
Asimina Maniopoulou, Chris Armstrong,
CSE Team, nAG Ltd.
1 僀儞僩儘僟僋僔儑儞
杮挷嵏偼丄僋傾僢僪僐傾AMD Opteron僾儘僙僢僒乕偱峔惉偝傟傞僼僃乕僘2a(IQ僔僗僥儉偼婔傜偐堎側傞)偺儊僀儞僔僗僥儉偲偟偰峔抸偝傟傞HRCToR TDS(Test and Development System)忋偱幚巤偝傟傑偟偨丅偙偺僔僗僥儉偼64僲乕僪峔惉偱丄憤僐傾悢偼256偱偡丅
2 尰忬偺CASTEP 4.4偺儀儞僠儅乕僋
CASTEP 4.4偼HECToR(僨儏傾儖僐傾僲乕僪)偍傛傃HECToR TDS(僋傾僢僪僐傾)忋偱Pathscale(3.2)僐儞僷僀儔乕偱僐儞僷僀儖偝傟傑偟偨丅僐儞僷僀儖僼儔僌偼椉幰偲傕偵丄CASTEP dCSE Project report[1]偱婰弎偝傟偰偄傞傕偺傪慖傃傑偟偨丅偦偺僼儔僌偼師偺傕偺偱偡丗
-O3 -OPT:Ofast -OPT:recip=ON -OPT:malloc_algorithm=1 -inline -INLINE:preempt=ON
偝傜偵丄僋傾僢僪僐傾愱梡偺嵟揔壔僼儔僌(Pathscale偵偍偄偰偼丄-march=barcelona)偍傛傃僋傾僢僪僐傾偵嵟揔壔偝傟偨Cray libsci儔僀僽儔儕乕傊偺儕儞僋(昁梫偵墳偠偰)傪捛壛偡傞偨傔偺丄怴偟偄儌僕儏乕儖"xtpe-quadcore"傪僐儞僷僀儖帪偵儘乕僪偟傑偡丅
僋傾僢僪僐傾僔僗僥儉忋偱丄CASTEP偼慡偰偺SCF寁嶼偺屻偵僙僌儊儞僥乕僔儑儞僼僅乕儖僩偱廔椆偟偰偟傑偆偙偲偑妋擣偝傟傑偟偨丅僼僅乕儖偲偟偨儖乕僠儞偼丄Fundamental/basis.F90僼傽僀儖撪偺basis sum recip grid偱偟偨丅栤戣偼偙偺儖乕僠儞偺攝楍"grid"偵娭學偟偰偄傞偙偲偑敾柧偟傑偟偨丅偙偺僼傽僀儖偺傒傪傛傝掅偄儗儀儖偺嵟揔壔儗儀儖偵偡傞偙偲偱丄栤戣偼夞旔偝傟傑偟偨丅-O2偱傕僼僅乕儖僩偡傞偨傔丄嵟揔壔僼儔僌偼埲壓偺傕偺傪梡偄傑偟偨丗
-O1 -OPT:Ofast -OPT:recip=ON -OPT:malloc_algorithm=1 -inline -INLINE:preempt=ON
偙偺僆僾僔儑儞偵偟偰傕僐乕僪偺惈擻偼慡偔摨摍偱偡丅堘偆傗傝曽偲偟偰丄basis.F90僼傽僀儖撪偵嵟揔壔巜帵峴傪憓擖偡傟偽丄慡僼傽僀儖偱偼側偔丄栤戣偺偁傞娭悢偺傒偵掅偄嵟揔壔儗儀儖偑揔梡偝傟傑偡丅
昞1-3偼僨儏傾儖偍傛傃僋傾僢僪僐傾忋偱偺3偮偺儀儞僠儅乕僋幚峴寢壥傪帵偟偰偄傑偡(儀儞僠儅乕僋偺徻嵶偼暥專[1]傪嶲徠偟偰偔偩偝偄)丅昞拞偺寁應帩娫偼丄懳墳偡傞儀儞僠儅乕僋柤.castep弌椡僼傽僀儖撪偵婰榐偝傟偨丄嵟屻偺SCF僒僀僋儖偺帪娫[昩]偱偡丅懢帤偱嫮挷偟偨抣偼丄僋傾僢僪僐傾偑僨儏傾儖僐傾傛傝抶偄働乕僗偱偡丅
| nproc | dualcore | quadcore | speedup |
| 8 | 398.31 | 327.16 | 1.22 |
| 16 | 231.60 | 218.77 | 1.06 |
| 32 | 174.02 | 218.91 | 0.79 |
| 64 | 194.57 | 301.10 | 0.65 |
2.1 儀儞僠儅乕僋丂al1x1
32媦傃64僐傾偵偍偄偰惈擻偑椙偔偁傝傑偣傫偑丄castep.param僼傽僀儖撪偺儅儖僠僐傾丒僆僾僔儑儞巜掕偡傞偲傛傝椙偄惈擻偲側傝傑偡(僙僋僔儑儞5.2偺昞8傪偛棗偔偩偝偄)丅偙偺儀儞僠儅乕僋偱偼惈擻岦忋偼彫偝偄傕偺偱偟偨丅偙偺寢壥偐傜丄al1x1偼働乕僗偲偟偰彫偝偔丄16proc埲忋偱偺惈擻楎壔偼傛傝彫偝側僒僀僘偺応崌傛傝傕捠怣偑巟攝偟偰偄傞偙偲偑尨場偱偁傝丄僋傾僢僪僐傾偵偍偄偰奺僲乕僪撪偱偺撪晹揑側捠怣楬偵傛傝懡偔偺嫞崌偑懚嵼偡傞偙偲偑尒偰庢傟傑偡(偙偺栤戣偵娭楢偡傞嵟揔壔偼僙僋僔儑儞5傪嶲徠偟偰偄偔偩偝偄)丅
2.2 儀儞僠儅乕僋丂al3x3
| nproc | dualcore | quadcore | speedup |
| 32 | 5948 | 4759.03 | 1.25 |
| 64 | 3121.02 | 2500.48 | 1.25 |
| 128 | 1915.14 | 1696.30 | 1.13 |
| 256 | 1464.74 | 1526.11 | 0.96 |
昞2偵偍偄偰丄32媦傃64僐傾偱偺帪娫偼1.25攞偺崅懍壔傪帵偟偰偄傑偡丅256僐傾偱偼丄屆偄僨儏傾儖僐傾偵斾傋僗働乕儕儞僌惈擻偑0.96傊丄al1x1偲摨條偵楎壔偟偰偄傑偡丅
2.3 儀儞僠儅乕僋丂TiN-mp
| nproc | dualcore | quadcore | speedup |
| 64 | 785.09(42) | 654.33(42) | 1.20 |
| 128 | 572.12(39) | 422.02(39) | 1.35 |
| 256 | 370.71(42) | 404.35(42) | 0.92 |
偙偙偱偼64僐傾偱1.2攞丄128僐傾偱1.35攞偵崅懍壔偟偰偄傞丅256僐傾偱偺惈擻埆壔偼柧傜偐偱偡丅梫偡傞偵丄戝婯柾儀儞僠儅乕僋偱偼1.2~1.35攞偵崅懍壔偟偰偄傑偡丅CASTEP偼僨儏傾儖僐傾僔僗僥儉傛傝傕僋傾僢僪僐傾僔僗僥儉偱丄傑偨戝婯柾働乕僗(al3x3偍傛傃TiN-mp)偵偍偄偰128僐傾埲忋偱惈擻楎壔偟偰偍傝丄彫婯柾働乕僗(al1x1)偱偼32僐傾偵偍偄偰偝偊栤戣偑尠嵼壔偟偰偄傑偡丅偙偺僗働乕儖栤戣偼僙僋僔儑儞5偱埖偄傑偡丅
3 僋傾僢僪僐傾僔僗僥儉偵偍偗傞CASTEP偺僠儏乕僯儞僌
3.1 僐儞僷僀儔乕偵傛傞嵟揔壔
條乆側僐儞僷僀儖僼儔僌傪帋偟傑偟偨偑丄偙傟埲忋偺嵟揔壔偵偼帄傝傑偣傫偱偟偨丅椺偊偽埲壓偺傛偆側僼儔僌偱偡丗
-ipa, -LNO:blocking=ON, -LNO:prefetch=3, -LNO:prefetch_ahead=3, -LNO:prefetch_ahead=4, -LNO:full_unroll_outer=ON, -LNO:full_unroll_size=10000, -LNO:fu=12, -OPT:unroll_times_max=16, -LNO:fission=2
僼儔僌-LNO:simd2偵傛傞傛傝傾僌儗僢僔僽側儀僋僩儖壔傪帋傒傑偟偨偑丄僐儞僷僀儔偺僼僅乕儖僩偵傛傝幐攕偟偰偄傑偡丅偙偺僼儔僌偼嵟揔壔儗儀儖傪-O2傊尭傜偟偰梡偄傞偙偲偑弌棃傑偡偑丄偙傟傜偺慻崌偣偼惈擻傪楎壔偝偣傑偡丅
3.2 娐嫬曄悢偵傛傞嵟揔壔
Cray XT僔僗僥儉偺huge page file僒億乕僩傪娷傓條乆側MPICH娐嫬曄悢傪帋偟傑偟偨丅偙傟傜偺拞偱丄MPICH_RANK_REORDER_METHOD偑CASTEP偵偼桳岠偱偡丅僗働乕儕儞僌惈擻偑埆壔偟偨応崌偵(椺偊偽al3x3傗TiN-mp儀儞僠儅乕僋偱256僐傾傪棙梡偡傞応崌)丄MPICH_ALLTOALLVW_RECVWIN=1偵傛傝巜掕偝傟偨ALLTOALLV傾儖僑儕僘儉傪曄峏偡傞偙偲傕桳岠偱偡丅
3.2.1 MPICH_RANK_REORDER_METHOD偵傛傞嵟揔壔
僨僼僅儖僩偺MPI儔儞僋攝抲偼SMP僗僞僀儖偱偡丅暿偺僗僉乕儉傪幚尡偟偨偲偙傠丄戝婯柾働乕僗偱偼folded-rank攝抲偑僨僼僅儖僩偵斾傋偰1.15攞崅懍壔偟傑偟偨丅folded-rank攝抲傪巜掕偡傞偲丄儔儞僋偼偦偺儕僗僩拞偺師偺僲乕僪偵抲偐傟丄堦扷奺僲乕僪偑梡偄傜傟傟偽丄儔儞僋偼偦偺嵟屻偺僲乕僪偐傜嵟弶偺曽傊愜傝曉偝傟傑偡丅埲壓偺寢壥偐傜丄偙偺娐嫬曄悢偼忢偵愝掕偝傟傞傋偒偱偟傚偆丅
| nproc | default-smp | folded | speedup |
| 8 | 327.16 | 325.87 | 1.00 |
| 16 | 218.77 | 219.44 | 1.00 |
| 32 | 218.91 | 214.78 | 1.02 |
| 64 | 301.10 | 294.05 | 1.02 |
3.2.2 MPICH_ALLTOALLVW_RECVWIN偵傛傞嵟揔壔
埲壓偺昞偵偍偄偰丄MPICH_RANK_REORDER=2偍傛傃MPICH_ALLTOALLVW_RECVWIN=1傪巜掕偟偨嵺偺僋傾僢僪僐傾偱偺惈擻傪斾妑偟偰偄傑偡丅
| nproc | default-smp | folded | speedup |
| 32 | 4759.03 | 4539.56 | 1.05 |
| 64 | 2500.48 | 2402 | 1.04 |
| 128 | 1696.30 | 1620.38 | 1.05 |
| 256 | 1526.11 | 1405.14 | 1.09 |
| nproc | default-smp | folded | speedup |
| 64 | 654.33(42) | 606.37(42) | 1.08 |
| 128 | 422.02 (39) | 376.66(39) | 1.12 |
| 256 | 404.35 (42) | 350.48(42) | 1.15 |
僨僼僅儖僩偺SMP儔儞僋傪梡偄偰MPICH_ALLTOALLVW_RECVWIN=1傪巜掕偟偨働乕僗偼岠壥偑戝偒偄偱偡偑丄椉曽偺娐嫬曄悢傪巜掕偟偨応崌偑嵟傕椙偄惈擻偑摼傜傟傑偟偨丅
| benchmark | nprocs | default dualcore | default quadcore | folded | folded+RECVWIN |
| al3x3 | 256 | 1464.74 | 1526.11 | 1405.14 | 1344.12 |
| TiN-mp | 256 | 370.71 | 404.35 | 350.48 | 344.03 |
MPICH_ALLTOALLVW_RECVWIN偍傛傃堎側傞僾儘僙僢僒乕悢偵懳偡傞SEND娐嫬曄悢偵懳偟偰幚尡傪峴偆偙偲偑悇彠偝傟傑偡丅
4 僾儘僼傽僀儕儞僌
偙偙偱丄TiN-mp儀儞僠儅乕僋偵傛傞僋傾僢僪僐傾僔僗僥儉忋偺僐乕僪偺僾儘僼傽僀儖忣曬傪嵦庢偟丄庡偵儀僋僩儖壔偲僋傾僢僪僐傾僔僗僥儉偵偍偄偰嬌傔偰廳梫側僉儍僢僔儏棙梡棪傪媍榑偟傑偡丅
4.1 儐乕僓乕娭悢
64僐傾傪梡偄偰幚峴偟偨嵺偵嵟傕帪娫偺妡偐傞儐乕僓乕娭悢偼埲壓偺捠傝偱偡丗
|| Time% | Time | D1 Cache hit, miss ratio | Function || 56.0% | 419.238296 | 94 % | main || 9.7% | 72.656015 | 94 % | POT_NONGAMMA_APPLY_SLICE.in.POT || 6.3% | 46.856810 | 96.6% | COMMS_TRANSPOSE_N.in.COMMS || 3.7% | 27.553444 | 78.9% | WAVE_INITIALISE_SLICE.in.WAVE || 1.4% | 10.700597 | 88.5% | ION_Q_RECIP_INTERPOLATION.in.ION || 1.1% | 8.429017 | 89.6% | ION_APPLY_AND_ADD_YLM.in.ION
僉儍僢僔儏僸僢僩:儈僗斾棪偼懡彮掅偄偙偲偑帵偝傟偰偄傑偡丅傑偨丄娭悢ION_Q_RECIP_INTERPOLATION.in.ION偍傛傃ION_APPLY_AND_ADD_YLM.in.ION偵偍偄偰儀僋僩儖壔偺栤戣傕尒偮偐傝傑偟偨丅Pathscale偺僼儔僌(-FLIST:=on -LNO:simd_verbose)傪梡偄偨僐儞僷僀儖帪偵丄僉儍僢僔儏棙梡棪傗儀僋僩儖壔傪慾奞偡傞旕楢懕側攝楍傾僋僙僗偑懡偔懚嵼偟偰偄傞偙偲偑敾柧偟傑偟偨丅崿崌惛搙墘嶼(攞惛搙暋慺悢偲攞惛搙幚悢)傪梡偄傞懡偔偺売強偱丄僐儞僷僀儔偑儀僋僩儖壔偵幐攕偟偰偄傞偙偲傕傢偐傝傑偟偨丅
4.2 MPI娭悢
4.2.1 64僐傾偺応崌
64僐傾傪梡偄偰TiN-mp儀儞僠儅乕僋傪幚峴偟偨嵺偵丄嵟傕帪娫偺妡偐傞MPI娭悢偑埲壓偺傕偺偱偡丅奺MPI僐儗僋僥傿僽捠怣偺嵺偵偼僶儕傾偑愝掕偝傟丄摨婜偵昁梫側帪娫偑MPI function name (sync)偵婰榐偝傟傑偡丅奺僐儗僋僥傿僽憖嶌偵昁梫側帪娫偼屄暿偵梌偊傜傟傑偡丅
|Time % | Time | Imb. Time | Imb. | Calls |Function | 16.1% | 119.638932 | -- | -- | 285344.2 |MPI ||---------------------------------------------------------------- || 13.9% | 103.655824 | 6.980603 | 6.4% | 207187.5 |mpi_alltoallv_ || 1.1% | 8.160020 | 1.956344 | 19.6% | 622.3 |mpi_recv_ ||================================================================ | 5.2% | 39.001770 | -- | -- | 284091.5 |MPI_SYNC ||---------------------------------------------------------------- || 2.2% | 16.375367 | 4.858887 | 23.2% | 207187.5 |mpi_alltoallv_(sync) || 2.2% | 16.000521 | 4.925778 | 23.9% | 58403.2 |mpi_allreduce_(sync)
4.2.2 256僐傾偺応崌
100.0% | 1161.156466 | -- | -- | 1788338.6 |Total |------------------------------------------------------------------ | 58.8% | 682.655539 | -- | -- | 513017.7 |MPI ||----------------------------------------------------------------- || 54.9% | 636.979240 | 89.855737 | 12.4% | 392235.5 |mpi_alltoallv_ || 2.0% | 23.695335 | 5.885210 | 20.0% | 87424.8 |mpi_allreduce_ || 1.4% | 16.091737 | 1.547607 | 8.8% | 1317.8 |mpi_recv_ ||================================================================= ||================================================================= | 18.8% | 217.732094 | -- | -- | 510374.0 |MPI_SYNC ||----------------------------------------------------------------- || 9.3% | 107.482739 | 82.866435 | 43.7% | 87424.8 |mpi_allreduce_(sync) || 7.8% | 90.137755 | 68.867932 | 43.5% | 392235.5 |mpi_alltoallv_(sync) || 1.0% | 11.947095 | 10.972329 | 48.1% | 7.0 |mpi_barrier_(sync)
摨偠儀儞僠儅乕僋幚峴偱偺MPI捠怣帪娫傪64僐傾偲256僐傾偱斾妑偡傞偲丄MPI捠怣偼幚峴帪娫偺庡梫晹暘傪愯傔偰偄傞偙偲偑夝傝傑偡丅僙僋僔儑儞5偲6偵偍偗傞3D FFT墘嶼偱棙梡偝傟偰偄傞mpi_alltoallv偑摿偵拲栚傪傂偒傑偡丅偙傟傜MPI娭悢偺屇弌偟偺応強偲栚揑偑棟夝偝傟傞傋偒偱偡丅幚峴帪娫偺傎傏19%偑摨婜偵徚旓偝傟偰偍傝丄晧壸暘嶶栤戣偑惗偠偰偄傑偡丅儀僋僩儖壔傗僉儍僢僔儏岠棪偺岦忋傪峴偆昁梫偑偁傝傑偡偑丄僋傾僢僪僐傾偱偺1.2~1.3攞偺崅懍壔偼偲偰傕椙偄寢壥偱偡丅僗働乕儕儞僌惈擻偼壽戣偱偁傝丄僋傾僢僪僐傾偱偺CASTEP惈擻傪夵慞偡傞dCSE僾儘僕僃僋僩偱崕暈偟側偔偰偼側傝傑偣傫丅師偺2偮偺僙僋僔儑儞偱偙偺2偮偺嵟揔壔偺岠壥傪挷嵏偟傑偡丅
5 MPI_Alltoall捠怣偺僔僃傾乕僪儊儌儕乕僶僢僼傽
5.1 攚宨
CASTEP偱暲楍偵3D FFT傪幚峴偡傞曽朄偼丄"儁儞僔儖"忬偵暘晍偟偨僌儕僢僪偺僒僽僙僢僩偵懳偟偰x,y,z曽岦偱屄暿偵1D曄姺傪幚巤偡傞偙偲偱偡丅9屄偺僾儘僙僢僒乕偱峔惉偝傟偨娙扨側椺傪巊偭偰偙偺曽朄傪愢柧偟傑偡丅
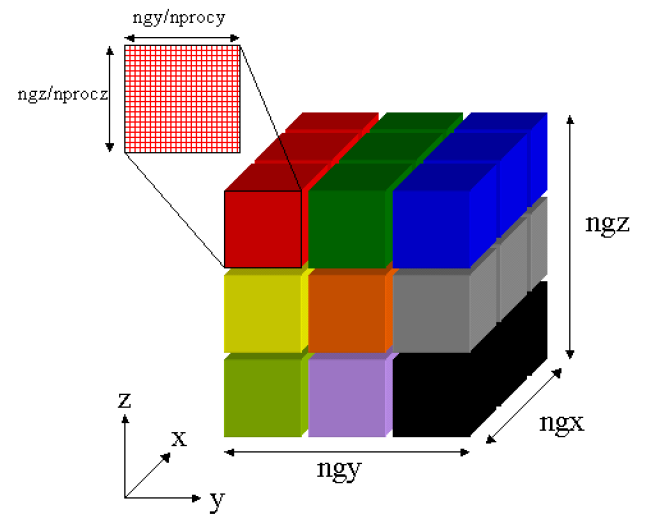
恾1丂丗丂3D暲楍FFT偱偺椞堟暘妱丅Step1丗x曽岦偱偺FFT幚峴
恾1偼奺僾儘僙僗偑x曽岦偵曄姺傪峴偆嵺偺椞堟暘妱傪昞偟傑偡丅奺僾儘僙僗偺僨乕僞傪堎側傞怓偱昞尰偟偰偄傑偡丅x,y,z曽岦偵偼偦傟偧傟ngx,ngy,ngz屄偺僌儕僢僪偑偁傝傑偡丅偦偙偱奺僾儘僙僗偼恾1偺x曽岦偵(ngy/nprocy)*(ngz/nprocz)屄偺曄姺傪幚峴偟傑偡丅師偵y曽岦偺曄姺傪幚峴偡傞偨傔偵僨乕僞傪夞揮(揮抲)偝偣傑偡丅摼傜傟偨僨乕僞偼堦偼恾2偵梌偊傜傟偰偄傑偡丅偙偺庤懕偒偼孞傝曉偝傟丄恾3偱帵偡僨乕僞攝抲偱奺僾儘僙僗偼z曽岦偺曄姺偑壜擻偵側傝傑偡丅
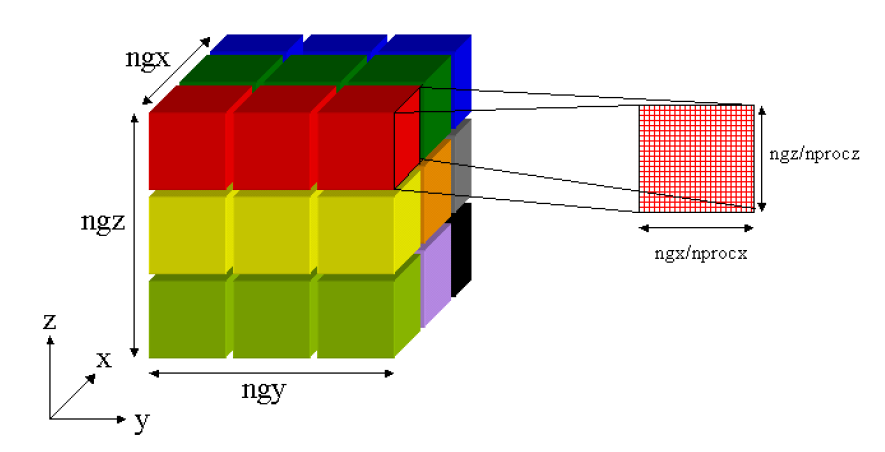
恾2丂丗丂3D暲楍FFT偱偺椞堟暘妱丅Step2丗恾1偺僨乕僞傪揮抲偟偰丄y曽岦偱FFT幚峴
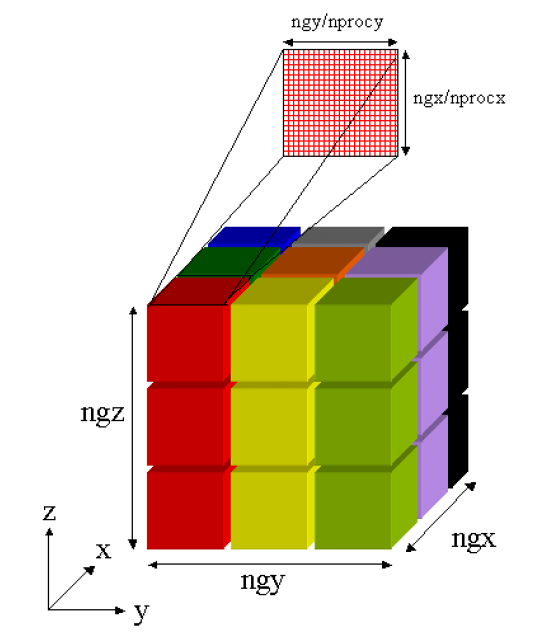
恾3丂丗丂3D暲楍FFT偱偺椞堟暘妱丅Step3丗恾2偺僨乕僞傪揮抲偟偰丄z曽岦偱FFT幚峴
5 MPI_Alltoall捠怣偺僔僃傾乕僪儊儌儕乕僶僢僼傽
HECToR忋偱偙偺墘嶼傪幚峴偡傞嵺偵嵟傕帪娫偑妡偐傞偺偼丄1D曄姺傪屪偖僨乕僞偺揮抲偱偡丅偙傟偼MPI_Alltoallv傪巊偭偰幚憰偝傟傑偡丅CASTEP偼偙偺揮抲憖嶌偵2偮偺僆僾僔儑儞傪帩偭偰偄傑偡丅僨僼僅儖僩偱偼慡偰偺僾儘僙僗偑MPI_Alltoallv屇弌偟偵嶲壛偟傑偡丅懠偺僆僾僔儑儞偼儅儖僠僐傾僔僗僥儉岦偗偱丄僲乕僪摉偨傝1僾儘僙僗偑MPI_Alltoallv傪屇弌偟傑偡丅偙傟偼丄扨堦僲乕僪撪偱扨堦偺憲怣僶僢僼傽傊憲傞僨乕僞傪僊儍僓乕偡傞MPI_Gather傪梡偄偰峴偄傑偡丅偦偺巜柤偝傟偨嶲壛僾儘僙僗偑MPI_Alltoallv屇弌偟偵嶲壛偡傞偺偱丄撪晹捠怣偺嫞崌偑嵟彫壔偝傟傑偡丅嶲壛僾儘僙僗偵傛傝庴怣偟偨僨乕僞偼僲乕僪撪偺懠偺僾儘僙僗傊僗僉儍僢僞乕偝傟傑偡丅
儅儖僠僐傾偵偍偗傞庡梫側僐僗僩偼丄MPI_Alltoallv屇弌偟偵懳偟偰惓偟偄弴彉偱儅乕僔儍儕儞僌偟丄傾儞儅乕僔儍儕儞僌偟偰MPI_Alltoallv屇弌偟屻偵僗僉儍僢僞乕偡傞偲偄偆丄僲乕僪撪偺僨乕僞廂廤偲娭楢偟偰偄傑偡丅椺偊偽丄儅儖僠僐傾儌乕僪偱16僾儘僙僢僒乕偱al1x1儀儞僠儅乕僋傪幚峴偡傞応崌丄僨僼僅儖僩儌乕僪偱偼222.9昩側偺偵懳偟偰292.1昩妡偐傝傑偡丅僨僼僅儖僩儌乕僪偱偼丄僨乕僞揮抲傪幚峴偡傞儖乕僠儞(comms transpose exchange)偵偍偄偰68.6昩妡偐傝傑偡偑丄儅儖僠僐傾儌乕僪偱偼115.8昩偵側傝傑偡丅僊儍僓儕儞僌偲儅乕僔儍儕儞僌偼17.5昩丄MPI_Alltoallv偼57.5昩丄偍傛傃傾儞儅乕僔儍儕儞僌偲僗僉儍僢僞乕偵偼58.9昩妡偐偭偰偄傑偡(僾儘僙僢僒乕暯嬒偺帪娫)丅
埲壓偺昞8偐傜10偱3庬偺儀儞僠儅乕僋惈擻傪帵偟傑偡丅僨僼僅儖僩儌乕僪偱偼丄憲怣/庴怣僶僢僼傽乕偺僷僢僋/傾儞僷僢僋偺僆乕僶乕僿僢僪偑戝偒偔側傞偨傔丄傛傝彮側偄僾儘僙僢僒乕偺応崌偺曽偑懍偄孹岦偵偁傝傑偡丅Shm偵傛傞嵟揔壔偼丄戝婯柾働乕僗偵懳偟偰傛傝懡偔偺僾儘僙僢僒巊梡偵尒崌偆惈擻傪帵偟偰偄傑偡丅椺偊偽丄128僾儘僙僢僒乕偱偺al3x3偺惈擻偼1.44攞偵崅懍壔偟偰偄傑偡丅傛傝寑揑側寢壥偼丄32僾儘僙僢僒乕偱偺al1x1偺1.78攞偺崅懍壔偱偡丅Shm僶僢僼傽偺摫擖偼慡偰偺応崌偵懳偟偰僐乕僪偺僗働乕儖惈擻傪岦忋偝偣傑偡丅
| nprocs | default | multicore | shm | default:shm |
| 8 | 334.9 | 545.3 | 387.9 | 0.86 |
| 16 | 222.9 | 292.1 | 207.6 | 1.07 |
| 32 | 223.5 | 157.3 | 125.5 | 1.78 |
| nprocs | default | multicore | shm | default:shm |
| 64 | 2260.6 | 3102.7 | 2665.3 | 0.85 |
| 128 | 1788.1 | 1783.9 | 1571.5 | 1.14 |
| 256 | 1563.9 | 1191.3 | 1086.6 | 1.44 |
| nprocs | default | multicore | shm | default:shm |
| 32 | 1324.53 | 1931.1 | 1404.9 | 0.94 |
| 64 | 655.0 | 993.5 | 748.9 | 0.87 |
| 128 | 431.3 | 550.1 | 415.6 | 1.04 |
5.3 崱屻傗傞傋偒偙偲
尰忬偺shm僔僃傾乕僪儊儌儕乕幚憰偼丄shm儊儌儕乕僙僌儊儞僩偺傾儘働乕僩偲傾僞僢僠偺偨傔偵C尵岅儖乕僠儞傪屇傃弌偟偰偄傑偡丅杮嶌嬈傪CASTEP偺僐乕僪傊慻傒崬傓偵偼丄C尵岅儖乕僠儞偼Fortran2003偺傛偆側昗弨揑側僀儞僞乕僼僃僀僗傪帩偮傋偒偱偡丅
尰忬偺幚憰偼丄HECToR偱偺僨僼僅儖僩偺傛偆偵SMP僗僞僀儖偺儔儞僋攝抲傪壖掕偟偰偄傑偡丅偟偐偟側偑傜丄僙僋僔儑儞3.2.1偱偼丄CASTEP偼folded rank攝抲偺曽偑摼偱偁傞偙偲偑帵偝傟傑偟偨丅shm偲僀儞僞乕僼僃僀僗傪庢傞C僐乕僪偼丄Cray偺僔僗僥儉僼傽僀儖傪撉傒崬傫偱儔儞僋攝抲傪寛傔傞娭悢傪娷傫偱偄傑偡丅shm偵傛傞嵟揔壔偺條乆側曽朄偺挷嵏偵偍偄偰丄幚峴帪偵儔儞僋攝抲傪寛掕偡傞偨傔偺儅僔儞偵埶懚偟側偄傗傝曽偵偮偄偰偼彨棃揑側壽戣偱偡丅
忋弎偺儅儖僠僐傾僆僾僔儑儞傪巊梡偡傞偵偼丄.param僼傽僀儖偵偰僆僾僔儑儞num_proc_in_smp傪4偵僙僢僩(偮傑傝丄1僲乕僪撪偺4偮慡偰偺僐傾傪扨堦SMP僌儖乕僾偵偡傞)偟傑偟偨偑丄暿偺HPC僾儘僕僃僋僩偱偼丄MPI_Alltoallv儊僢僙乕僕僒僀僘傪嵟揔壔偡傞偨傔偵僲乕僪撪偺嵟戝僐傾悢傪巜掕偡傞傛傝傕彫偝側抣偵偟偨曽偑桳棙偱偁傞応崌偑偁傞帠偑尒庴偗傜傟傑偟偨丅偙偺偙偲偐傜丄偙偙偱梡偄傜傟偨娐嫬傪斀塮偝偣偰丄儊僢僙乕僕僒僀僘傪嵟揔壔偡傞偨傔偺宱尡揑側傾儖僑儕僘儉傪挷傋傞偙偲偑帵嵈偝傟傑偡丅
6 僶儞僪丒僽儘僢僉儞僌FFT偺岠壥偵娭偡傞挷嵏
僙僋僔儑儞5.1偱婰弎偝傟偨3D FFT墘嶼偼丄乽僶儞僪乿偲屇偽傟傞婔壗妛揑偵摨摍側3D椞堟偵懳偟偰丄寢壥揑偵撈棫偟偨張棟傪幚峴偟傑偡丅傛偭偰丄偁傞摿掕偺曽岦偵偍偗傞揮抲偼慡僶儞僪偵懳偟偰摨摍偱偁傞偙偲偐傜丄儗僀僥儞僔乕傪塀暳偡傞偨傔偵暋悢偺僶儞僪傪堦偮偺MPI_Alltoallv屇弌偟傊堦弿偵揨傔偰偟傑偆偙偲偑弌棃傑偡丅
偙偙偱偺挷嵏偼丄僒僽儖乕僠儞basis_real_recip_reduced_many撪偵偍偄偰偙偺傛偆側"僶儞僪丒僽儘僢僉儞僌"傪壜擻偵偡傞扨堦僀儞僗僞儞僗偺嵟揔壔幚憰偵徟揰傪摉偰傑偡丅偙偺僒僽儖乕僠儞偼埲壓偺宍偺儖乕僾傪帩偪傑偡丗
do nb=1,nblock
丂call basis_fft_wrapper(ngx,ngy,ngz,grid(1,nb),-1,'W')
偙偺儖乕僾偼nblock屄偺僶儞僪偵懳偟偰3D FFT傪幚峴偟傑偡偑丄bandblock屄偱僽儘僢僋壔偟偨僶儞僪孮(bandblock bands)偱揨傔偨応崌偼埲壓偺傛偆偵廋惓偝傟傑偡丗
do nb=1,nblock/bandblock丂
丂call basis_fft_wrapper_bb(ngx,ngy,ngz,grid(1,(nb-1)*bandblock+1),丂&
丂-1,'W',max_grid_points)丂
(幚嵺偵偼忚梋暘偺儖乕僾傕晅偗壛偊傜傟傑偡)丅
偙偺怴偟偄FFT儔僢僷乕儖乕僠儞(FFTW3儔僢僷乕偺傒偵幚憰偟傑偟偨)偼丄堦搙偺屇弌偟偱bandblock bands偺僨乕僞傪揮抲偡傞慜偵丄bandblock夞偺dfftw_execute_dft偺屇傃弌偟傪幚峴偟傑偡丅怴偟偄揮抲憖嶌偼bandblock bands傪shm憲怣僶僢僼傽偵僷僢僉儞僌偟偰丄MPI_Alltoallv傪幚峴偟丄庴怣僶僢僼傽偐傜bandblock bands傪傾儞僷僢僋偟傑偡丅憲怣/庴怣僶僢僼傽偺僷僢僉儞僌偲傾儞僷僢僉儞僌偼丄僨乕僞偺惓偟偄攝抲傪曐徹偡傞偨傔偵adapted indexing朄傪梡偄偰偄傑偡丅
恾4偐傜6偼CASTEP偺帪娫僩儗乕僗婡擻傪梡偄偨3偮偺儀儞僠儅乕僋偵懳偡傞丄偙偺僶儞僪丒僽儘僢僉儞僌庤朄偺惈擻傪帵偟偰偄傑偡丅慡偰偺働乕僗偵偍偄偰丄僽儘僢僋壔偝傟偨僶儞僪悢偵懳偟偰惈擻楎壔偑帵偝傟偰偄傑偡丅恾7偼側偤偙偺惈擻楎壔偑惗偠偰偄傞偐傪帵偟偰偄傑偡丗12僶儞僪傑偱MPI_Alltoallv偺僐僗僩偼尭彮偟傑偡偑丄僔僃傾乕僪儊儌儕乕僶僢僼傽偺僷僢僉儞僌偲傾儞僷僢僉儞僌偺僐僗僩偼僶儞僪悢偵墳偠偰憹壛偟偰偄傑偡(偙偙偱偺帪娫偼暿搑MPI_Wtime傪梡偄偰寁應偟傑偟偨)丅偙偺偙偲偐傜丄僶儞僪丒僽儘僢僉儞僌偺傾僀僨傾偲偟偰丄儗僀僥儞僔乕傪嶍尭偡傞偨傔偵傛傝懡偔偺僨乕僞傪憲怣僶僢僼傽傊僷僢僉儞僌偡傞偙偲偑峫偊傜傟傑偡偑丄堦曽偦偺僶僢僼傽傪僷僢僋/傾儞僷僢僋偡傞帪偺怴偟偄儊儌儕乕傾僋僙僗僷僞乕儞偑廳梫偵側偭偰偒傑偡丅僶儞僪丒僽儘僢僉儞僌傪桳岠偵妶梡偡傞偨傔偵偼丄僔僃傾乕僪儊儌儕乕僶僢僼傽傊/偐傜僨乕僞傪僐僺乕偡傞曽朄傪嵟揔壔偡傞偙偲偑廳梫偱偡丅
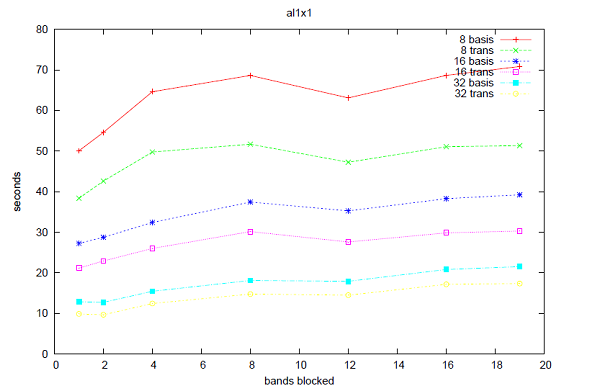
恾4丂丗丂8,16,32僾儘僙僢僒乕偱偺al1x1偺惈擻丅"basis"偼basis_real_recip_reduced_many偺寁應帪娫丄"trans"偼comms_transpose偺寁應帪娫丅
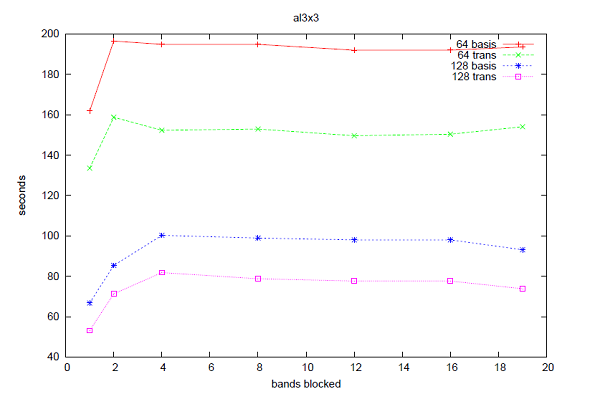
恾5丂丗丂64,128僾儘僙僢僒乕偱偺al3x3偺惈擻丅"basis"偼basis_real_recip_reduced_many偺寁應帪娫丄"trans"偼comms_transpose偺寁應帪娫丅
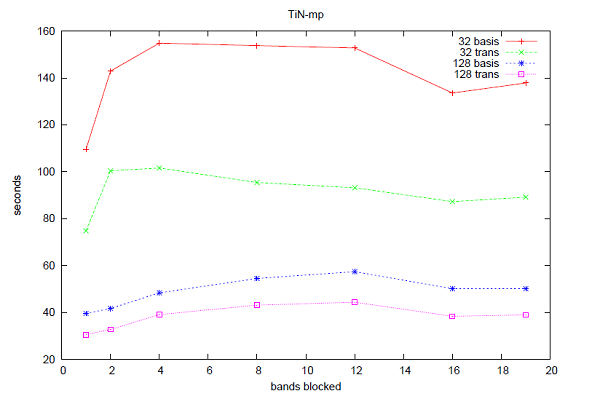
恾6丂丗丂32,128僾儘僙僢僒乕偱偺TiN-mp偺惈擻丅"basis"偼basis_real_recip_reduced_many偺寁應帪娫丄"trans"偼comms_transpose偺寁應帪娫丅
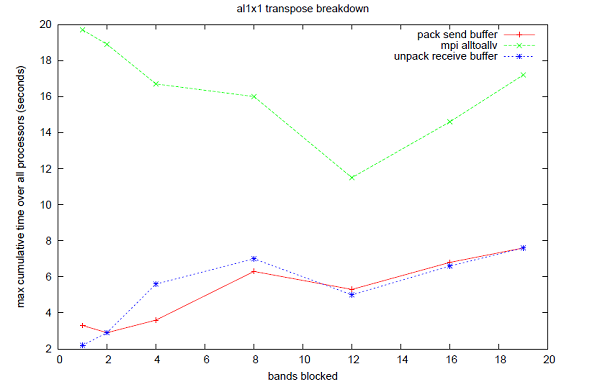
恾7丂丗丂16僾儘僙僢僒乕/al1x1偵偍偗傞丄comms_transpose撪偺寁應帪娫僾儘僼傽僀儖丅
昞11偼1僶儞僪偺惈擻偱妱偭偨5僶儞僪偺惈擻傪偟傑偟偰偄傑偡(偮傑傝丄1傛傝彫偝偗傟偽5僶儞僪惈擻偑桪傟丄1傛傝彫偝偗傟偽楎壔偟偰偄傞偙偲傪帵偟傑偡)丅
| Time | L1 misses | L1 misses | L1 misses | TLB misses | |
| pack | 1.07 | 0.78 | 5.83 | 3.65 | 1.63 |
| unpack | 1.26 | 0.77 | 3.17 | 7.67 | 2.22 |
昞12偼base儁乕僕僼傽僀儖傪梡偄偨応崌偲斾妑偟偨丄huge儁乕僕僼傽僀儖傪梡偄偨応崌偺惈擻偱偡丅
昞12偑帵偟偰偄傞偺偼丄base儁乕僕傪梡偄偨1僶儞僪偺応崌偲斾妑偟偰丄huge儁乕僕僼傽僀儖傪梡偄傞偲TLB儈僗帪娫偑傎傏摨摍偵側傞偙偲偱偡丅偟偐偟側偑傜丄宱夁帪娫偵偼傎偲傫偳塭嬁偑側偔丄L2偍傛傃L3僉儍僢僔儏儈僗偺惈擻楎壔偑巆懚偟偰偄傑偡丅偙偺huge儁乕僕僼傽僀儖偵娭偟偰偼惈擻偵梌偊傞塭嬁偑偁傝傑偣傫偱偟偨偑丄1僶儞僪偵偍偄偰huge儁乕僕傪揔梡偟偨応崌偼惈擻偼憹嫮偝傟丄僷僢僋偍傛傃傾儞僷僢僋儖乕僾偼base儁乕僕偵懳偟偰TLB儈僗偑0.09媦傃0.10偵尭彮偟傑偟偨偑丄宱夁帪娫斾偼傎傏1偺傑傑偱偟偨丅
偙偺偙偲偐傜丄TLB儈僗偼惈擻偵塭嬁傪梌偊偢丄L2偍傛傃L3僉儍僢僔儏儈僗偑嵟彫壔偝傟傞傋偒偙偲偑帵偝傟傑偟偨(偨偩偟5僶儞僪偵偍偄偰L1僉儍僢僔儏儈僗偑尭彮偟偰偄傞偙偲傪婰偟偰偍偒傑偡)丅
| Time | L1 misses | L1 misses | L1 misses | TLB misses | |
| pack | 1.00 | 0.78 | 5.73 | 3.72 | 1.08 |
| unpack | 1.24 | 0.77 | 3.15 | 7.59 | 1.02 |
6.1 崱屻偵偮偄偰
僔僃傾乕僪儊儌儕乕僶僢僼傽傊/偐傜偺僨乕僞僐僺乕曽朄傪曄峏偡傋偒偱偡丅尰忬偺傾僾儘乕僠偼尰忬偺僀儞僨僢僋僗攝楍傪摜廝偟偰偍傝丄偙傟偼儊儌儕乕忋傪峀偔憱嵏偟偰嬊強惈傪桳岠偵巊偭偰偄傑偣傫丅尰忬偺儊儌儕乕傾僋僙僗僷僞乕儞夝愅偲傛傝桳岠側僷僢僉儞僌/傾儞僷僢僉儞僌曽朄偺挷嵏偑昁梫偱偡丅
恾7偼丄僶儞僪丒僽儘僢僉儞僌偼MPI_Alltoallv惈擻傪夵慞壜擻偱偁傝丄儊儌儕乕僐僺乕偺夵慞傗丄偦傟傜傪巆傝偺僐乕僪傊揔梡偡傞偙偲偵傛傝偝傜偵惈擻偑夵慞偝傟傞偙偲傪帵偟偰偄傑偡丅
幱帿
System V僔僃傾乕僪儊儌儕乕娗棟僐乕僪偺採嫙偵娭偟偰David Tanqueray偵丄偍傛傃CASTEP擖椡偵娭偟偰Keith Refson偵姶幱偟傑偡丅
暥專
[1]丂CASTEP偵偍偗傞僶儞僪暲楍丗http://www.hector.ac.uk/cse/distributedcse/reports/castep/