比較ははるかに簡単になります。
結果
SMT / ハイパースレッディング
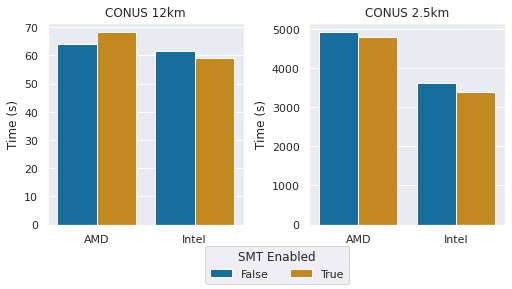
多くの HPC アプリケーションは、SMT の使用中にパフォーマンスの低下を示します。そのため、多くの HPC センターはそれを無効にします。 私は、このベンチマークがそれに当てはまるかどうか再確認したいと思いました。上記テーブルをざっと見てみると、今回のケースでは、WRF に Intel と AMD の両方のシステムで SMT を使用する(つまり、96 スレッドをすべて使用する)ことでパフォーマンスの優位性があることがわかりますが、その差はわずかです。また、デュアルソケットの Intel システムは、より大きなベンチマークでシングルソケットの AMD システムを大幅に上回っていることがわかりますが、これはシステム全体のメモリ帯域幅が高いことが原因である可能性が高い[2] です。この記事の残りの部分では、「フルインスタンス」という言葉は、インスタンスに利用可能なすべての vCPU を使用する事を意味します。
図1: SMT を使用した場合と使用しない場合の比較(短いほど良い)
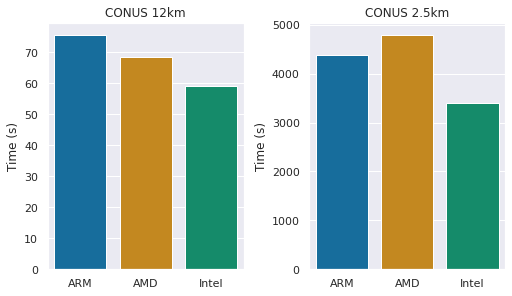
WRF における、ARM、Intel、AMD におけるパフォーマンスの比較
図2は、3つのアーキテクチャで両ベンチマークを実行した際の、WRF の総計算時間(起動時間やディスクへの結果の書き込みを含まない)を示しています。AWS の Graviton 2 チップが非常に競争力のある性能を発揮していることがわかります。小規模ベンチマーク(解像度 12km)では3つのベンチマークの中で最も遅いですが、大規模ベンチマーク(解像度 2.5km)では AMD を凌駕しています。また、Intel ベースのシステムは、ARM と AMD の両方に比べて、他に類を見ないほどの性能の優位性を示しています。
図2: フルインスタンス(全ての vCPU)を使用した場合の計算時間(短いほど良い)
私は、Graviton 2 プロセッサで利用可能なより高速なメモリ速度が、大規模ベンチマークで AMD システムよりもパフォーマンスが優れている主な理由であると思っています。AWS がデュアルソケット AMD Rome インスタンスタイプを導入する場合、これはもちろん再検討する必要があります。Intel プロセッサのより高いクロック速度と2つのソケットを持つことによるメモリ帯域幅の増加により、パフォーマンスが大幅に向上しています。
WRF における、ARM と Intel と AMD のコストの比較
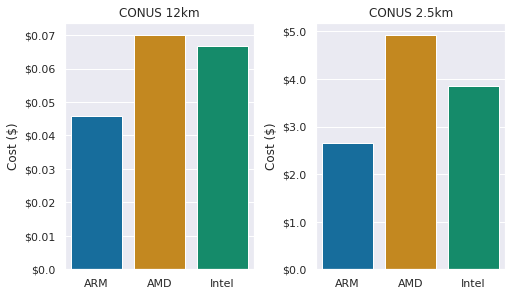
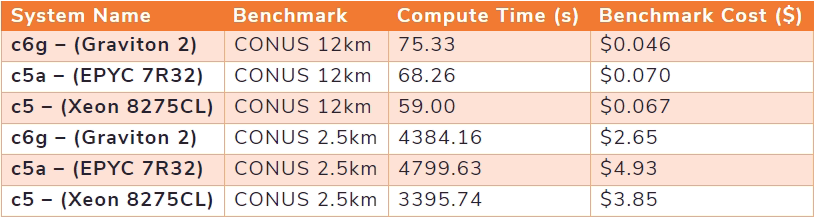
今回の調査は「クラウド」で行われるため、ベンチマークの際にはコストも考慮することが必要です。 AWS は、Graviton 2 製品を非常に競争力のある価格で提供しています。 各インスタンスのベンチマークコスト(現在のところ、US-EAST-2 リージョンでは、オンデマンド料金)は、Intel システムが $4.08/時間、AMD システムが $3.70/時間、そして Graviton 2 システムが $2.18/時間 でした。
1時間あたりの価格に実行時間を掛けて、ソリューションのコストを算出します。図3が示すように、Intel ベースのインスタンスは ARM ベースのインスタンスよりもはるかに高いパフォーマンスを持っていますが、コストを考慮した場合、Graviton 2 は(ソリューションに到達するまでにより長い時間がかかりますが)、より低いコスト対ソリューションを提供してくれます。
図3: コストの比較(安いほど良い)
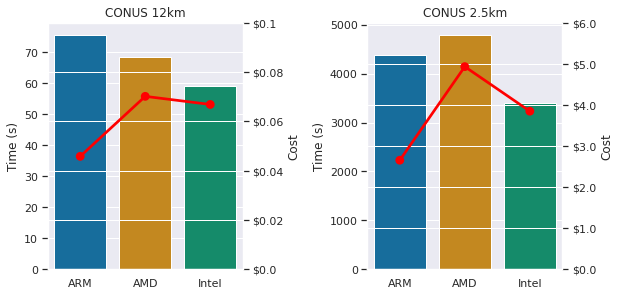
これらのプラットフォームでの WRF のパフォーマンスとコストの間には、明確なトレードオフがあります。2.5km ベンチマークでは、理想的には、Intel ベースのソリューションのパフォーマンスが、ARM ベースのものより安価に実現できるポイントがあるかどうかを確認するために、スケーリング調査も行いたいところです。
図4: コストとパフォーマンスの比較(短いほど良い)
AMD EYPC や ARM HPC のエコシステムが成熟するにつれ、これらのアーキテクチャをターゲットとしたコンパイラ(AMD の AOCC や ARM の Allinea Studio など)や他の LLVM ベースのコンパイラによるパフォーマンスの向上が期待できます。過去には、Intel コンパイラが、gfortran よりも優れた仕事をしていることを見てきました。このベンチマーク研究を、追加のコンパイラで再検討してみるのも面白いかもしれません。
まとめ
本記事では、HPC における ARM プロセッサの適合性についての質問に答えて、人気のある HPC ベンチマークの一つである WRFv3 を3種類の「計算に最適化された」AWS インスタンス上で実行しました。AWS の ARM ベースのカスタム製品は、このベンチマークで利用できる最速のプロセッサではありませんが、非常にコスト効率の高いソリューションを提供しており、パフォーマンスは他のより伝統的な HPC プロセッサと比較しても遜色がないことがわかりました。
様々な HPC ハードウェアソリューションの詳細なベンチマークやパフォーマンス分析にご興味のある方は、ぜひ お問い合わせ 下さい。
関連情報
[1] 私は最初に GCC 10 を使用しようとしましたが、gfortran 10 と WRF はうまく機能していないようです。libgfortran のルーチンが原因で、WRF が実行時にクラッシュしました。
[2] AWS が他のクラウドプロバイダーで利用できるようなデュアルソケット AMD Rome インスタンスサイズを導入する場合、パフォーマンスプロファイルは大幅に変化するはずです。これは再検討する価値があります。