
CSE Team, nAG Ltd.
Naveed Durrani, University of Sheffield
イントロダクション
nAG CSE(Computational Science and Engineering)チームの活動の一つとして、HRCToRサービスを利用する研究者らへの計算サポートを提供しており、コード性能最適化を短期的にサポートすることにより、ユーザにマシン性能を最大限に活用可能なような助力を提供しています。本ケーススタディーは、シェフィールド大学機械工学部グループ(http://www.shef.ac.uk/mecheng/staff/qin.html)が開発した計算流体力学(CFD)コードであるDG-DES (Dynamic Grid - Detached Eddy Simulation)の性能向上について記述しています。
このグループのメンバー数人がnAG HECToRトレーニングに参加し、CSEチームは彼らにHECToRへのアクセス方法を伝えDG-DESの移植をサポートしました。移植後に、ユーザはコードがクラッシュすることが解り、デバッグを依頼した。CSEチームはコード内の2つのマイナーエラー(配列宣言ミスとゼロ割)を修正しました。コードは正常に実行可能となり、次は256PEを用いて12時間の実行を念頭にした性能最適化であったため、短期の最適化サポートが実施されました。
DG-DES
DG-DESは、3次元空間領域内の時間に依存した乱流モデルのFortran90/MPI並列コードです。グラフ分割ソフトウェアMetis(http://glaros.dtc.umn.edu/gkhome/metis/metis/overview)により有限要素空間領域が分割され、時間ステップにはマルチステージRunge-Kutta法を用います。DESはレイノルズ平均Navier-Stokes(RANS)とLarge-Eddyシミュレーション(LES)という2つの数値計算手法の強みを併せたハイブリッド数値計算アプローチです。DG-DESは、流体の振る舞いに従ってメッシュ点の位置が時間により変化する動的グリッドも用いることが出来ます。
ソースコードと共に提供されたテストケースは、比較的に小さな35,000ノードの固定メッシュです;実際の運用では1.5百万ノード以上が用いられます。

図1 : レイノルズ数3.6×10?6でのシリンダー周りの異な翼幅位置での渦度のプロット
通信コードの最適化
HECToRへの移植に際しては、Makefileにおいて単純に古いコンパイラコマンドをftnコマンドへ置換、または追加オプションなしにPGIコンパイラが用いられていました。よって最初の実験としては、どちらのコンパイラを如何なる最適化オプションを用いて利用すべきかを見つける事でした。
図2は、ベンダー推奨オプションと共に、PGIおよびPathscale(3.0)コンパイラを用いたTDSシステムで実施したテスト結果を示しています。図2は、Pathscale(3.0)コンパイラが性能が最も良いことを示しています:PGI(7.0.4)コンパイラを最適化オプション無で用いた場合と比較して(最上行、つまり元のコードがコンパイルされた方法)、Pathscale(3.0)コンパイラでは-Ofastオプションを用いるとかなり高速です。
図2のテストはデュアルコアモードです:図3の結果により、単一コアでDG-DESを実行するメリットは無いことが明らかです。
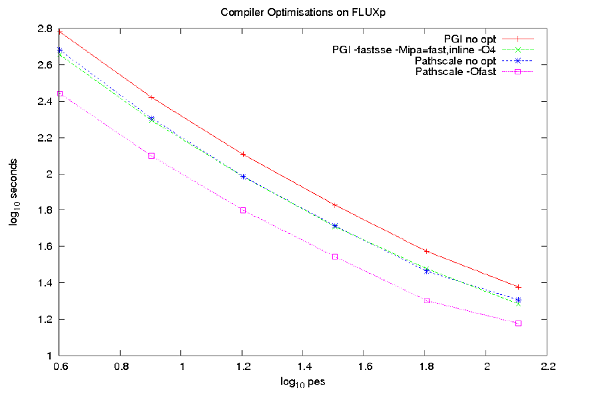
図2 : 最適化オプション有り/無し、PGI/Pathscaleコンパイラ、および4,8,16,32,64,128PEにおけるDG-DESの性能。
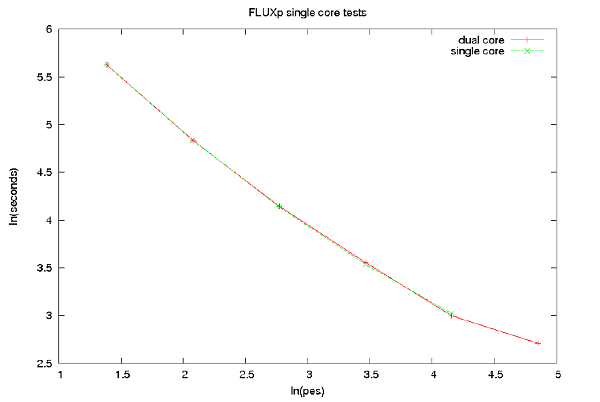
図3 : シングルおよびデュアルコア・モードにおけるDG-DESの性能。
ソースコードを見るとDG-DESはメインループ中に多くのサブルーチンと関数の呼出しがあり、インライン展開が有効であることが示唆されます。Pathscaleコンパイラの-Ofastオプションは、-O3 -ipa -OPT:ro=2:Olimit=0:div split=ON:alias=typed -fno-math-errno -ffast-mathと展開されますが、インライン展開は手続き間解析オプション-ipaの一部であり、インライン展開に関するより強力なオプションが存在します。次のオプションを-Ofastに追加して試しました:-IPA:plimit=20000:callee limit=20000 -INLINE:aggressive=on。オプション-INLINE:list=onを用いると、ループ内で呼ばれるより大きなサブルーチンの多くがインライン展開されますが、図4が示すように性能には影響はなく、インライン展開オプションは-ipaで十分であることが解ります。
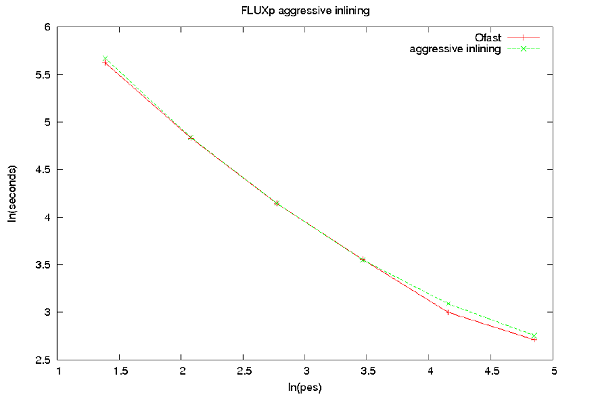
図4 : アグレッシブ・インライン展開オプションにおけるDG-DESの性能。
プロファイリング
Cray PATプロファイルは、サブルーチンresidual_mpiおよびその下位ルーチンが実行時間の75%を占めていることを示しています。しかしながら、-ipaオプションはCray PATの-gオプションと両立せず、最適化前後のコード利用率の比較といったテストには利用できません。また、Cray PATはトレース情報を得る場合に、自動トレース解析(APA)オプションを用いた場合においても(APAより少ないルーチンを対象にした場合においても)極端に性能が落ちます。よってMPI_WTIME関数を用いた時間計測モジュールをコードへ組み込みました。
簡単な最適化後の性能
サブルーチンresidual_mpiはメイン計算ループ内で呼び出されますが、繰り返し毎に複数回他のルーチンを呼び出し、小規模テスト実行においても数百万回の呼出しを行います。最も時間の掛かっている2つのルーチンmuおよびsonicは一行の関数なので、簡単に手動でインライン展開が可能です。これらルーチン内の計算における2つのオペランドは定数ですが、定数としての宣言はされていませんでした;これを修正すると、コンパイラは計算当りのロードを2個減らすことが出来るため、-Ofastオプションのみの場合と比較して全体で10%高速化しました(以下本レポートを通して、高速化%は、100×(元の実行時間−新しい実行時間)÷元の実行時間で計算されるとします)。
また、定数teqs(乱流モデルのフラグ)が変数として宣言されているため、条件文if(teqs!=0)が何度も実行されていました。これをparameter宣言に変更したところ、コンパイラはこの条件分を削除出来て、さらに全体で5%高速化しました。
ユーザーは'DES'に関してのみ興味があるので、以下の繰り返し実行されるcase文は不要です。
select case(TRIM(tmodel))
case('S-A', 'DES')
tFV = Vn*tFV
tFV = tFV*face(id)%VOL
case('k-w')
...
end select
このブロックをDESケースについて条件文なしに置き換えると、さらに全体で25%高速化しました。この変更はプリプロセッサー・マクロを利用すれば、元のコードへ戻すことも容易です。図5はこれら3つの変更により達成された性能向上を示しています。
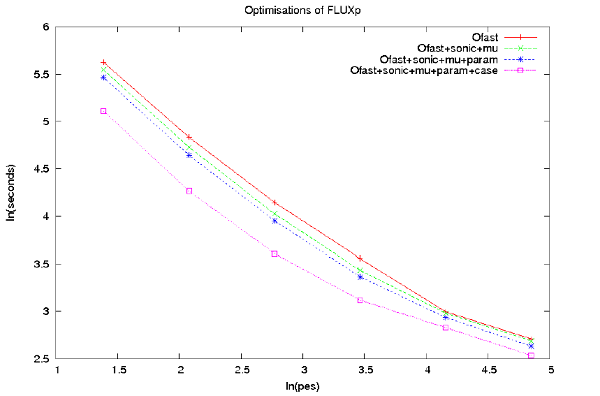
図5 : -Ofastオプション、muおよびsonicルーチンインライン展開、teqsをparameter宣言、case文削除の各修正後におけるDG-DESの性能。
スケーリング性能
図5の性能曲線は、このテストケースではDG-DESはスケール性能があまり良くないことが示唆されています。これは図6に示す、HECToR上の512PEまでの性能測定結果から確認できます。図7に示したコードに含まれる重要な部分の計測時間から、64PEを超えた場合の性能劣化の原因が見て取れます:時間ステップループのブロードキャストが負荷分散を生じています。これは領域分割が比較的小さく、多くのプロセッサーでイレギュラーなメッシュが存在することから生じているためと考えられます; より大きな実用的メッシュで同じコードを実行した場合には、ユーザーが意図する256PEまで問題は生じないと考えられます。
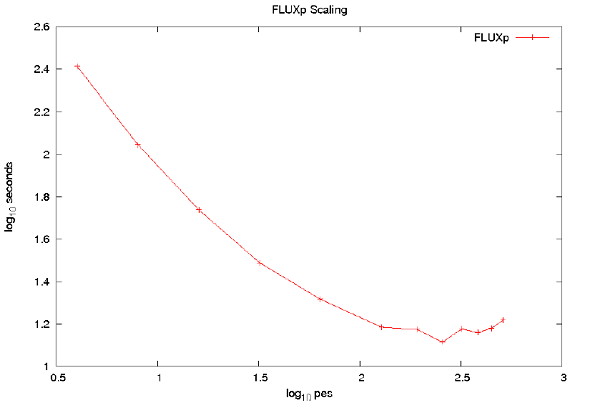
図6 : テストケースにおけるDG-DESの性能は512PEまでスケールしない。
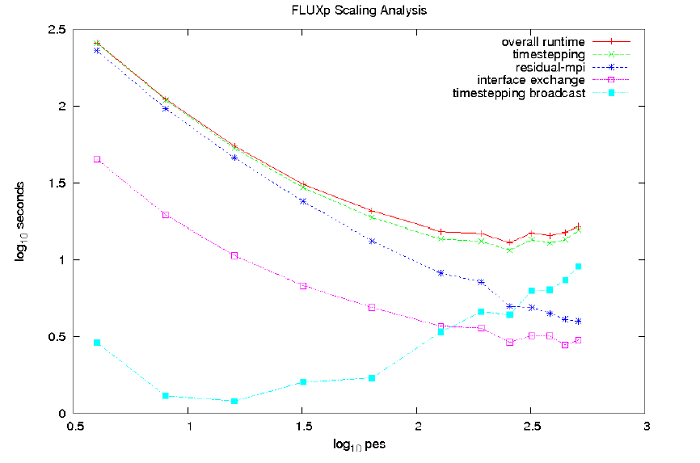
図7 : コードの主要部分の計測時間は、主に時間ステップループのブロードキャストが性能劣化の原因であることを示している。
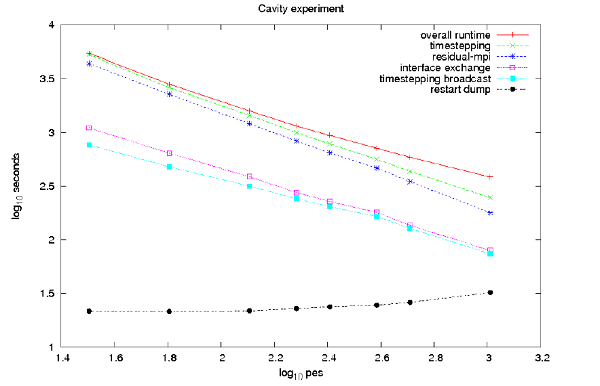
図8 : 1.8百万ノードの実用メッシュを用いた場合、図7と同じコード主要部の計測時間は、DG-DESが要求通りの256PEまでスケールすることを示している。
結論
図9は、CSEによる最適化の前後のコード性能を示しています。コンパイラの変更、最適化オプションおよび冗長なコードの削除等の簡単な最適化により、70%の性能向上が示されています。
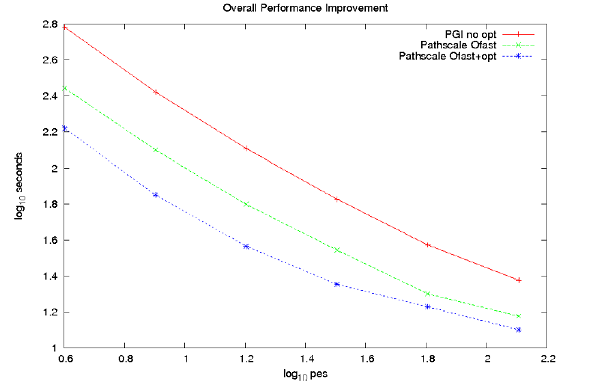
図9 : DG-DESの全体性能の改善: CESによる最適化以前では、このコードは最適化オプション無でPGIlコンパイラを用いてコンパイルされていました; -Ofastオプションを用いたPathscaleコンパイラに切り替えて、簡単なコード最適化を行った後には、70%高速化しました。
nAG CSEチームはユーザーに対して、HECToRアクセス方法、コードの移植とデバッグ、指定された実行条件におけるコード・プロファイリングと最適化、および作業方針に助言を行いました。将来的な性能モニターのための時間計測ルーチンも提供しました。例えば以下のようにコード主要部の累積時間が出力されます。特に図7で問題となったブロードキャストでは、もし最大値と最小値の差が大きければ、問題は負荷分散であることが解ります。
-----------------------------
Overall run time
max time = 70.801842
min time = 70.624277
-----------------------------
-Cumulative time for global loop
-max time = 69.031489
-min time = 68.958275
-----------------------------
---bcast with slamon
---max time = 2.804001
---min time = 0.064152
-----------------------------
このケーススタディーは、可能な限りコンパイラーにコードを最適化させることが得策である事を示しています。また、小さな冗長なコードを削除することで如何に大きな性能向上が得られるかも示されました。つまり常に大きな変更が必要とは限りません。こうした変更はユーザーコードの柔軟性を無くしてしまいますが、実用的には価値があります。また、ベンチマークに用いるテストケースにも注意を払うべきです。望む大規模ケースまで、その変更がスケールするかをチェックすることが重要です。