
イントロダクション
NAMD は HPC ベンチマークで人気のある選択肢であり、AMD、Intel、Nvidia はすべて最近高性能を主張しています。Intel は最近、AVX-512 を使用して NAMD を高速化する パッチ を提供し、これらの最適化によりパフォーマンスが最大 1.8 倍向上し、最新の AMD ハードウェアよりも優れていると主張しています。Intel は、AVX-512 ベクターユニットと最新世代の Intel Xeon CPU の大容量キャッシュを非常に効率的に使用する「タイル」アルゴリズムを実装することにより、1.8 倍のパフォーマンス向上を実現しました。これは、CUDA 対応バージョンの NAMD で使用されているものと同じタイリングアルゴリズムのポートです。
どのくらいの速さで実行されますか?いくらかかるでしょうか?
私たちは自分たちで、これらのパッチを試し、AMD と Nvidia の両方のハードウェアで、それぞれどのくらいのパフォーマンス向上が得られるかに興味を持っていました。特に、NAMD をクラウド環境で実行する場合には、「どれくらいの速度で実行できるか」だけでなく、「どれくらいのコストで実行できるか」という点に問題があることが多いので、これがどのような状況であるかを確認したいと思いました。
これを調べるために、AMD と Intel の HPC クラスの VM を使用して Microsoft Azure 上でベンチマークを行いました。
ベンチマーク
ベンチマークに使用したインスタンスタイプは次のとおりです。

これらの VM の仕様は、AMD と Intel が採用したさまざまなアプローチを反映しています。AMD EPYC プロセッサは、クロック速度の低い多数のコアを提供しますが、Intel Xeon CPU は、より高度なベクトル化ハードウェアを備えた少数の高速コアを提供します。(ここに表示されている価格は、これが公開されたときの「West US 2」地域のものですが、価格は地域や時間の経過とともに異なります。)
ベンチマークインスタンスは Centos 8.2 イメージでプロビジョニングしました。NAMD 2.15a1 パッケージとその依存関係は、Spack HPC パッケージマネージャを使用してインストールしました。
我々は、シングルノードベンチマークに最も適したベンチマークとして、ApoA1(92,224 原子)とSTMV(1,066,628 原子)を選択しました。通常、NAMD ベンチマークの結果は、1日の計算時間(ns/day)あたりのシミュレーション時間がナノ秒単位で報告されます。しかし、我々は解決までのコストに関心があるので、シミュレーション時間のナノ秒あたりの計算コスト($/ns)で性能を計算する方がより有用です。各ベンチマークは、実行から実行へのばらつきを把握するために、各構成で 10 回実行しました。
結果
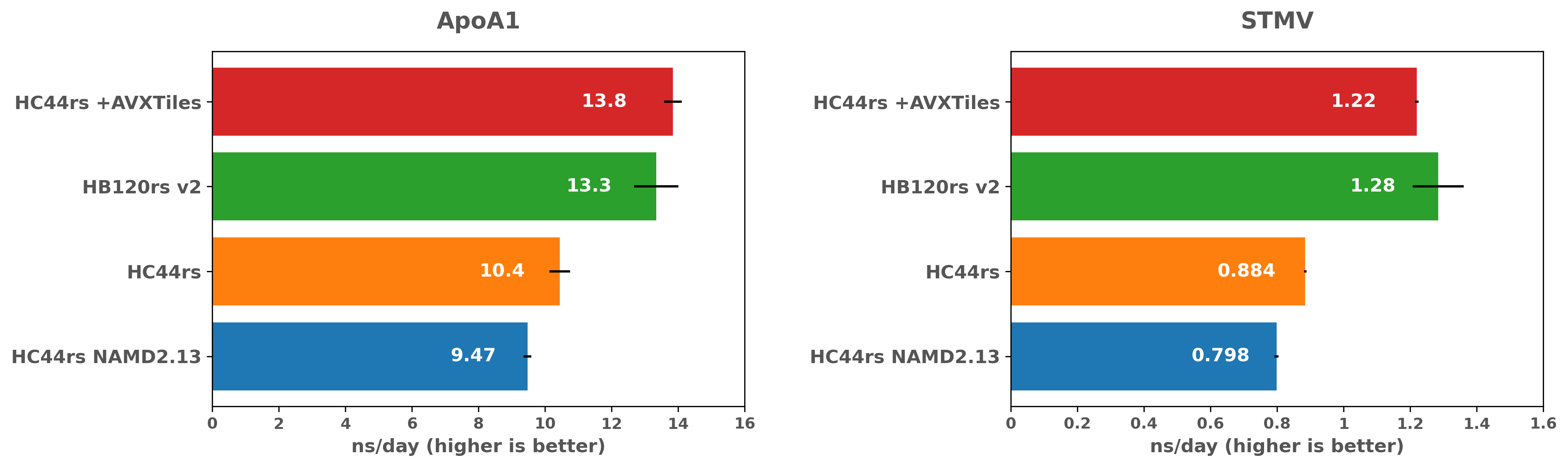
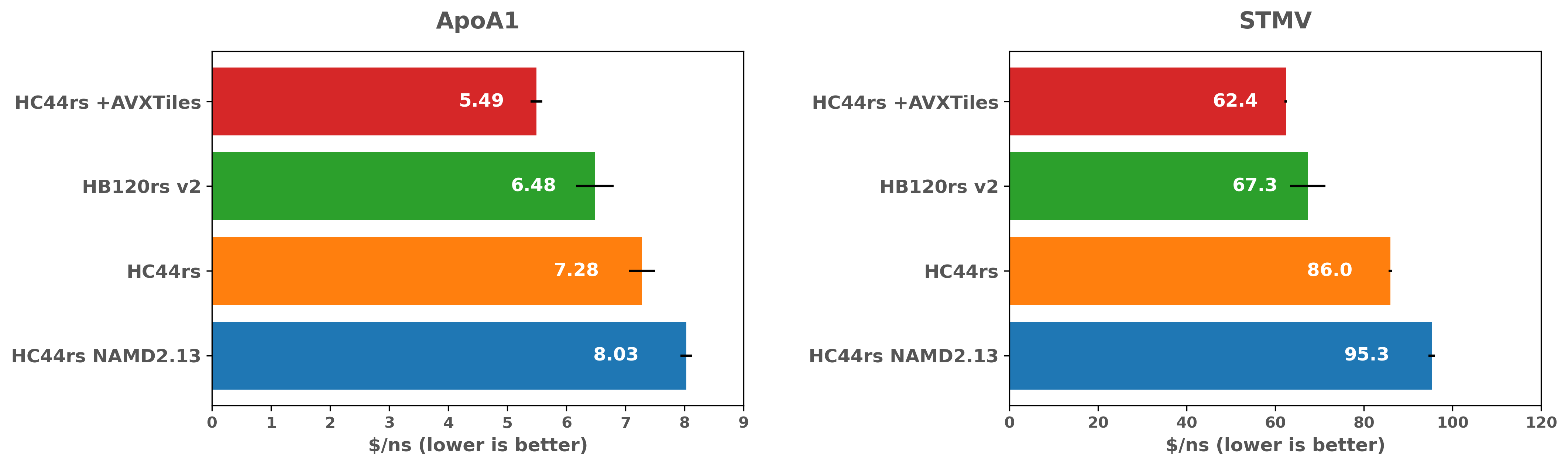
結果は、両ベンチマークとも最新の Intel の最適化により、NAMD 2.13 と比較して約 1.5 倍のスピードアップを示しており、ApoA1 ベンチマークでは AMD と比較して Intel がパフォーマンスとコスト面で優位に立っていることを示しています。しかし、STMV については、状況はそれほど明確ではありません。問題サイズが大きくなっても、HC44rs VM の時間当たりの価格が低いため、コスト効率の面ではインテルの方が優れた選択肢であることに変わりはないものの、AMD はインテルよりも性能面で優位に立っています。AMD の性能が優れているのは、EPYC ベースのシステムで利用可能なメモリ帯域幅が大きいためかもしれないので、更なる調査をすることも興味深いと思います。
NAMD シミュレーションパフォーマンスの比較(Intel 対 AMD)
NAMD シミュレーション費用対効果の比較(Intel 対 AMD)
GPU を使った場合は?
最近では、GPU アクセラレーションを使用してNAMDを実行することが非常に人気があります。 これにより優れたパフォーマンスが得られますが、クラウドの GPU は高額になる可能性があります。 パフォーマンスとコスト効率の両方について、新しい Intel 最適化が GPU を利用した場合と比べてどのような状況であるかを知りたいと思いました。
今回選んだ GPU VM は NC6s v3 タイプで、価格は 3.06 ドル/時間のものでした。これは Azure が提供する中で最も安価な GPU VM の1つで、NVIDIA V100 カード1枚、112GB の RAM、6つの Xeon E5-2690 v3 (Haswell) コアを搭載しています。これは、私たちが使用した CPU ベースの VM と同等の価格ですが、CPU と RAM のリソースを GPU と交換したような構成となっています。この事は、NAMD の CUDA バージョンに CPU のボトルネックがまだある場合、パフォーマンスを妨げる可能性がある事を意味します。
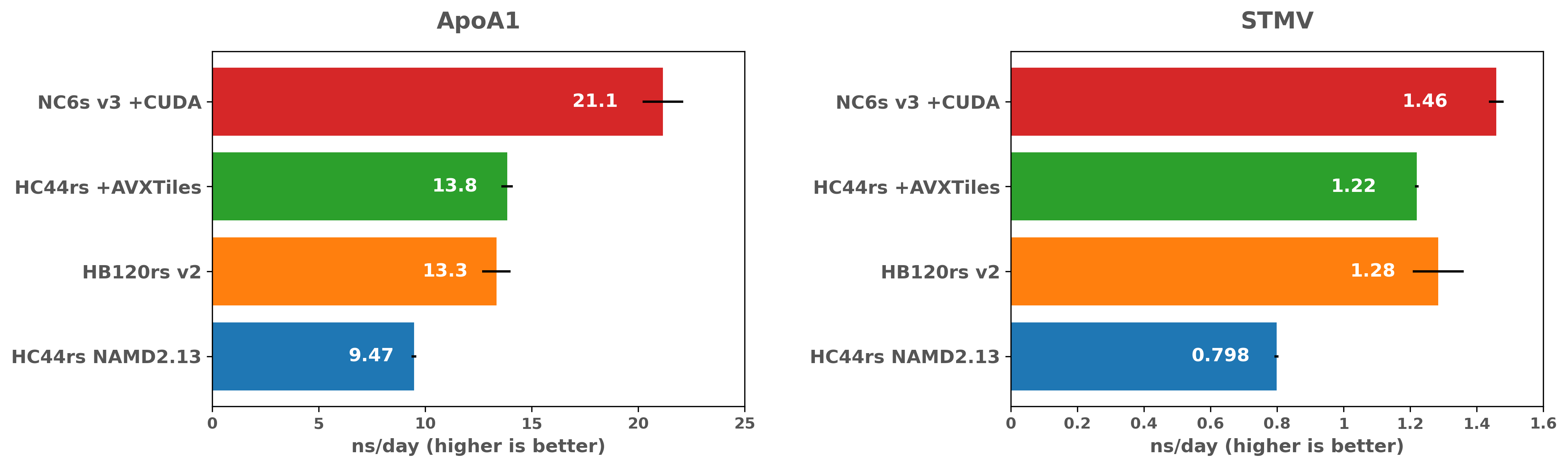
NAMD シミュレーションパフォーマンスの比較(Intel 対 AMD)
NAMD シミュレーション費用対効果の比較(Intel 対 AMD)
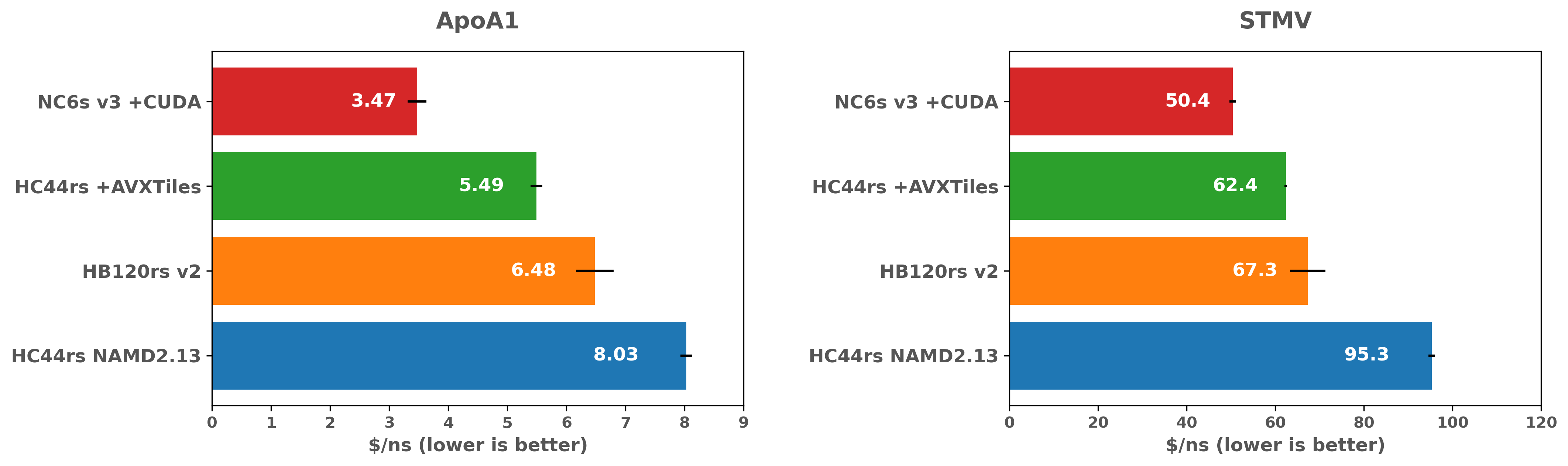
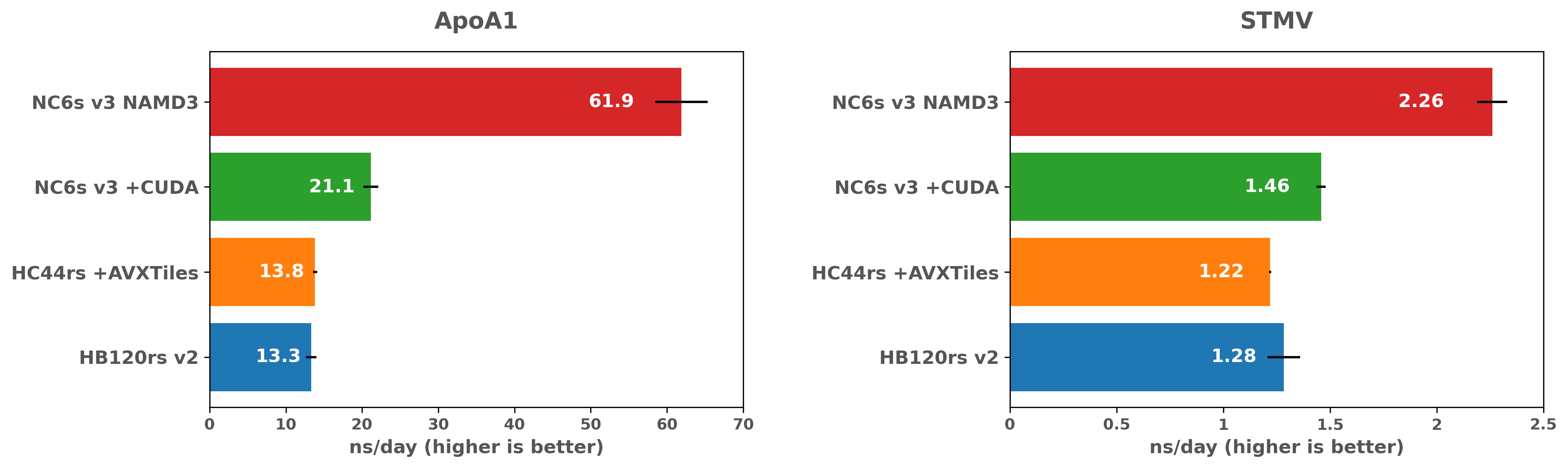
最新の最適化を使用しても、GPU の NAMD は CPU の場合よりも大幅に高速であり、コスト効率が高い事がわかります。 AVX の最適化と同様に、GPU を使った場合のパフォーマンス上の利点は、STMV ベンチマークが大きいほど大幅に低くなることもわかります。 これは、より大きな計算が、GPU を搭載した VM で CPU バウンドまたはメモリ帯域幅バウンドのいずれかであることを示唆しています。 STMV ベンチマークは、多くの NAMD シミュレーションと比較して小規模であるため、より大きなシミュレーションを行った場合について、さらに検討することは非常に役立ちます。これにより、さまざまな規模でのパフォーマンスまたはソリューションのコストに関して、どのようなハードウェアが良いのかが理解できます。
将来を見据えて、NAMD バージョン 3 用に開発されている GPU パフォーマンスの改善点をざっと見てみる価値があります。これらの改善は、残りのすべての計算を GPU に移植することを目的としており、暫定的なベンチマークでは、現在のバージョンの最大3倍のパフォーマンス改善を示しています。(以下)
NAMD3 シミュレーションパフォーマンスの比較(Intel 対 AMD)
クラウド HPC 移行サービス
nAG は クラウド HPC 移行サービス と HPC コンサルティング を提供しており、組織がクラウドと HPC のために数値計算アプリケーションを最適化するのを支援します。HPC に関するベンダーにとらわれない公平なアドバイスと nAG がクラウドへの移行をどのように支援できるかについては、HPC とクラウドのコンサルティングとサービスをご覧ください。