
Numerical Algorithms Group Ltd.
僀儞僩儘僟僋僔儑儞
Interlagos僾儘僙僢僒乕偼AMD幮偺16僐傾Opteron僾儘僙僢僒乕偱偁傝丄HECToR僾儘僕僃僋僩偺僼僃乕僘3偱幚憰偝傟偰偄傑偡丅偙偺僾儘僙僢僒乕偼32nm僾儘僙僗偺Bulldozer/AMD僼傽儈儕乕偺15斣栚偺傾乕僉僥僋僠儍乕偱偁傝丄偦偺僐傾偼埲慜偺12僐傾MagnyCours(MC)僾儘僙僢僒乕偺傛偆側45nm僾儘僙僗AMD僼傽儈儕乕偺10斣栚偺愝寁傛傝傕丄懡偔偺儕僜乕僗傪搵嵹偟偰偄傑偡偑丄僀儞僥儖偺45nm僾儘僙僗12僐傾偺Westmere(WM)偺傛偆側僴僀僷乕僗儗僢僨傿儞僌丒僾儘僙僢僒乕傎偳懡偔偺儕僜乕僗傪帩偮傕偺偱偼偁傝傑偣傫丅杮儗億乕僩偼丄Interlagos僾儘僙僢僒乕丒傾乕僉僥僋僠儍乕傪愢柧偟丄儀儞僠儅乕僋惈擻偺應掕寢壥傪帵偟丄埲慜偺AMD/Margny-Cours(MC)偍傛傃僀儞僥儖/Westmere(WM)偲偺斾妑傪偟側偑傜傾乕僉僥僋僠儍乕偺娤揰偐傜寢壥傪暘愅偟偰偄傑偡丅
Interlagos僾儘僙僢僒乕丒傾乕僉僥僋僠儍乕
MC偲斾妑偟偰IL偺愝寁偱嵟戝偺柧妋側憡堘揰偼丄僐傾偺儁傾偑丄儕僜乕僗偵偍偄偰戝偒側斾棪傪愯傔傞"儌僕儏乕儖"偵攝抲偝傟偨偙偲偱偡丅恾1偵儌僕儏乕儖偺2偮偺僐傾娫偱儕僜乕僗偑嫟桳偝傟傞條巕傪帵偟傑偡丅
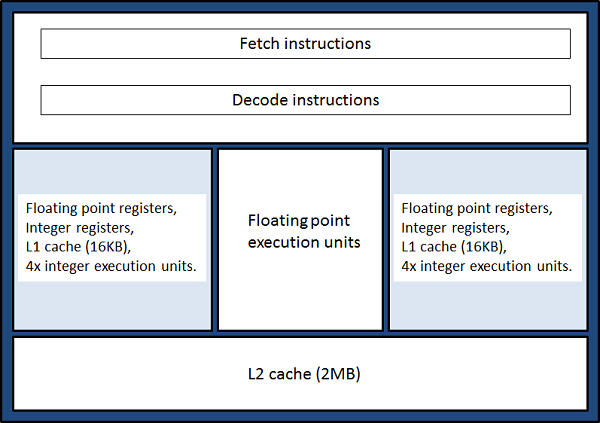
恾1丂丗丂Interlagos儌僕儏乕儖丅儌僕儏乕儖偼2偮偺僐傾(敄惵怓晹暘)偐傜峔惉偝傟丄偙傟傜偼撈棫偟偨L1僨乕僞僉儍僢僔儏丄儗僕僗僞乕偍傛傃惍悢墘嶼儐僯僢僩傪帩偮丅嫟桳儕僜乕僗偲偟偰丄L2僨乕僞僉儍僢僔儏丄晜摦彫悢揰墘嶼儐僯僢僩偍傛傃僼僃僢僠偲僨僐乕僪柦椷偺偨傔偺僴乕僪僂僃傾偑懚嵼偡傞丅
偙傟偼MC僾儘僙僢僒乕偺椬愙僐傾偑L2僉儍僢僔儏偐傜儕僜乕僗傪嫟桳偡傞偙偲丄偍傛傃僴僀僷乕僗儗僢僨傿儞僌帪偺WM僾儘僙僢僒乕偺壖憐僐傾偑丄惂屼晹偲捠忢栚揑偐偮晜摦彫悢揰墘嶼儗僕僗僞乕埲奜偺恾1偵帵偡慡偰偺儕僜乕僗傪嫟桳偡傞偙偲偲懳徠揑側傕偺偵側偭偰偄傑偡丅偮傑傝丄IL儌僕儏乕儖偺愝寁偼丄MC僾儘僙僢僒乕偱偺儕僜乕僗偺慡暘妱偲丄WM僾儘僙僢僒乕偺慡偰傪嫟桳偡傞応崌偲偺娫偺丄拞娫揑側曽朄傪偲偭偰偄傞偲尵偊傑偡丅偙傟偼CPU偺惍悢墘嶼偲晜摦彫悢揰墘嶼傪愗傝棧偡AMD偺嵟弶偺僗僥僢僾偲偟偰丄GPU傎偳偵儖乕僘側寢崌偱側偄偵偣傛丄CPU偐傜愗傝棧偝傟偨僐僾儘僙僢僒乕偵傛傝晜摦彫悢墘嶼傪峴偆偲偄偆丄彨棃揑側梈崌揑僾儘僙僢僒乕傊偺僗僥僢僾偱偁傞偲尒傞偙偲傕偱偒傑偡丅
儌僕儏乕儖傪傛傝徻嵶偵尒傞偲丄恾2偵帵偡傛偆偵嫟桳偝傟偨晜摦彫悢揰墘嶼儐僯僢僩偼丄扨堦偺256價僢僩僷僀僾儔僀儞偲偟偰寢崌壜擻側2偮偺128價僢僩偺僷僀僾儔僀儞偐傜峔惉偝傟偰偄傑偡丅偮傑傝偙偺晜摦彫悢揰墘嶼儐僯僢僩偼僋儘僢僋僒僀僋儖枅偵丄2偮偺128價僢僩SSE儀僋僩儖柦椷丄傑偨偼堦偮偺256價僢僩AVX偺壛嶼偁傞偄偼忔嶼儀僋僩儖柦椷傪幚峴壜擻偱偡丅偝傜偵SSE丄AVX柦椷偵壛偊偰怴偨偵丄晜摦彫悢揰墘嶼儐僯僢僩偺棟榑惈擻傪幚峴揑偵攞偵偡傞256價僢僩梈崌愊榓墘嶼(fused multiply-add)柦椷偑懚嵼偟傑偡丅偙傟偼忔嶼偑壛嶼偝傟傞慜偵娵傔傜傟傞偙偲偑側偄偨傔丄忔嶼偲偦偺屻偺壛嶼傪暘偗偰幚峴偡傞応崌偵斾傋偰惛搙揑側夵慞傕惗偠傑偡丅僐儞僷僀儔乕偼儖乕僾傪儀僋僩儖壔偡傞嵺偵丄弌棃傞尷傝偙偺柦椷傪揔梡偟傑偡丅偙偺怴偟偄AVX偲梈崌愊榓墘嶼偵偮偄偰偼埲壓偺帠偵拲堄偡傋偒偱偡丗
- 1偮偺256價僢僩AVX柦椷偼2偮偺128價僢僩SSE偺暲楍柦椷偲摨偠僗儖乕僾僢僩傪帩偪傑偡丗偮傑傝僋儘僢僋僒僀僋儖枅偵4屄偺攞惛搙FLOPS丄偁傞偄偼8屄偺扨惛搙FLOPS偱偁傝丄Margny-Cours僾儘僙僢僒乕偲摨偠偱偡丅偟偐偟側偑傜AVX柦椷偺棙揰偺堦偮偑丄偙傟傜偑non-destructive偱偁傞偙偲偱偡丅偮傑傝丄墘嶼寢壥偺擖椡儗僕僗僞乕撪梕傊偺忋彂偒偼敪惗偣偢丄墘嶼寢壥梡偺3斣栚偺儗僕僗僞乕偑懚嵼偟傑偡丅偙偺帠偵傛傝丄僐儞僷僀儔乕偼SSE柦椷偱昁梫側move墘嶼傪徣偔偙偲偑壜擻偵側傝惈擻岦忋偑婜懸偱偒傑偡丅
- 梈崌愊榓墘嶼(僋儘僢僋僒僀僋儖枅偺8攞惛搙FLOPS偁傞偄偼16扨惛搙FLOPS)偵傛傞棟榑惈擻岦忋偼丄IL僾儘僙僢僒乕偺8屄偺晜摦彫悢揰墘嶼儐僯僢僩偵懳偟偰MC僾儘僙僢僒乕偼12屄偱偁傞偨傔丄扨弮偵惈擻偑攞偵側傞偲偼尵偊傑偣傫丅
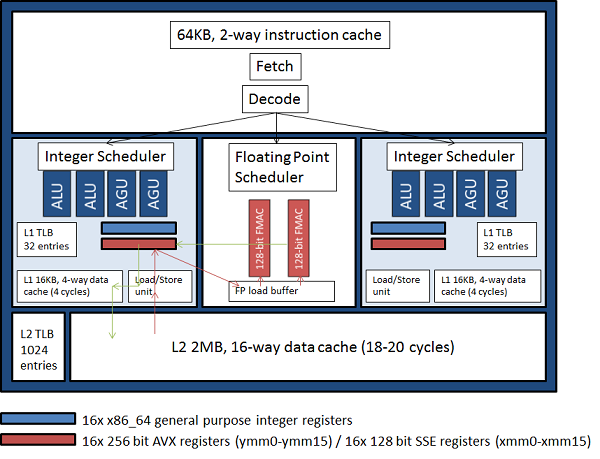
恾2丂丗丂Interlagos儌僕儏乕儖偺徻嵶丅愒偲椢偺栴報偼僨乕僞偺堏摦偺椺傪帵偡丅愒栴報偼丄FMAC(晜摦彫悢揰愊榓墘嶼婍)傊僨傿僗僷僢僠偝傟傞傑偱偺丄L2僉儍僢僔儏偐傜儗僕僗僞乕傊儘乕僪偝傟傞僆儁儔儞僪傪帵偟丄椢偺栴報偼丄儗僕僗僞乕傊彂偒栠偝傟偰丄L1(write僗儖乕僉儍僢僔儏)偲L2僉儍僢僔儏傊偲栠偝傟偨寢壥僨乕僞傪帵偡丅
Interlagos僾儘僙僢僒乕偼HyperTransport interconnection儕儞僋偵傛傝寢崌偝傟偨2偮偺僟僀偐傜峔惉偝傟傑偡丅奺僟僀偼儘乕僇儖儊儌儕乕偍傛傃6MB偺L3僨乕僞僉儍僢僔儏(偍傛傃僉儍僢僔儏僐僸乕儗儞僔乕偺偨傔偵僴乕僪僂僃傾揑偵梊栺偝傟偨2MB)傪嫟桳偡傞丄4偮偺儌僕儏乕儖偱峔惉偝傟傑偡丅偙偺忬嫷傪恾3偵帵偟傑偡丅僾儘僙僢僒乕撪偺2偮偺僟僀偼HyperTransport儕儞僋偱寢崌偝傟丄懠偺僟僀偺儊儌儕乕偵傾僋僙僗偡傞傛傝傕慺憗偔儘乕僇儖儊儌儕乕偵傾僋僙僗壜擻側Non-Uniform Memory Architecture(NUMA傾乕僉僥僋僠儍)偱儊儌儕乕傾僪儗僗嬻娫傪嫟桳偟傑偡丅偙傟傪恾4偵帵偟傑偡丅
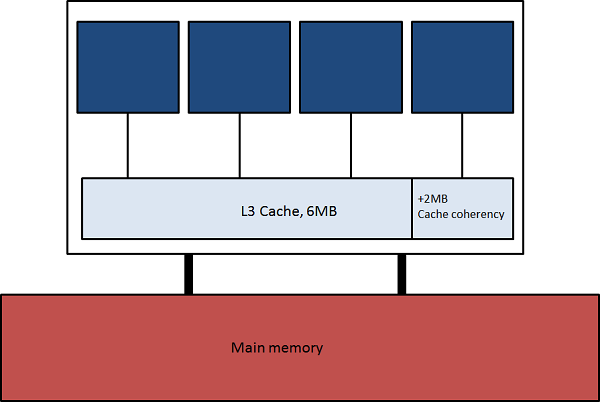
恾3丂丗丂Interlagos僟僀丅惵怓偺巐妏宍偼2僐傾偐傜惉傞儌僕儏乕儖傪帵偡丅
恾4丂丗丂Interlagos僾儘僙僢僒乕偼NUMA偵傛傞HyperTransport儕儞僋偱寢崌偝傟偨2偮偺僟僀偐傜峔惉偝傟傞丅
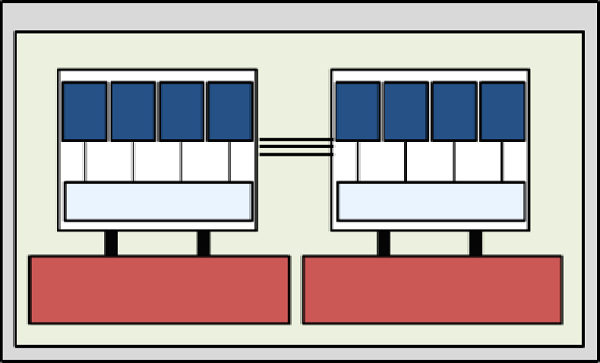
恾5偵帵偡捠傝丄NUMA僲乕僪偼2偮栚偺僾儘僙僢僒乕傪奜晹HyperTransport儕儞僋偱寢崌偟偰峔惉偝傟傑偡丅偙傟偼HECToR偺僲乕僪峔惉椺偱偡丅
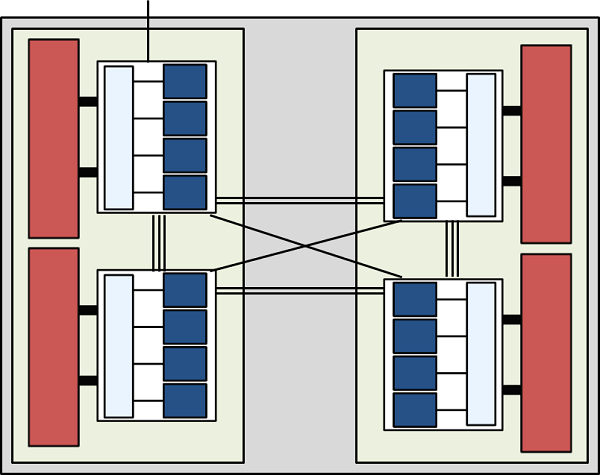
恾5丂丗丂NUMA僲乕僪偼2偮偺Interlagos僾儘僙僢僒乕偐傜峔惉偝傟丄僟僀娫偺寢崌偺悢偱帵偝傟傞傛偆偵丄僟僀偺僶儞僪暆偼僨乕僞偑偳偙傊/偐傜弌擖傝偡傞偐偵埶懚偟偰3:2:1偺斾棪偵側傞丅
僥僗僩僔僗僥儉
Interlagos(IL)
Interlagos僔僗僥儉偲偟偰HECToR Cray XE6偺僥僗僩丒奐敪僔僗僥儉TDS傪梡偄傑偟偨丅偙傟偼恾5偱帵偝傟偨78屄偺NUMA僲乕僪偱峔惉偝傟傑偡丅僾儘僙僢僒乕偺僋儘僢僋偼2.3GHz偱偁傝丄僺乕僋惈擻偼埲壓偱梌偊傜傟傑偡丗
埲慜偵帵偟偨傛偆偵丄怴偟偄Fused Multiply-Add柦椷(FMA)惈擻偼攞惛搙偱僋儘僢僋僒僀僋儖枅偵8FLOPS偱偡丅僲乕僪撪偺4偮偺僟僀奺乆偼丄8GB DDR3@1333MHz偺儘乕僇儖儊儌儕乕傪搵嵹偡傞偨傔丄僲乕僪撪偱偼32GB偺嫟桳儊儌儕乕傪採嫙偡傞偙偲偵側傝傑偡丅
Magny-Cours(MC)
Magny-Cours(MC)僔僗僥儉偲偟偰丄恾5偱帵偟偨傕偺偲摨偠NUMA僩億儘僕乕傪帩偪丄奺僲乕僪偑2偮偺12僐傾僾儘僙僢僒乕傪搵嵹偡傞1856僲乕僪偱峔惉偝傟傞丄僼僃乕僘2b偺HECToR Cray XE6僔僗僥儉傪梡偄傑偟偨丅僾儘僙僢僒乕偺僋儘僢僋偼2.1GHz偱丄僗乕僷乕僗僇儔乕儌乕僪偱摦嶌偟丄僋儘僢僋僒僀僋儖枅偵2偮偺攞惛搙偺愊榓墘嶼寢壥傪曉偟傑偡丅棟榑揑側僺乕僋惈擻偼埲壓偺捠傝偱偡丗
僲乕僪撪偺4偮偺僟僀奺乆偼丄8GB DDR3@1333MHz偺儘乕僇儖儊儌儕乕傪搵嵹偡傞偨傔丄僲乕僪撪偱偼32GB偺嫟桳儊儌儕乕傪採嫙偡傞偙偲偵側傝傑偡丅Magny-Cours(MC)僾儘僙僢僒乕撪偺奺僐傾偼丄僟僀撪偺椬愙僐傾偲L2僉儍僢僔儏偺傒傪嫟桳偟傑偡丅
Westmere(WM)
Westmere僔僗僥儉偼丄僴僀僷乕僗儗僢僨傿儞僌傪僒億乕僩偡傞2屄偺2.93GHz偺6僐傾Xeon僾儘僙僢僒乕偐傜惉傝丄僲乕僪撪偱24偺僶乕僠儍儖僐傾傪婲摦偡傞偙偲偑偱偒傑偡丅奺僾儘僙僢僒乕偼12GB DDR3@1333MHz偺儘乕僇儖儊儌儕乕傪帩偪丄僲乕僪娫偱QuickPath interconnect儕儞僋(HyperTransport偲摨巇條)傪捠偟偰嫟桳偟傑偡丅棟榑僺乕僋惈擻偼埲壓偺捠傝偱偡丗
Westmere僾儘僙僢僒乕偺奺僐傾偼丄儗僕僗僞乕埲奜偺慡偰偺儕僜乕僗傪嫟桳偟丄2僾儘僙僢僒乕/僗儗僢僪傪僴乕僪僂僃傾揑偵僒億乕僩丄偮傑傝2屄偺僶乕僠儍儖僐傾傪僒億乕僩偟傑偡丅
儀儞僠儅乕僋
忋弎偟偨Interlagos僾儘僙僢僒乕偺傾乕僉僥僋僠儍乕偐傜惗偠傞専徹偡傋偒億僀儞僩傪埲壓偵婰偟傑偡丅
Q1丂丗丂怴偟偄AVX偲FMA(Fused Multiply-Add)柦椷傪摫擖偵傛傝丄寁嶼揑偵晧壸偺戝偒偄寁嶼晹偼擛壗偵僠儏乕僯儞僌偝傟傞偺偐丠僔儕傾儖僾儘僌儔儉偼MC偲斾妑偟偰2攞偵側傞偺偐丠
Q2丂丗丂儌僕儏乕儖撪偺儕僜乕僗嫟桳(晜摦彫悢揰墘嶼儐僯僢僩丄柦椷僼儘儞僩僄儞僪丄L2僉儍僢僔儏偍傛傃TLB)偵傛傝悢抣寁嶼儖乕僠儞傊偳偺傛偆側塭嬁偑偁傞偺偐丠偦偺寢壥傪丄傛傝彮側偄嫟桳儕僜乕僗傪帩偮(MC)傕偺傗丄傛傝懡偔偺儕僜乕僗傪嫟桳偡傞(WM)帡偨僔僗僥儉偲偳偺傛偆偵斾妑偡傞偺偐丠
Q3丂丗丂MC偲斾妑偟偰丄僟僀偵捛壛偝傟偨2僐傾偵傛傞儊儌儕乕僶儞僪暆忋偺嫞崌憹壛偺塭嬁偼偳偺傛偆偵側傞偐丠
偙傟傜偺栤戣偵懳偟偰丄(a)崅寁嶼晧壸偺晜摦彫悢揰墘嶼惈擻丄(b)崅儊儌儕乕晧壸偺惍悢墘嶼惈擻丄偲偄偆揰偺塭嬁傪挷傋傞偨傔偵丄2偮偺儀儞僠儅乕僋僥僗僩傪慖戰偟傑偟偨丅(a)偵懳偟偰偼DGEMM傪慖傃傑偟偨丅DGEMM偼崅寁嶼晧壸偺BLAS level3儖乕僠儞偱丄Interlagos僾儘僙僢僒乕偺怴偟偄FMA柦椷偺棙揰傪堷偒弌偡偙偲偑弌棃丄偐偮儀儞僟乕儔僀僽儔儕乕偲偟偰崅搙偵僠儏乕僯儞僌偝傟偨OpenMP幚憰偑巤偝傟偰偄傑偡丅(b)偵懳偟偰偼儊儖僙儞僰丒僣僀僗僞乕傪慖傃傑偟偨丅偙傟偼儀僋僩儖壔晄擻側惍悢墘嶼傪幚峴偡傞傕偺偱偁傝丄Interlagos儌僕儏乕儖偺惍悢墘嶼儐僯僢僩傪暲楍偵棙梡偱偒傞偱偟傚偆丅傑偨奩摉偡傞nAG偺SMP偍傛傃儅儖僠僐傾儔僀僽儔儕乕偼OpenMP幚憰偝傟偰偄傑偡丅
DGEMM丂儀儞僠儅乕僋
DGEMM偺僥僗僩偵埲壓偺娙扨側僥僗僩僾儘僌儔儉傪梡偄傑偟偨丗
program matmul_test
丂use mpi
丂use timers
丂implicit none
丂integer :: n
丂double precision, allocatable, dimension(:,:) :: a,b,c
丂integer :: ierr,myrank
丂call mpi_init(ierr)
丂call mpi_comm_rank(mpi_comm_world,myrank,ierr)
丂if(myrank.eq.0) read(5,*) n
丂call mpi_bcast(n,1,mpi_integer,0,mpi_comm_world,ierr)
丂allocate(a(n,n),b(n,n),c(n,n))
丂a(:,:) = 0.d0
丂call random_number(b)
丂call random_number(c)
丂call start_timer(1)
丂call dgemm('n','n',n,n,n,1.d0,a,n,b,n,0.d0,c,n)
丂call end_timer(1)
丂call print_timers()
丂call mpi_finalize(ierr)
end program matmul_test
偙偺僾儘僌儔儉偼懡悢偺DGEMM傪暲楍偵幚峴偡傞傕偺偱偡丅僞僀儈儞僌儌僕儏乕儖偼丄慡僾儘僙僢僒乕偵懳偟偰嵟戝丄嵟彫偍傛傃暯嬒偺宱夁帪娫傪弌椡偟傑偡丅奺僥僗僩儅僔儞忋偵偍偄偰偼丄嵟傕揔偟偨僐儞僷僀儔乕偲儀儞僟乕儔僀僽儔儕乕偲偟偰丄IL偲MC忋偱偼Cray 7.4.0偲libsci 11.0偍傛傃WM忋偱偼ifort 12.0, MKL 10.3偵傛傝僐儞僷僀儖儕儞僋偝傟傑偟偨丅偙傟傜儔僀僽儔儕乕偼丄OMP_NUM_THREADS娐嫬曄悢偱惂屼壜擻側DGEMM偺儅儖僠僗儗僢僪斉偱偡丅
偙偙偱奺儅僔儞忋偱3庬偺惈擻僗働乕儕儞僌傪應掕偟傑偟偨丗
(a) 僲乕僪傪姰慡偵朞榓偝偣偨帪偺儅儖僠僗儗僢僨傿儞僌偺僗働乕儔價儕僥傿
(b) 扨堦僾儘僙僗帪偺儅儖僠僗儗僢僨傿儞僌偺僗働乕儔價儕僥傿
(c) 儅儖僠僾儘僙僗偺僗働乕儔價儕僥傿
(a)偲(b)偵懳偟偰OMP_NUM_THREADS抣傪丄IL偱偼1,2,3,4,8,16丄MC偲WM偱偼1,2,3,4,6,12,24偲偟傑偟偨丅僥僗僩(a)偱偼丄MPI僾儘僙僗悢NPROCS傪NPROCS*OMP_NUM_THREADS=32(IL偱偼OMP_NUM_PROC=3, NPROC=10偲偟偨)偲側傞傛偆偵巜掕偟丄傑偨丄NPROC偵娭偡傞暯嬒帪娫傪寁應偟傑偟偨丅僥僗僩(c)偵偮偄偰傕摨條偵NPROC偵娭偡傞暯嬒帪娫傪寁應偟傑偟偨丅杮儗億乕僩偱偼忋弎偺Q1偐傜Q3傊偺夞摎偵娭楢偡傞寢壥傪曬崘偟傑偡丅
儀乕僗儔僀儞偲側傞寢壥傪丄旕僗儗僢僪僶乕僕儑儞偺儔僀僽儔儕傪梡偄偨扨堦僾儘僙僗偵傛傝應掕偟傑偟偨丅奺僾儘僙僢僒乕偱偺儀乕僗儔僀儞傪昞1偵帵偟傑偡丅
| N | IL (Secs.,GFLOPS/s) | MC | WM |
| 1,000 | 0.156, 12.9 | 0.262, 7.7 | 0.181, 11.1 |
| 2,000 | 1.211, 13.3 | 2.043, 7.9 | 1.433, 11.2 |
| 3,000 | 4.093, 13.3 | 6.868, 7.9 | 4.816, 11.3 |
| 4,000 | 9.630, 13.4 | 16.227, 7.9 | 11.395, 11.3 |
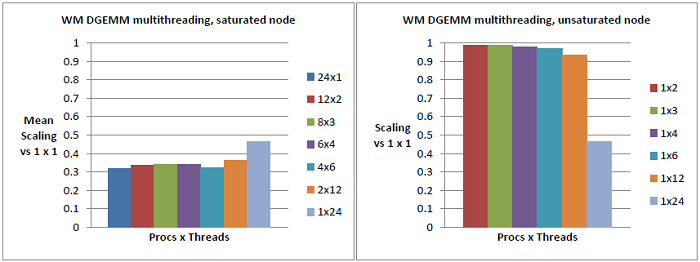
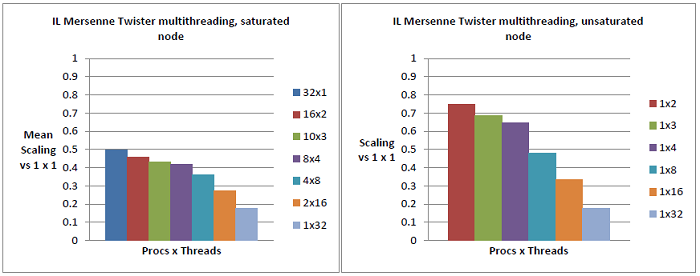
昞1偑Q1傊偺夞摎偱偡丅偦偺惈擻偼MC偺抣偺1.7攞偱偁傝丄2攞傑偱偼偄偒傑偣傫丅僐儞僷僀儔乕偺嵟揔側AVX柦椷傪惗惉偡傞婡擻偑丄SSE柦椷傪惗惉偡傞応崌偵斾傋偰傑偩枹惉弉偱偁傞偲峫偊傜傟傑偡丅傛傝嵟怴偺僐儞僷僀儔乕傪梡偄傟偽2攞偵嬤偔側傞偲峫偊偰傛偄偱偟傚偆丅MC偵斾傋偰WM偑旕忢偵懍偄偺偼丄僾儘僙僢僒乕偺僋儘僢僋偑懍偄偙偲偲丄MC/IL偱偺Cray偺libsci幚憰傛傝傕MK幚憰偑WM偵揔偟偨僠儏乕僯儞僌偑巤偝傟偰偄傞偨傔偱偁傝丄TPP偵懳偡傞斾棪傕崅偄傕偺偲側偭偰偄傑偡丅偄偢傟偵偣傛IL偼WM傛傝桪偭偰偄傑偡丅
恾6偐傜9偼丄昞1偵帵偟偨儀乕僗儔僀儞傪婎弨偲偟偨丄奺僥僗僩儅僔儞忋偱幚巤偝傟偨N=4,000偱偺惈擻傪帵偟偰偄傑偡丅
慡偰偺僌儔僼偵偍偄偰丄y幉偼埲壓偺幃偱寁嶼偝傟偰偄傑偡丗
baseline_time/(OMP_NUM_THREADS*threaded_time)
傛偭偰抣1偼姰慡偵僗働乕儕儞僌偟偨忬懺傪堄枴偟丄1埲壓偱偁傟偽丄暲楍傾儖僑儕僘儉撪偺僆乕僶乕僿僢僪(DGEMM偺2偮偺幚憰偱傎傏摨摍偲傒側偟偰偄傑偡)丄偍傛傃偝傜偵廳梫側儕僜乕僗嫞崌偺塭嬁傪帵偟傑偡丅
恾6偲7偼Q2傊偺夞摎偱偁傝丄儌僕儏乕儖儗儀儖偺儕僜乕僗傪嫟桳偡傞僗儗僢僪偵傛傞惈擻傊偺廳戝側塭嬁傪帵偟偰偄傑偡丅DGEMM偺応崌偼惈擻楎壔偵懳偡傞塭嬁偼栺40%偱偡丅
Q2偺擇斣栚偵娭偟偰丄恾8偲9偼偦偺傾乕僉僥僋僠儍乕偐傜婜懸偝傟傞條巕偑帵偝傟偰偄傑偡丗扨堦僾儘僙僗偲斾妑偟偰MC偺僗働乕儔價儕僥傿偼丄L2僉儍僢僔儏傪彍偒僐傾偺姰慡側撈棫惈偑懚嵼偡傞偨傔戝偒偔懝側傢傟傞偙偲偼偁傝傑偣傫丅WM偺僗働乕儔價儕僥傿偼戝偒偔懝側傢傟偰偄傑偡(WM偺寢壥偼嵟戝丄嵟彫偍傛傃暯嬒宱夁帪娫偵戝偒側偽傜偮偒偑偁傞帠傪拲婰偟偰偍偒傑偡)丅扨堦僾儘僙僗偵斾傋偰慡僶乕僠儍儖僲乕僪傪梡偄偨応崌偼惈擻偺70%懝幐偑惗偠偰偍傝丄偙傟偼僴僀僷乕僗儗僢僨傿儞僌偺嵺偵儗僕僗僞乕傑偱2僾儘僙僢僒乕偁傞偄偼奺僐傾偺僗儗僢僪偑嫟桳偟偰偄傞偨傔偱偡丅IL偺僾儘僙僢僒乕偼偙傟傜偺寢壥偺拞娫揑側傕偺偱丄儕僜乕僗偺晹暘揑側嫟桳偺偨傔惈擻偼40%懝幐偟偰偄傑偡丅
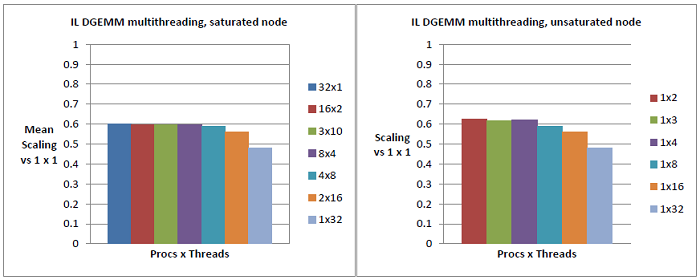
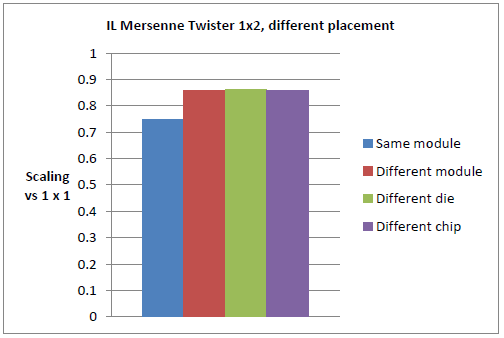
恾6丂丗丂朞榓IL僲乕僪(嵍恾)偲旕朞榓IL僲乕僪(塃恾)偵偍偗傞DGEMM偺儅儖僠僗儗僢僪丒僗働乕儕儞僌僥僗僩丅扨堦僗儗僢僪偱偺扨堦僾儘僙僗幚峴帪偲斾妑偟偰丄IL忋偺DGEMM偺32暲楍幚峴偼惈擻偑40%懝幐偟偰偄傞(32x1丄嵍偺惵怓僶乕)丅偙傟偼8僗儗僢僪偱偝傜偵忋徃偡傞(僞乕僐僀僘怓僶乕丄4x8)偑丄偙偙偱偼僗儗僢僪偑摨堦僟僀傪愯傔偰偍傝丄偙傟偼儕僜乕僗嫞崌偺憹壛傛傝傕暲楍僆乕僶乕僿僢僪偺婑梌偵傛傞傕偺偱偁傞丅16僗儗僢僪(僆儗儞僕怓僶乕丄2x16)偱偼IL僾儘僙僢僒乕撪偱HyperTransport(HT)儕儞僋偺捠怣偑惗偠丄惈擻傪50%埲壓偵墴偟壓偘傞丅塃恾偺僠儍乕僩偼丄2僗儗僢僪偺傒傪梡偄偨応崌偱偝偊嵍恾偺傕偺偐傜旝柇側嵎偑偁傞丅偙傟偼僨僼僅儖僩偱偼僗儗僢僪偼弴斣偵攝抲偝傟傞偨傔偱偁傝丄椺偊偽2僗儗僢僪偺応崌(愒怓僶乕丄1x2)偦傟傜偼摨偠儌僕儏乕儖傪嫟桳偡傞偨傔偱偁傞丅2偮偺僠儍乕僩偺椶帡惈偼儌僕儏乕儖儗儀儖偺嫟桳偑丄偦傟偑2僗儗僢僪偱偝偊丄惈擻傪40%堷偒壓偘偰偄傞偙偲傪帵嵈偟偰偄傞丅偙傟偼丄埲壓偺恾7偱帵偟偨寢壥偑峏側傞徹嫆偲側偭偰偄傞丅
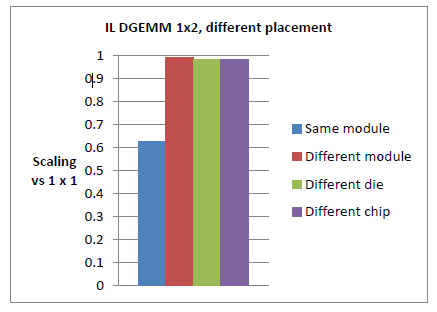
恾7丂丗丂僨僼僅儖僩攝抲(惵怓僶乕)偱偼丄椬愙僐傾偵僗儗僢僪偼攝抲偝傟傞偑丄偙傟偼椉曽偺僗儗僢僪偑摨偠儌僕儏乕儖傪嫟桳偡傞偙偲傪堄枴偡傞丅摨堦僟僀(愒怓僶乕) 偺堎側傞儌僕儏乕儖傗丄摨堦僾儘僙僢僒乕拞偺堎側傞僟僀(椢)傗丄堎側傞僾儘僙僢僒乕(巼)(偙傟傜偺攝抲偼Cray XE6偱偼aprun傊偺-cc僼儔僌偱惂屼壜擻偱偁傝丄偦傟偧傟丄aprun -n 1 -d 2 -cc 0,2, aprun -n 1 -d 2 -cc 0,8, aprun -n 1 -d 2 -cc 0,16偲偟偰巊梡偡傞)傊2斣栚偺僗儗僢僪傪攝抲偡傞偙偲偵傛傝惈擻偼戝偒偔忋徃偟丄傎傏姰慡側僗働乕儕儞僌惈擻傪帵偡丅偙傟偼恾6偱尒傜傟偨惈擻偺40%懝幐偑丄僗儗僢僪偺儕僜乕僗嫟桳丄偙偺応崌偼晜摦彫悢揰墘嶼儐僯僢僩偺嫟桳偑嵟傕婑梌偟偰偄傞偙偲傪帵偟偰偄傞丅
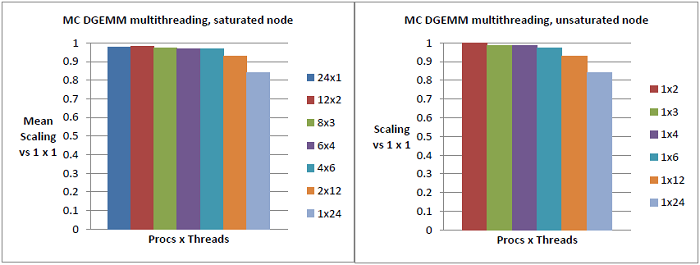
恾8丂丗丂朞榓MC僲乕僪(嵍恾)偲旕朞榓MC僲乕僪(塃恾)偵偍偗傞DGEMM偺儅儖僠僗儗僢僪丒僗働乕儕儞僌僥僗僩丅L2僉儍僢僔儏埲壓偺傒傪椬愙僐傾偑嫟桳偟偰偄傞偨傔丄婜懸捠傝偵椙偄僗働乕儔價儕僥傿偑帵偝傟偰偄傞丅恾6偺僨乕僞偲懳徠揑偵丄儅儖僠僗儗僢僨傿儞僌偼儀乕僗儔僀儞偐傜偺塭嬁偼彮側偄丅僾儘僙僗丒僗儗僢僪偑僟僀嫬奅傪屪偖応崌偵偺傒丄恾6偱傕尒偨捠傝偺NUMA傾乕僉僥僋僠儍乕偵傛傞惈擻楎壔偑惗偠傞丅
恾9丂丗丂朞榓WM僲乕僪(嵍恾)偲旕朞榓WM僲乕僪(塃恾)偵偍偗傞DGEMM偺儅儖僠僗儗僢僪丒僗働乕儕儞僌僥僗僩丅嫟桳儕僜乕僗偺儗儀儖偐傜婜懸偝傟傞捠傝偵丄朞榓WM忋偺DGEMM偺僗働乕儕儞僌惈擻偼旕忢偵埆偄丅嫽枴怺偄偙偲偵丄扨堦僾儘僙僗偑慡僲乕僪傪愱桳偟偨応崌偵惈擻偼彮偟夵慞偡傞丅峫偊傜傟傞壜擻惈偲偟偰丄MKL偼僴僀僷乕僗儗僢僨傿儞僌偑桳岠側偲偒偺傒偦偺棙揰傪嵟揔壔偟偰偍傝丄傕偟偦偆偡傞偙偲偱棙揰偑偁傞側傜偽傛傝彮側偄僗儗僢僪傪梡偄丄DGEMM偺傛偆側崅寁嶼晧壸墘嶼偺儕僜乕僗忋偺嫞崌傪尭傜偟偰偄傞偙偲偱偁傞丅旕朞榓働乕僗偺僗働乕儔價儕僥傿偼12僗儗僢僪傑偱MC偲傎傏摨摍偺惈擻傪帵偟偰偄傞丅偙傟偼僨僼僅儖僩偱偼僗儗僢僪偑慡偰偺僐傾偵峴偒搉傞傑偱暿偺暔棟僐傾傊攝抲偡傞偨傔偱丄偦偺屻偵傛偆傗偔僐傾偼儕僜乕僗傪嫟桳偟偰僴僀僷乕僗儗僢僨傿儞僌偑惗偠傞偨傔偱偁傞丅
儊儖僙儞僰丒僣僀僗僞乕丂儀儞僠儅乕僋
偙偺儀儞僠儅乕僋梡偵丄nAG儖乕僠儞G05SAF(嬒堦媈帡棎悢敪惗婍)傪丄NPROCS悢偺暲楍屇弌偟傪幚峴偡傞傛偆偵廋惓偟傑偟偨丅
Program g05safe !丂G05SAF Example Program Text !丂Mark 24 Release. nAG Copyright 2011. !丂.. Use Statements .. 丂Use nag_library, Only: g05kff, g05saf, nag_wp 丂use timers 丂use mpi ! .. Implicit None Statement .. 丂Implicit None ! .. Parameters .. 丂Integer, Parameter :: lseed = 1, nin = 5, nout = 6 ! .. Local Scalars .. 丂Integer :: genid, ifail, lstate, n, subid ! .. Local Arrays .. 丂Real (Kind=nag_wp), Allocatable :: x(:) 丂Integer :: seed(lseed) 丂Integer, Allocatable :: state(:) 丂integer :: ierr, myrank ! .. Executable Statements .. 丂call mpi_init(ierr) 丂call mpi_comm_rank(mpi_comm_world,myrank,ierr) 丂if(myrank.eq.0)then 丂丂Write (nout,*) 'G05SAF Example Program Results' 丂丂Write (nout,*) ! Skip heading in data file 丂丂Read (nin,*) ! Read in the base generator information and seed 丂丂Read (nin,*) genid, subid, seed(1) ! Read in sample size 丂丂Read (nin,*) n 丂end if 丂call mpi_bcast(genid,1,mpi_integer,0,mpi_comm_world,ierr) 丂call mpi_bcast(subid,1,mpi_integer,0,mpi_comm_world,ierr) 丂call mpi_bcast(seed(1),1,mpi_integer,0,mpi_comm_world,ierr) 丂call mpi_bcast(n,1,mpi_integer,0,mpi_comm_world,ierr) ! Initial call to initialiser to get size of STATE array 丂lstate = 0 丂Allocate (state(lstate)) 丂ifail = 0 丂Call g05kff(genid,subid,seed,lseed,state,lstate,ifail) ! Reallocate STATE 丂Deallocate (state) 丂Allocate (state(lstate)) ! Initialize the generator to a repeatable sequence 丂ifail = 0 丂Call g05kff(genid,subid,seed,lseed,state,lstate,ifail) 丂Allocate (x(n)) ! Generate the variates 丂ifail = 0 丂call init_counters 丂call start_timer(1) 丂Call g05saf(n,state,x,ifail) 丂call end_timer(1) ! Display the variates !Write (nout,99999) x(1:n) 丂call print_timers() 丂call mpi_finalize(ierr) 丂99999 Format (1X,F10.4) End Program g05safe
SMP偍傛傃儅儖僠僐傾懳墳偺nAG儔僀僽儔儕乕偺G05SAF偺OpenMP僶乕僕儑儞傪梡偄偰丄DGEMM儀儞僠儅乕僋偱峴偭偨儅儖僠僾儘僙僗偍傛傃儅儖僠僗儗僢僨傿儞僌偺摨條偺愝掕傪峴偄傑偟偨丅IL忋偱偼PGI僐儞僷僀儔僶乕僕儑儞11.9傪巊梡偟丄MC忋偱偼PGI 11.5丄WM忋偱偼ifort 12.0傪巊梡偟傑偟偨丅慡偰偵偍偄偰"-fast"僐儞僷僀儖僼儔僌傪梡偄傑偟偨丅埲壓偺擖椡僼傽僀儖傪慡偰偺僥僗僩偱巊梡偟丄奺僾儘僙僗偱125,000,000屄偺棎悢傪敪惗偝偣傑偟偨丅
G05SAF Example Program Data 3 1 1762543 :: GENID,SUBID,SEED(1) 125000000 :: N
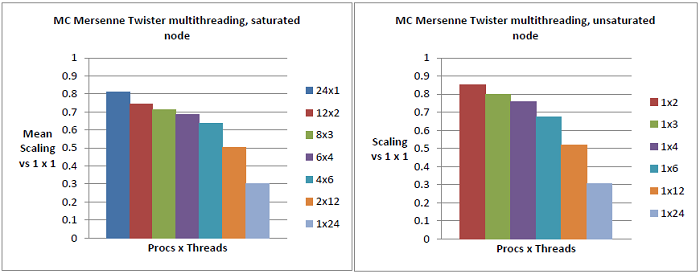
儊儖僙儞僰丒僣僀僗僞乕偺傾儖僑儕僘儉偵偍偗傞寁嶼僇乕僱儖偼惍悢墘嶼偑庡偱丄嵟屻偵惍悢傪晜摦彫悢揰偵僉儍僗僩偡傞偺傒偱偡偑丄DGEMM偲偼堎側傝偦偺惈擻偼寁嶼傛傝傕儊儌儕乕傾僋僙僗偵傛傝巟攝偝傟傑偡丅傛偭偰僐傾儗儀儖偺儕僜乕僗偲摨條偵儊儌儕乕偺嫞崌偑惈擻偵婑梌偡傞廳梫側場巕偲側傝傑偡丅偝傜偵DGEMM偲斾妑偟偰堎側傞揰偼丄彫偝側N(125,000,000偼斾妑揑彫偝側抣偱偡)偵懳偟偰傕惗惉僔乕働儞僗(僔儕傾儖幚峴帪偲摨摍偺僔乕働儞僗偑曐徹偝傟傑偡)偺暲楍僆乕僶乕僿僢僪偑柍帇偱偒側偄偙偲偱偡丅昞2偼僲乕僪傪愱桳偟偰幚峴偟偨扨堦僗儗僢僪僾儘僙僗偺儀乕僗儔僀儞寢壥偱偡丅
| IL (Secs.,GFLOPS/s) | MC | WM | |
| Time (secs) | 1.573 | 1.501 | 0.656 |
WM偺惈擻偼2偮偺AMD僾儘僙僢僒乕惈擻傪椊夗偟偰偄傑偡丅偙傟偼儊儌儕乕僒僽僔僗僥儉偺惈擻(IL偵斾傋偰2丆3妱埲忋偺儊儌儕乕憖嶌傪幚峴偡傞偙偲偑弌棃傑偡丅嶲峫忣曬丗http://www.realworldtech.com/page.cfm?ArticleID=RWT082610181333&p=8)傗崅偄僋儘僢僋廃攇悢偍傛傃僐儞僷僀儔乕惈擻偑傛傝桪傟偰偄偨寢壥偲峫偊傜傟傑偡丅
DGEMM僥僗僩偲摨條偵丄偙偺愡偱偼丄梌偊傜傟偨儕僜乕僗撪偱昞2偺儀乕僗儔僀儞傪婎偵丄僾儘僙僢僒乕晧壸傗僾儘僙僗/僗儗僢僪偺暘攝偵傛傝惈擻偑偳偺傛偆偵曄壔偡傞偐偵徟揰傪摉偰傑偡丅
DGEMM偱峴偭偨3僞僀僾偺僥僗僩傪丄儊儖僙儞僰丒僣僀僗僞乕偵懳偟偰傕摨條偵峴偄傑偟偨丗
(a)丂僲乕僪傪姰慡偵朞榓偝偣偨帪偺儅儖僠僗儗僢僨傿儞僌偺僗働乕儔價儕僥傿
(b)丂扨堦僾儘僙僗帪偺儅儖僠僗儗僢僨傿儞僌偺僗働乕儔價儕僥傿
(c)丂儅儖僠僾儘僙僗偺僗働乕儔價儕僥傿
偙偙偱戝曄嫽枴怺偄寢壥傪摼傑偟偨丅
恾10偵偍偄偰丄32偺撈棫偟偨僾儘僙僗偑僨乕僞傪慡偔嫟桳偟偰偄側偄嬌抂側椺偱偼丄扨堦僾儘僙僗帪偲斾傋偰扨堦僗儗僢僪偺惈擻偼50%尭彮偟偰偄傑偡丅偙偺僆乕僶乕僿僢僪偵偼傾儖僑儕僘儉揑側暲楍嫞崌偼娷傑傟偰偄傑偣傫偑丄恾11偱帵偟偨栺10%偺扨堦儌僕儏乕儖撪偺嫞崌偲丄L3僉儍僢僔儏偱偺嫞崌丄偍傛傃儊僀儞儊儌儕乕僶儞僪偱偺嫞崌偑娷傑傟偰偄傑偡丅奺儌僕儏乕儖偵偍偄偰2偮偺僗儗僢僪傪幚峴偝偣偨応崌丄傛傝懡偔偺僨乕僞偑L2偍傛傃L3僉儍僢僔儏偱嫟桳偝傟傞偙偲偐傜丄恾摨條偺僆乕僶乕僿僢僪偑30%偺惈擻傪尭彮偝偣偰偄傞偙偲偑恾10偐傜夝傝傑偡丅摨條偵MC偺惈擻尭彮偑丄24屄偺撈棫偟偨僾儘僙僗偱偼20%丄2僗儗僢僪偺12屄偺撈棫偟偨僾儘僙僗偱偼10%惗偠偰偄傑偡丅偙傟傜偺帠偑Q3偺夞摎偱偁傝丄扨堦IL儌僕儏乕儖撪偺儕僜乕僗嫞崌傪嵎偟堷偄偨屻偱偝偊丄L3僉儍僢僔儏偲儊儌儕乕僶儞僪偺嫞崌偑廳梫偱偁傞偙偲傪帵偟偰偄傑偡丅
WM偲斾妑偟偰丄僲乕僪偑朞榓偟偰偄傞応崌丄儌僕儏乕儖撪偺10%偺岠棪埆壔偼塭嬁偁傝傑偣傫丅偟偐偟側偑傜WM偱偼丄OS偼嵟弶偵僴僀僷乕僗儗僢僨傿儞僌偵棅傜偢偵暔棟僐傾傪枮偨偟偰偄偔偺偵懳偟偰丄IL偱偼儌僕儏乕儖偐傜攝抲偟偰偄偔偨傔偵丄僗働乕儕儞僌偺條巕偐傜尒偰偺捠傝偵10%偺儁僫儖僥傿乕偑惗偠傑偡丗偮傑傝丄恾10偺塃恾偵偍偄偰偼丄2僗儗僢僪偵懳偟偰25%偺惈擻懝幐偑偁傝傑偡偑丄恾12傗13偱偼15%掱搙偱偡丅
偙偺僥僗僩偱尒傜傟偨儌僕儏乕儖撪偺10%偺惈擻懝幐偼丄DGEMM偱尒傜傟偨40%傛傝傕彫偝側傕偺偱偡偑(僗僇儔乕惍悢墘嶼儐僯僢僩偑嫟桳偝傟偰偄側偄偺偱摉慠偱偡偑)丄MC傗WM偲斾妑偡傞偲埶慠戝偒側抣偱偡丅
恾10丂丗丂朞榓IL僲乕僪(嵍恾)偲旕朞榓IL僲乕僪(塃恾)偵偍偗傞儊儖僙儞僰丒僣僀僗僞乕偺儅儖僠僗儗僢僪丒僗働乕儕儞僌僥僗僩丅扨堦僗儗僢僪偱偺扨堦僾儘僙僗幚峴帪偲斾妑偟偰丄奺2僗儗僢僪偺16屄偺撈棫偟偨G05SAF屇弌偟偱偼丄栺55%偺懝幐偑惗偠偰偄傞(嵍恾偺愒怓僶乕)丅2僗儗僢僪偵懳偟偰僲乕僪偑旕朞榓偺応崌偼(塃恾偺愒怓僶乕)丄岠棪偼25%懝幐偡傞丅偙傟偼僲乕僪偑朞榓偟偨嵺偺岠棪懝幐55%偺撪丄30%偑懠偺儌僕儏乕儖偲偺L3僉儍僢僔儏偲儊儌儕乕僶儞僪偺嫞崌偵傛傞傕偺偱偁傞偙偲傪帵偟偰偍傝丄塃恾偺愒怓僶乕偱偺暲楍僆乕僶乕僿僢僪偲儌僕儏乕儖儗儀儖偺嫞崌偼摨摍偱偁傞丅嵍恾偺惵怓僶乕偼暲楍僆乕僶乕僿僢僪埲奜偺50%偺岠棪懝幐傪帵偟偰偄傞丅偟偐偟側偑傜L2偺儌僕儏乕儖儗儀儖偺嫞崌偲L3偍傛傃儊僀儞儊儌儕乕偺嫞崌偼丄僨乕僞偺嫟桳偑側偄偨傔偵2僗儗僢僪偺応崌傛傝傕戝偒偔側傞偲峫偊傜傟傞丅
恾11丂丗丂2斣栚偺僗儗僢僪攝抲傪曄偊傞偲儌僕儏乕儖儗儀儖偺嫞崌偑徚偊傞丅摨偠儌僕儏乕儖傊2偮偺僗儗僢僪傪攝抲偟偨応崌偼丄椬愙儌僕儏乕儖傗暿偺僟僀傗暿偺僾儘僙僢僒乕偺応崌偲斾妑偟偰丄10%偺岠棪懝幐偑惗偠傞丅偙傟偼丄DGEMM偱偼40%偩偭偨(恾7)儌僕儏乕儖儗儀儖偺嫞崌偲斾妑偟偰彫偝偄丅巆傝偺惈擻懝幐15%偼丄暲楍僆乕僶乕僿僢僪偲L3/儊僀儞儊儌儕乕偺嫞崌偱偁傞丅
恾12丂丗丂朞榓MC僲乕僪(嵍恾)偲旕朞榓MC僲乕僪(塃恾)偵偍偗傞儊儖僙儞僰丒僣僀僗僞乕偺儅儖僠僗儗僢僪丒僗働乕儕儞僌僥僗僩丅奺2僗儗僢僪偺12屄偺撈棫偟偨G05SAF屇弌偟偱偼丄L3僉儍僢僔儏偲儊儌儕乕僶儞僪嫞崌偺偨傔25%偺懝幐偑惗偠偰偍傝(嵍恾偺愒怓僶乕)丄偙傟偼恾10偺IL偺旕朞榓偺応崌偲摨偠偱偁傞丅旕朞榓偺応崌偺2僗儗僢僪偺寢壥偼(塃恾偺愒怓僶乕)恾11偺僗儗僢僪偑暿偺儌僕儏乕儖偵攝抲偝傟偨応崌偺IL偲摨偠偱15%偺惈擻懝幐偱偁傞丅塃恾偲嵍恾偺愒怓僶乕偺堘偄偼丄L3偲儊儌儕乕僶儞僪嫞崌偱偁傝丄IL偱偼30%偩偭偨傕偺偑偙偙偱偼栺10%偱偁傞丅暲楍僆乕僶乕僿僢僪偑側偄応崌(嵍恾偺惵怓僶乕)丄惈擻懝幐偼IL偺50%偵斾傋20%埲壓偱偁傞丅偙傟偼IL偵偍偗傞僐傾枅偺儊儌儕乕僶儞僪暆偺尭彮偵傛傞傕偺偱偁傞偙偲傪帵偟偰偄傞丅
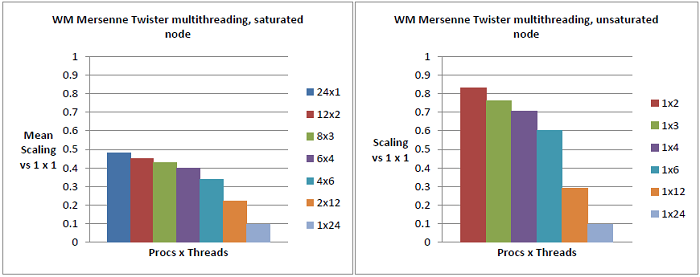
恾13丂丗丂朞榓WM僲乕僪(嵍恾)偲旕朞榓WM僲乕僪(塃恾)偵偍偗傞儊儖僙儞僰丒僣僀僗僞乕偺儅儖僠僗儗僢僪丒僗働乕儕儞僌僥僗僩丅嵍恾偼IL偺恾10偲傎傏摨條側孹岦傪帵偟偰偄傞丅偟偐偟側偑傜塃恾偱偼丄2僗儗僢僪偱偺惈擻懝幐偼15%偺傒偱偁傝丄偙傟偼MC傗IL偱偺僗儗僢僪偑儌僕儏乕儖傪暿偵偟偰偄傞応崌偲摨偠偱偁傞丅偙傟偼WM偵偍偄偰偼丄12僾儘僙僢僒乕/僗儗僢僪埲忋偑幚峴偝傟傞傑偱偼丄僗儗僢僪偼僐傾儗儀儖偺儕僜乕僗傪嫟桳偟側偄偨傔偱偁傞丅
儀儞僠儅乕僋寢榑
寢壥偲偟偰丄IL偱嫟桳偝傟傞儌僕儏乕儖儗儀儖偺儕僜乕僗偼丄崅寁嶼晧壸墘嶼DGEMM偵懳偟偰戝曄戝偒側僀儞僷僋僩傪梌偊傑偡丅旕朞榓側忬懺偱偼丄偙偺僀儞僷僋僩偼僴僀僷乕僗儗僢僨傿儞僌丒僾儘僙僢僒乕(WM)傛傝傕斾妑揑彫偝偄偱偡偑丄捠忢偺僐儞儀儞僔儑僫儖側僾儘僙僢僒乕(MC)傛傝偼戝偒偄偲尵偊傑偡丅偦偺懝幐偼MC偱偼悢%丄WM偱偼70%丄IL偱偼偦偺拞娫揑側40%掱搙偱偡丅儊儌儕乕晧壸僐乕僪偺応崌偼丄惈擻偼儌僕儏乕儖撪嫞崌偵傛傝惂尷傪庴偗傑偡偑丄儊儌儕乕僶儞僪暆偑僐傾偺憹壛偲嫟偵彫偝偔側偭偰偟傑偆偙偲偺曽偑廳梫偱偡丅
僾儘僙僢僒乕偑朞榓偟偰偄側偄応崌偼丄OS偵傛傞僗儗僢僪攝抲億儕僔乕偑惈擻偵偲偭偰廳梫側億僀儞僩偲側傝傑偡丅IL偵偍偄偰偼OS偼儌僕儏乕儖撪偺僐傾傪暿偺暔棟僐傾偲傒側偟偰偟傑偄傑偡偑丄崅寁嶼晧壸傾僾儕働乕僔儑儞偱偼儌僕儏乕儖傪堦偮偺僐傾偲偟偰偲傜偊傞傋偒偱偡丅僨僼僅儖僩偺僗儗僢僪/僾儘僙僗攝抲偼儌僕儏乕儖丄僟僀丄僾儘僙僢僒乕偺弴斣偵朞榓偝偣傞傕偺偱偡丅傛偭偰2僗儗僢僪枖偼僾儘僙僗偺傒傪寁嶼偡傞応崌偵偼丄偙傟傜偺僞僗僋偼僨僼僅儖僩偱偼摨偠儌僕儏乕儖傪嫟桳偟傑偡丅DGEMM偺応崌丄偙傟偼朞榓働乕僗偲摨摍側40%偺惈擻懝幐傪惗偠偰偍傝丄儌僕儏乕儖儗儀儖偺嫟桳偵傛傞塭嬁偑巟攝揑偱偁傞偙偲偑夝傝傑偡丅
偙傟偼WM僾儘僙僢僒乕偱偺攝抲億儕僔乕偲懳徠揑偱偡丅WM偱偼偦傟傜傪12屄偺暔棟僐傾偲傒側偟丄僨僼僅儖僩偱偼僾儘僙僢僒乕撪偺暔棟僐傾傪朞榓偟丄偝傜偵2偮偺僾儘僙僢僒乕偵搉偭偰攝抲偟丄嵟廔揑偵僶乕僠儍儖僐傾偁傞偄偼僴僀僷乕僗儗僢僨傿儞僌傪梡偄傑偡丅偮傑傝僐傾儗儀儖偺儕僜乕僗嫟桳偼IL傛傝戝偒側僀儞僷僋僩傪帵偟傑偡偑(70%)丄12僞僗僋傪挻偊側偄尷傝偙偆偟偨僀儞僷僋僩偼惗偠傑偣傫丅傛偭偰丄崅寁嶼晧壸墘嶼僐乕僪偵懳偟偰偼丄WM偺OS億儕僔乕偺傛偆偵丄2僾儘僙僢僒乕/僗儗僢僪傪摨偠儌僕儏乕儖攝抲偵偡傞昁梫偑側偄尷傝偼丄儌僕儏乕儖傪堦偮偺僐傾傪尒側偆傋偒偱偡丅儊儌儕乕晧壸僐乕僪丄摿偵惍悢僨乕僞偵傛傞傕偺偵懳偟偰偼丄傛傝彮側偄懝幐偱僨儏傾儖僐傾偲傒側偡偙偲偑壜擻偱偟傚偆丅偟偐偟側偑傜偦偺懝幐偼丄2僗儗僢僪偺傒偺応崌偱偝偊偡偖偵尠挊偵側傝傑偡丅
HECToR偱偺幚尡
儀儞僠儅乕僋偵偍偄偰帵偝傟偨MC偵懳偡傞惈擻偺楎壔孹岦偼丄HECToR忋偱偺幚嵺偺傾僾儕働乕僔儑儞幚峴偵偍偄偰峀偔嵞妋擣偝傟偰偄傑偡丅偙偺僙僋僔儑儞偼丄儗儀儖3偺BLAS偲LAPACK傪昿斏偵棙梡偟偰HECToR偱傕擇斣栚偵晧壸偺崅偄傾僾儕働乕僔儑儞偱偁傞丄検巕壔妛僐乕僪CASTEP偺惈擻傪曬崘偟傑偡丅
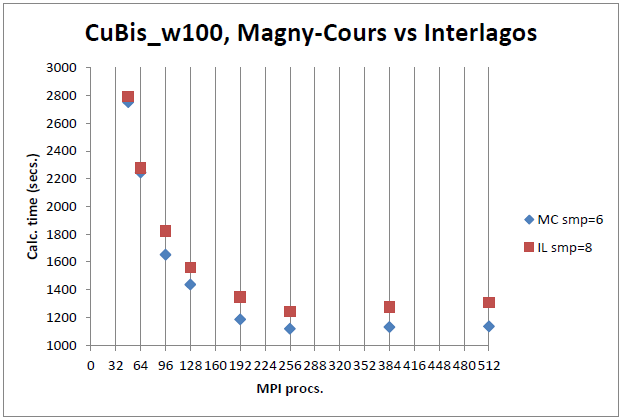
恾14丂丗丂CASTEP儀儞僠儅乕僋1丄摨悢偺僾儘僙僢僒乕偵傛傞IL偲MC偲斾妑丅
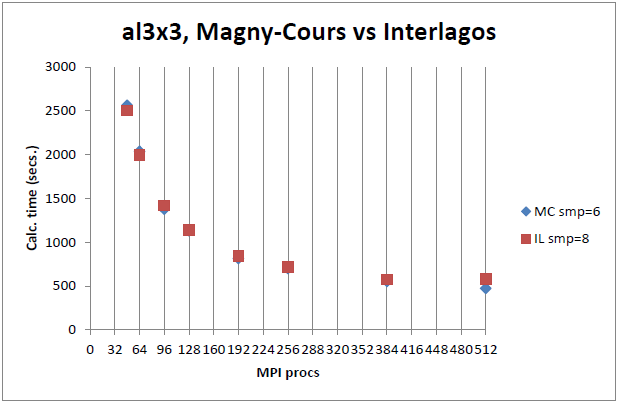
恾15丂丗丂CASTEP儀儞僠儅乕僋2丄摨悢偺僾儘僙僢僒乕偵傛傞IL偲MC偲斾妑丅
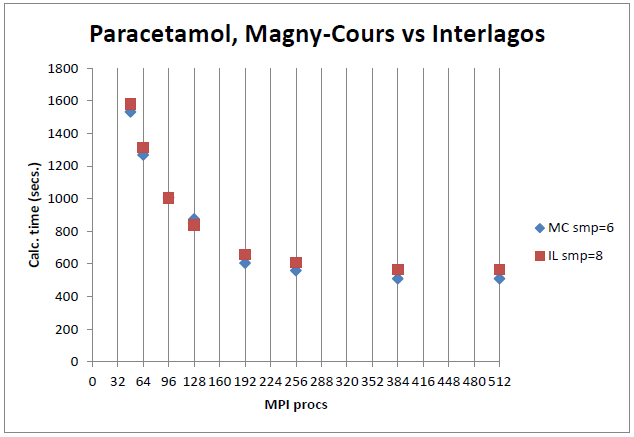
恾16丂丗丂CASTEP儀儞僠儅乕僋3丄摨悢偺僾儘僙僢僒乕偵傛傞IL偲MC偲斾妑丅
恾14-16偺IL偺smp=8偍傛傃MC偺smp=6偼丄System V僔僃傾乕僪儊儌儕乕偺嵟揔壔傪帵偟傑偡丅僲乕僪撪偺奺僐傾偵懳偟偰屄暿偺僙僌儊儞僩傪梡偄偰偄傑偡偑丄斾妑偵偼塭嬁偟傑偣傫丅
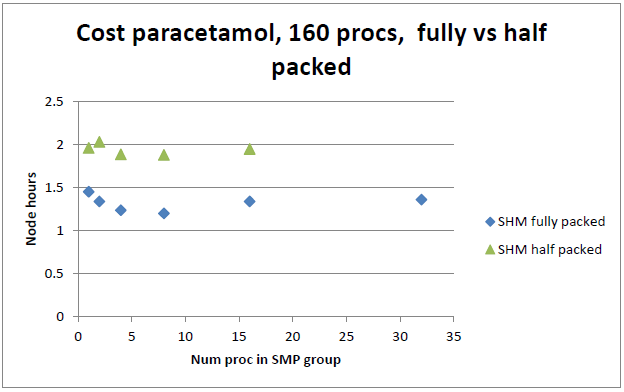
恾17丂丗丂敿朞榓帪(儌僕儏乕儖偵1僾儘僙僗)偺幚峴帪娫偼懙偭偰偄側偄丅嵟傕揔偟偨SMP僒僀僘8偵懳偟偰丄摨僒僀僘僕儑僽偵攞偺僲乕僪傪梡偄傞偵偼栺1.6攞僐僗僩偑妡偐偭偰偄傞丅
恾14-16偱帵偟偨3儀儞僠儅乕僋偺撪2偮偼丄僲乕僪傪朞榓偝偣偨応崌(IL僲乕僪偵32MPI僾儘僙僗丄MC僲乕僪偵24MPI僾儘僙僗)丄IL偼MC傛傝戝偒偔楎傞偙偲傪帵偟偰偄傑偡丅偙傟偼丄AVX/FMA柦椷僙僢僩偵傛傞惈擻偺棙摼偑丄儀儞僠儅乕僋偺僙僋僔儑儞偱帵偟偨傛偆偵僲乕僪偑朞榓偡傞嵺偺懝幐偵媦偽側偄偙偲傪帵偟偰偄傑偡丅恾17偼丄儌僕儏乕儖摉傝1僾儘僙僗(偮傑傝攞偺僲乕僪悢)傪梡偄偰摨偠僕儑僽傪幚峴偟偨応崌偺惈擻偑僐僗僩僷僼僅乕儅儞僗偲偟偰椙偔柍偄偙偲傪帵偟傑偡丅
慡懱偺寢榑
杮儗億乕僩偵偍偗傞Interlagos僾儘僙僢僒乕偵戙昞偝傟傞AMD偺Bulldozer傾乕僉僥僋僠儍乕偼丄Magny-Cours僾儘僙僢僒乕偵戙昞偝傟傞丄L2偁傞偄偼L3僉儍僢僔儏埲忋偺儕僜乕僗偺傒傪嫟桳偡傞揱摑揑側儅儖僠僐傾愝寁偱偁傞埲慜偺悽戙偺AMD僾儘僙僢僒乕丄偍傛傃丄Westmere僾儘僙僢僒乕偵戙昞偝傟傞丄忬懺傪娗棟偡傞儗僕僗僞乕埲奜偺慡偰偺儕僜乕僗傪嫟桳偡傞僀儞僥儖偺僴僀僷乕僗儗僢僨傿儞僌愝寁偺丄拞娫揑側愝寁偱偡丅
偙傟傜偺僾儘僙僢僒乕偼幚峴帪偵朞榓偟偨偲偒偵偦偺條憡偑揥奐偝傟傑偡丗Magny-Cours偼嵟傕暲楍岠棪偑椙偔丄師偵Interlagos偦偟偰Westmere偑懕偒傑偡丅偟偐偟側偑傜丄僾儘僌儔儉偑僔儕傾儖僾儘僌儔儉偐傜擛壗偵僗働乕儖偡傞偐傪尒傞偲丄Interlagos僾儘僙僢僒乕偼丄偦偺僾儘僙僢僒乕傪16暔棟僐傾偲偟偰埖偆偦偺OS偺億儕僔乕偵傛傝偡偖偵埆壔偟傑偡丅杮儗億乕僩偺儀儞僠儅乕僋偐傜柧敀側偙偲偼丄摿偵崅晜摦彫悢揰寁嶼晧壸偺傾僾儕働乕僔儑儞偵偲偭偰丄僾儘僙僢僒乕偼8僐傾偲偟偰傒側偝傟傞傋偒偱偁傝丄8僾儘僙僢僒乕/僗儗僢僪傛傝懡偔偑昁梫偵側偭偨偲偒偺傒丄儌僕儏乕儖傪嫟桳偡傞傛偆偵僞僗僋傪攝抲偡傞傋偒偱偡丅偙偺億儕僔乕偼丄Westmere偺応崌偵偦偺岠壥傪尒偰庢傞偙偲偑弌棃傑偡丅
HECToR僼僃乕僘3偺32僐傾Interlagos傊偺峏怴偵偍偄偰丄埲慜偺僼僃乕僘偺24僐傾Magny-Cours僲乕僪偵斾傋偰偝傜偵儊儌儕乕僶儞僪暆偺儁僫儖僥傿乕偑敪惗偟傑偡丅偙傟偼儊儌儕乕晧壸偺RNG儊儖僙儞僰丒僣僀僗僞乕丒儀儞僠儅乕僋偱尒偨捠傝偱偡丅
Interlagos偺壽戣偲偟偰偼僕儑僽攝抲偑偦偺堦偮偱偡丅HECToR偱偼儐乕僓乕偼丄aprun儔儞僠儍乕傪巊偭偰擛壗偵僾儘僙僗傗僞僗僋傪攝抲偡傞偐傪妛偽偹偽側傝傑偣傫偑丄偦傟偼娙扨偱側偔丄斵傜偺僐乕僪偵懳偟偰嵟揔側愴棯傪慖戰偡傞偨傔偺儀儞僠儅乕僋偑昁梫偲側傝傑偡丅傛傝堦斒揑偵尵偊偽丄椺偊偽nAG SMP儔僀僽儔儕乕偱偼丄嵟揔側惈擻偺偨傔偵OS偺攝抲億儕僔乕偵棅傞偙偲偼傕偼傗偱偒傑偣傫丅僔僗僥儉晧壸傗丄恊榓惈傗丄梡偄傞儖乕僠儞偺僞僀僾偵娭偡傞寁應帪娫儀乕僗偺僗儗僢僪攝抲偺惂屼偲偄偭偨偙偺庬偺僾儘僙僢僒乕偺棙梡曽朄傪丄儐乕僓乕偵柧妋偵傢偐傞傛偆偵偡傞偙偲偑棟憐揑偱偡丅岾塣偵傕偙偺栤戣偼偡偱偵OpenMP4.0偵旛傢偭偰偄傑偡丗椺偊偽丄僱僗僩偟偨儖乕僾偺儕僗僩偲偟偰偺OMP_NUM_THREADS偺怴偟偄巜掕宍幃傗丄OMP_PROC_BIND偲恊榓揑側僾儘僙僢僒乕惂屼丄偍傛傃OMP_PROCSET偵傛傞僐傾偺僲儈僱乕僩僙僢僩傊偺幚峴惂尷側偳偱偡丅