
原文:Cost of Solution for Cloud HPC Published 30/07/2020 By Branden Moore
クラウド HPC ソリューションコスト(nAG 技術者ブログ記事)
先日、HPC 専門家協会の方に、仮想的なクラウド HPC の移行と、その特定の HPC ワークロードに対して「最高」のクラウドリソースをどのように選択していくかについてお話をさせていただきました。この講演では、「ソリューションのコスト」という概念について、いくつかの良い議論を呼んでいます。この一連のブログ記事では、私の同僚と私はこの概念の様々な側面を探り、クラウド HPC の選択を導くためにこの指標をどのように使用するのがベストなのかを探っていきたいと思います。
「ソリューションのコスト」は、ワークロードを実行することで発生するクラウドのコストの合計と定義します。コンピューティングとストレージの 1 時間あたりの料金と、それらのリソースがプロビジョニングされている時間を組み合わせ、データ転送や他のクラウドサービスの利用など、その他の関連コストを混ぜ合わせると、HPC ワークロードを実行するために必要な総コストが得られます。本記事の議論では、入力や結果の長期保存などのコストは含まないことにします。TCO(Total Cost of Ownership)を計算する際に考慮すべき重要なコストですが、これらのコストは HPC ワークロードの実行方法とは無関係である傾向があります。
これを HPC で一般的に使用されている他の指標と比較してみましょう。
「解決までの時間」 - ワークロードが完了するまでにどれくらいの時間がかかるかを示す指標。 これは HPC 最適化の典型的な推進要因であり、「ソリューションコスト」の計算に決定的な要素となります。アプリケーションの実行に時間がかかるほど、ワークロードのコストは高くなります。 "Total Cost of Ownership" (TCO) - この指標は、HPC リソースを「所有」し、運用するためのコストを反映しています。 ハードウェアの購入価格だけでなく、運用、メンテナンス、電力、冷却などのコストも含まれます。従来のオンプレミス環境では、ワークロードの「ソリューションコスト」を計算する方法として、TCO を時間ごとのコストに変換し、その時間ごとのコストをワークロードで使用されているリソースの割合で日割り計算する方法があります。
ソリューションコストを考慮すべき理由
ワークロードを実行するためのコスト(言い換えれば問題を解決するためのコスト)は考慮して当たり前のことのように思えます。 しかし、HPC の世界では必ずしも自然にそうなるとは限りません。多くの場合 HPC ユーザーは、HPC プロバイダーがハードウェアの調達や、運用、保守のためにかけたコストを知ることができません。場合によっては、ユーザーやプロジェクトが CPU 時間あたりの価格を請求されることもあるかもしれませんが、多くの組織では、ユーザーはそれらのコストを直接目にすることはなく、価格について考える動機付けがほとんどありません。
クラウドに移行すると、リソースの時間当たりのコストをリソースのユーザーに直接関連付けることがより自然になるため、このような状況が変化することがよくあります。クラウド HPC ユーザーは、ワークロードの 1 時間あたりのコストに定期的にさらされており、1 時間あたりの料金が安いリソースを選択するように迫られる場合があります。
さらに、ほとんどの HPC センターでは、クラウドプロバイダーが提供できるほど豊富なHPCリソースが用意されていません。多くの場合、ユーザーが利用できるストレージソリューションは 1 つだけで、プロセッサも 1 世代か 2 世代分しか用意がないかもしれません。また GPU などのアクセラレータも利用できないかもしれません。そのため、HPC センターの利用料金が時間単位で利用できるようになったとしても、選択肢が少なく、ワークロードに最適なシステム構成を選択することはほとんど不可能です。
最後に、クラウドリソースは時間単位(場合によっては秒単位)で課金されており、誰が見てもわかるように価格が記載されているという事実にたどり着きます。コスト削減対策として、最も安価な $/時間 の選択肢に惹かれてしまいがちです。しかし、以降の議論で提示するように、最初は安く見えるかもしれないこの選択肢が、最終的にはコストが高くなってしまうパスにつながる可能性があります。
ソリューションコストを最適化
私が HPC 専門家協会のために行った講演では、オイル&ガスのワークロードについて議論していました。このワークロードは、内部で開発された RTM(Reverse-Time-Migration)ベンチマークを表しています。このワークロードは、多くの独立した問題(数万)で構成されており、個々の問題には非常に多くの計算量と一時的なストレージ(約 50TB)が必要となります。私たちは、この計算を行うことができる様々な方法を調べ、Amazon のクラウド上に「オンプレミス」システムを複製しようとする、ストレートな「リフト&シフト」実装と比較しました。
後日のブログ記事では、これらの計算がどのように行われたか、そしてどのようにして結果としての価格を導き出したかについて詳しく説明しますが、今のところは、私たちが考え出したソリューションのいくつかと、それらが仮想的なワークロードを実行するためのコストにどのように影響するかを探ってみましょう。
アプローチ1 - オリジナルのオンプレミスソリューションの複製
私たちの「リフト&シフト」アーキテクチャは、Amazon の FSx for Luster マネージドサービスソリューションを使用して、高性能ストレージ用の 8PB Luster ファイルシステムを提供します。480 個の c5n.18xlarge インスタンスをプロビジョニングして、オンプレミスノードを複製しました。 これらは AWS の主力の HPC インスタンスであり、デュアルソケット Skylake Xeon と AWS の EFA と呼ばれる HPC ネットワークを組み合わせています。 個々のワークロードの問題、つまり「ショット」はそれぞれ 4 つのインスタンスにわたって MPI ジョブとして実行されるため、一度に 120 のショットを再構築できます。 10,000 の個別ショットを実行するには、このクラスターは約 47 日かかります各ショットの再構築には約 13.5 時間かかり、同時に 120 ショットを再構築できます。費用はわずか 400 万米ドル(オンデマンドを使用) です。
図1 「リフト&シフト」アーキテクチャ
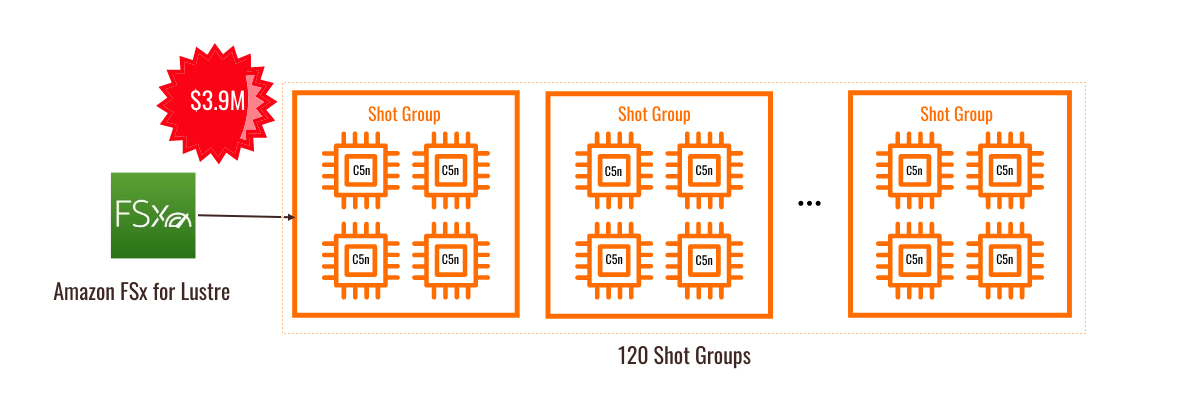
このアプリケーションの価格を左右する要因の 1 つは、大規模な共有ファイルシステムです。このアプリケーションでは、主に一時的なスクラッチスペースとして使用されています。各ショットには約 50TB のスクラッチスペースが必要です。各「ショット」は計算に依存しない問題なので、スクラッチスペースを共有ファイルシステムから取得する必要はありません。以前は、オンプレミスのシステムでは、それだけのデータを保存できる唯一の場所であったため、この方法で行われていました。
アプローチ2 - 大容量のローカルストレージを持つファットVMへの切り替え(1 ショットに 1 インスタンス)
AWS には「i3en」と呼ばれるストレージ指向の VM インスタンスタイプがある。「i3en.24xlarge」は、96vCPU と 768GB の RAM を搭載しているだけでなく、インスタンスに直接接続された 7.5TB の NVMeドライブを 8 台搭載しています。この 60TB の高速ローカルストレージは、50TB のスクラッチデータには十分すぎるほどです。1 つのインスタンスで利用可能なリソースだけを使用して、1 つのショットを再構築することが可能になりました。このようなインスタンスをその時点で利用可能な数だけ起動して、処理する必要のある 10,000 ショットを処理することができます。これにより、大規模な共有ファイルシステムを必要とせず、HPC に特化したネットワークにも対応できます。オンデマンドの価格設定では、私たちの作業量はわずか 164 万ドルで、「リフト&シフト」の例よりも大幅に節約できます。各ショットの再構築には約 15 時間かかります。120 ショットの再構築を同時に行う場合、完了までに 52 日かかります。より多くのショットを同時に再構築することで、これをスピードアップすることができます(インスタンスの利用可能性に応じて)。
図2 i3en.24xlarge を使用した、ショットごとに 1 つのインスタンス
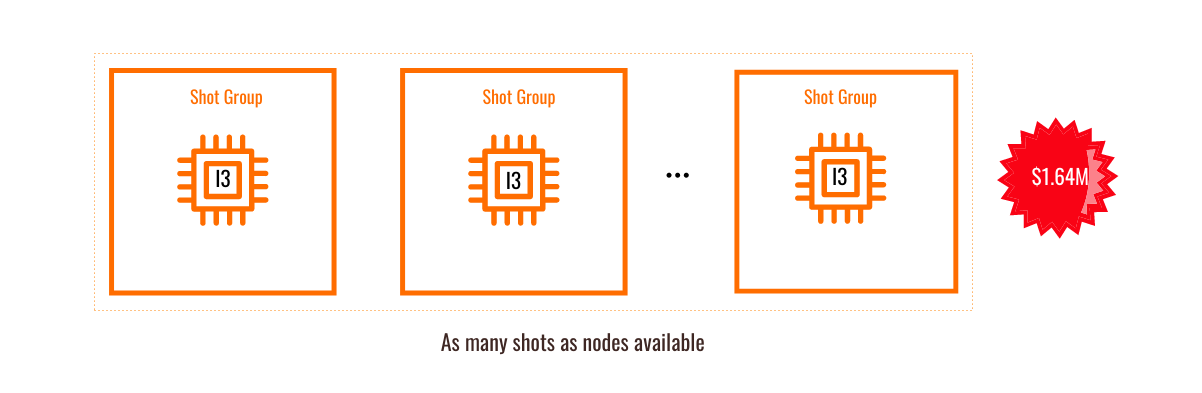
ショットごとに 1 つのインスタンスを使用することには、いくつかの欠点があります。 各インスタンスには 96 個の vCPU しかありませんでしたが、以前は 288 個の vCPU(4 つのインスタンス x 72 個の vCPU /インスタンス)を使用していました。 コストは大幅に削減されましたが、計算に多くの時間を費やしています。パフォーマンスが向上するためのボトルネックとして、コンピューティングが I/O に取って代わりました。これにより、リソースを追加して、使用可能なコンピューティングの量を増やすことが可能となりました。
アプローチ3 - リソースを追加してコストを下げる
AWS は最近、64 コアの ARM ベースの CPU である Graviton 2 プロセッサを発表しました。これらのプロセッサは、HPC タスクの実行能力が高く、他の x86 プロセッサと比較して価格が安くなっています。先ほどの例の i3en インスタンスをショット単位の NFS ファイルシステムとして動作させ、ARM プロセッサのインスタンスを組み合わせることで、利用可能な計算量を増やすことができます。
図3 ショットごとのNFSとArmプロセッサを組み合わせる
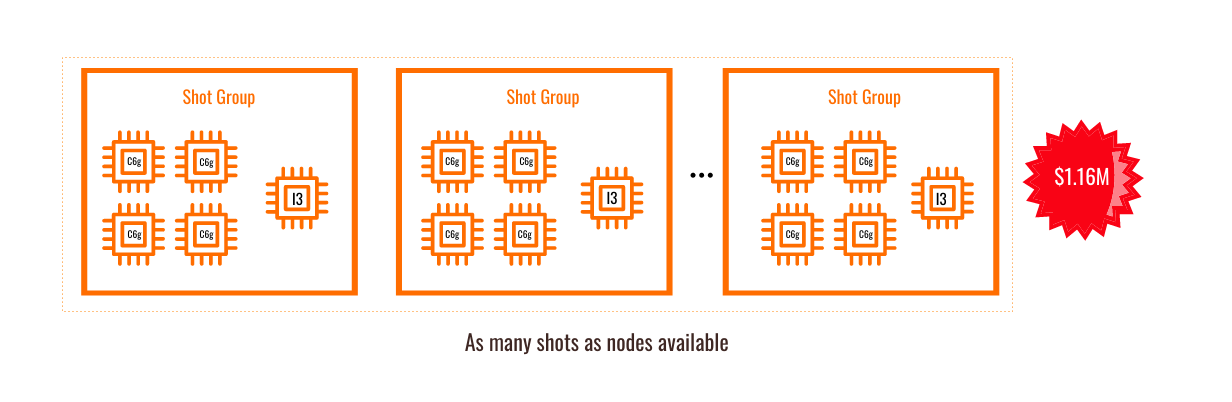
図3に示すように、各ショットは現在 4 つの ARM ベースの C6g インスタンスと I3en インスタンスのセットを使用しており、計算用のスクラッチスペースストレージを提供していることがわかります。ワークロードのボトルネックに対処するために計算機能を追加したため、ランタイムは劇的に短縮されました(ショットごとの再構成時間は6時間に短縮され、120 ショットを同時に実行した場合、ジョブ全体を 21 日で終了させることができます)。クラウドリソースを追加し、トータルコストを削減しました。
まとめ
このシリーズのブログ記事では、クラウド上の HPC ワークロードの「ソリューションのコスト」を理解し、計算し、最適化するためのさまざまな要因についてお話しします。 今日は、「ソリューションのコスト」という指標を紹介し、この指標を最適化することで、リソースの追加(時間当たりの使用量の増加)がコスト削減につながることがあるなど、直感的ではない状況につながることを示す簡単な例を紹介しました。
ソリューションコストの指標について、また nAG がどのようにしてお客様の組織がクラウドHPCを最も効率的に利用するためのお手伝いをすることができるかについては、弊社の クラウド HPC 移行サービス をご参照下さい。