
Asimina Maniopoulou, HECToR CSE Team, nAG Ltd.
August 24, 2011
目次
1.イントロダクション
1.1 VASP
1.2 VASPの並列化
1.3 k点並列化の導入
1.4 k点並列化の実装
2.ベンチマーク
2.1 テストケース1
2.2 テストケース2
2.3 テストケース3
2.4 テストケース4
2.5 テストケース5
3.制限事項
4.応用計算
4.1 酸化インジウムのエピタキシャル超薄膜の誘電関数
4.2 金属性VO2への四価元素ドープの溶解エネルギー
5.結論
1.イントロダクション
本文書は、HECToR上においてVASP v5.2.2に対してk点並列を導入したdCSEプロジェクトに関する報告です。以下において、HECToR上のVASPの性能の重要性とその並列計算について簡単に述べ、その後VASPへのk点並列の導入と実装方法について記します。次にk点並列化されたコードの結果、最後に本プロジェクトによるVASPの性能改善結果を報告します。
1.1 VASP
長年にわたり非経験的電子構造計算はHPCの本流の一つです。その手法は様々に変化してきましたが、CarとParinelloにより1985年に提案された方法[1]が、現在その主流の一つとなっています。この方法は密度汎関数理論[2]を基礎にしています。これはコーン・シャム方程式[3]を、平面波基底を用いて全エネルギーを最小化して解くもので、内殻の電子状態に関しては擬ポテンシャル[4,5]に置き換えて表現します。この方法のレビューは文献[6]に在ります。こうした擬ポテンシャルを用いた全エネルギ計算は、HECToRフェーズ2b上の2010年12月から2011年8月までの運転期間中に稼働率30%以上を占めていました。
この種の計算で最も良く知られたパッケージの一つがVASP:Vienna Ab initio Simulation Packageです[8,9,10,11]。実際にこれはHECToR上で最も良く利用されるパッケージであり、マシンを含めたその利用者にとって高速化は極めて重要です。本レポートは、ある一般的な問題に対して、このコードの並列スケーラビリティを向上させた実装について記述します。この性能改善には、VASP内のk点サンプリングをベースにした並列化手法を用いました。これは類似のコードでは一般的な手法ですが、プロジェクトを開始した最新のVASPバージョン5.2.2ではサポートされていませんでした。本レポートはこの手法により、小規模から中規模の系においてスケーラビリティーが大幅に改善したことを示します。これは、シミュレーション計算が全エネルギー計算だけでない場合に特に重要になります。それは座標最適化を行う場合です。そこでは全エネルギー計算が繰り返し必要となり、こうした計算に掛かる実行時間が計算対象の系のサイズを制限してしまいます。よって多くのコアを利用できる環境では、高い並列スケール性が必要です。
1.2 VASPの並列化
VASPの並列化の詳細は、詳しくは[12]に記載があります。ここでは本レポートに関連する内容について詳細を記述します。
VASP 5.2.2は、バンドと平面波係数およびその両方を同時に用いて並列化およびデータ分散を行います。その分割のやり方はINCARファイル内のNPARタグを用いて制御します。ここでもしNPROC数のコアを用いる場合は、各バンドはNPROC/NPARコアへ分散されます。よってもしNPAR=1であれば、全てのバンドは全プロセッサーへ割当てられ、NPAR=NPROCであれば全てのバンドは一つのプロセッサーへ割当てられます。
NPARは、相反する要件間で調整されるべきものです。全バンドが全プロセッサーへ分散される場合は、平面波擬ポテンシャルで必要となる並列高速フーリエ変換(FFT)に対して高い通信コストが必要となりますが、その他の直交化や対角化等の線形代数演算コストはそれに比べて低いものとなります。一方、NPAR=1の場合はFFTは不要で、高コストの線形代数演算が要求されます。よって最良の性能を得るにはNPARの選択に注意が必要です。それは、対象とする系と、実行するハードウェアおよび利用できるコア数などに依存します。
つまりNPAR使用する場合は、並列FFTと並列対角化間の適切なバランスが必要です。残念ながらこれら演算は、特に多くのVASPユーザーが利用する中規模サイズにおいて、分散メモリー並列アーキテクチャーにおけるスケール性は良好とは言えません[13-14]。
1.3 k点並列の導入
現代的なHPCリソースの性能を引き出す非経験的電子構造計算のやり方は、バンドおよび平面波上の並列化が唯一の方法というわけではありません。CASTEP[15,16]やCRYSTAL[17,18]のようなVASP以外の多くのコードは、k点上の並列化も用いることが可能です。k点は対象とする系の並進対称性から導かれます。この対称性によりk点上の演算は、全てではありませんが多くの場合独立に計算可能です。このことから自然に並列化が導かれ、最近の文献例[20]にもあるようにk点並列化はスケーラビリティを改善します。より一般的に言えば、このような階層的並列化は、極めて大きな数のコアに対してスケールするより一般的な手法の一つです[21]。
しかしながら現状のVASPリリースバージョンはこうしたやり方を採用していません。よって本プロジェクトではVASP 5.2.2へこの並列化レベルを追加しました。ここでは、コアをあるグループ数へ分けて、その各グループがk点のサブセットを計算するように修正しました。このグループの数を、INCARファイル内に新たに設けたKPARタグで指定するようにしました。ここで10個のk点がある場合にKPAR=2を指定すれば、各々5個のk点に対して実行する2個のk点グループが存在することになります。同様にKPAR=5であれば、2個のk点を担当する5個のk点グループに分けられます。このようにKPARは、上述のNPARの役割と似た、k点並列化を指定するものです。現状はKPARは、全k点数および全コア数を割り切れる値に制限されています。これは全コア数に対するNPARの値も同様です。
このk点を用いた並列レベルの導入により、スケーラビリティは改善します。しかしこれを万能薬として見るべきではありません。k点上の全ての演算が並列化されるわけではないため、アムダール則[22]に従って、到達可能なスケーラビリティには限度があります。さらにk点間で完全に並列化されるわけでなく、例えばフェルミレベルの計算がその場合に当てはまります。そしてk点並列化は、新たな通信と同期を生じさせます。
しかしながらk点並列化を最大に妨げる原因は系のサイズです。計算で用いるユニットセルのサイズが大きくなるにつれて、望む精度へ計算を収束させるのに必要なk点数は少なくなり、極限では一つで十分になります。こうしてk点並列に制限が掛かってしまいますが、実際には多くのユーザーは、最近の文献例[23-26]に在るように、一つのk点による収束が可能なほどセルを大きくとりません。よって多くの場合にk点並列化は有用な手法です。これは、全エネルギー計算がより大きな計算の一部でしかない、座標最適化計算のような場合には特にそう言えるでしょう。
1.4 k点並列の実装
元のコードではNPARタグは、バンド内およびバンド間コミュニケーター生成に用いられます。MPIプロセスは、特定のバンドで動作するようにバンド内コミュニケーターにバインドされ、他のバンドとの通信が必要になったときに、バンド間コミュニケーターを通して通信します。またk点並列のために、KPARの値を用いて追加の通信レイヤーを構築しました。KPAR個のk点内通信(COMM)、およびMPIプロセス/KPARこのk点間コミュニケーター(COMM_CHAIN_K)を生成します。COMMコミュニケーターはアサインされたk点に関する全ての情報を持ちます。次に以前のように、COMMコミュニケーターのMPIプロセスはバンド内およびバンド間コミュニケーターに分割されます。K点のループがある場合は、各COMMコミュニケーターは担当するk点に対して繰り返し実行し、すぐにループを抜けてCOMM_CHAIN_Kコミュニケーターが結果を集約します。これが一般的な設計となりますが、開発上で最も難しいのは、全てのk点に関する情報が必要となる場合、例えばフェルミレベル計算における線形テトラへドロン法の実装です。
非対称k点グリッドを用いる場合は更に注意が必要で、k点を参照するある特定の値がある場合、コミュニケーターが担当していない場合でも、全てのコミュニケーターにその量は保存されていなければなりません。ハートレー・フォック交換項の場合は特に複雑で、これらはネストしたk点ループを含んでいます。これはハートレー・フォックを用いない場合に比べて追加の通信が必要とされますが、少なくとも検証したケースではスケール性能を妨げるものではありませんでした。
I/Oに関しては、場合に依りますが、マスターノード上の全ての関連情報を伝えるか、書き込みのために各COMMコミュニケーターの'リーダー'を持つかのいずれかを用いました。
2.ベンチマーク
本レポートでは以下の5つのテストケースを議論します:
- Test1:パラジウム32原子中の水素欠陥。10k点を使用。
- Test2: 酸化鉛(リサージ、α-PbO)のユニットセル。全4原子。108k点を使用。
- Test3: PbOのユニットセル。128k点を使用。
- Test4: 酸化鉛(リサージ、α-PbO)のユニットセル。全4原子。24k点を使用。
- Test5: フォノン計算。20k点を使用。
テスト1から3ではPBE交換相関汎関数を用い、k点メッシュはMonkhorst-Pack法で生成しました。テスト4と5は、ハートレー・フォック計算を含み、k点メッシュはガンマ点計算(Gamma centered)で生成しました。フォノン計算以外は1点エネルギー計算です。
全ての計算はHECToRフェーズ2bシステムで計算しました。このシステムはCray XE6大規模システムです。ノードはAMD Magny-Coursプロセッサーで、2.1GHzの24コアから成ります。各ノードには32GBメモリーが搭載され、CrayのGeminiネットワークを介したノード間通信が装備されています。より詳細にはHECToRのウェッブサイト[7]を参照してください。
表(1)、(3)、(5)、(7)、(8)において、VASP 5.2.2と新しいk点並列版の性能比較を行い、新規コードのスケール性能を議論します。各ケースにおいて元のコードとk点並列コードは、k点グループ数に関して比較されます。実行時間は、エネルギー最適化時間だけではなく、全経過時間を示します。
表(2)、(4)、(6)、(9)において、同じコア数を用いた場合の、最適なNPARを用いたVASP 5.2.2とk点並列版の性能比較をします。ここで複数k点の場合に大規模コアを有効に利用できることを実証します。
VASPの効果的な実行には、最適なNPARを使うことが重要です。元のコードにおける最適なNPAR値は利用可能なコア数に依存します。k点並列版においては、最適なNPAR値はk点ループ内のコア数に依存します。ここで、元のコードでコア数xの場合にNPAR値が最適であったならば、k点並列版を用いる場合にNPAR値は、n個のk点グループに対しては、n*x個のコアに対して最適となります。
2.1 テストケース1
系は水素欠陥を持つパラジウム32原子で、10k点を使用し、PBE交換相関汎関数[27,28]を用いました。
| Test case 1 | Cores | Times(secs) | Speedup |
| VASP 5.2.2 | 64 | 298.187 | 1 |
| KPAR=2 | 128 | 159.982 | 1.863 |
| KPAR=5 | 320 | 75.357 | 3.956 |
| KPAR=10 | 640 | 47.795 | 6.239 |
表1はk点並列版が320コアまで十分にスケールしていることを示し、元のコードと比べ2倍高速化しています(表2を参照してください)。
| Test Case 1 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 128 | 206.517 | 1 |
| KPAR=2 | 128 | 158.686 | 1.301 |
| VASP 5.2.2 | 320 | 146.197 | 1 |
| KPAR=5 | 320 | 75.201 | 1.944 |
| VASP 5.2.2 | 640 | 147.606 | 1 |
| KPAR=10 | 640 | 47.795 | 3.088 |
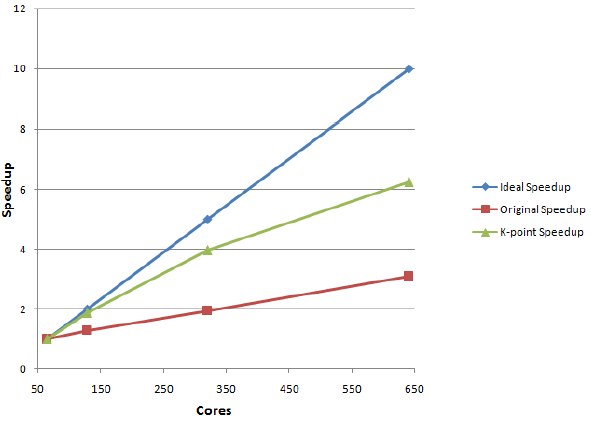
図1:テストケース1の速度向上(64コアを1とした)。
2.2 テストケース2
系は酸化鉛(リサージ、α-PbO)のユニットセルで、全4原子から成り、108k点を用いました。
| Test Case 2 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 144 | 2141.206 | 1 |
| KPAR=2 | 288 | 1097.981 | 1.950 |
| KPAR=3 | 432 | 766.196 | 2.794 |
| KPAR=4 | 576 | 607.69 | 3.524 |
| KPAR=6 | 864 | 410.018 | 5.222 |
| KPAR=9 | 1296 | 278.585 | 7.686 |
| KPAR=12 | 1728 | 215.757 | 9.924 |
| KPAR=18 | 2592 | 150.177 | 14.258 |
| KPAR=27 | 3888 | 105.563 | 20.284 |
| KPAR=36 | 5184 | 87.569 | 24.452 |
| KPAR=54 | 7776 | 65.332 | 32.774 |
| KPAR=108 | 15552 | 41.055 | 52.154 |
表3はk点並列版がさらに3888コアまでスケールすることを示し、1738コアにおいて同数コアにおける元のコードよりも7倍高速化しています(表4を参照してください)。
| Test Case 2 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 288 | 1530.244 | 1 |
| KPAR=2 | 288 | 1097.981 | 1.394 |
| VASP 5.2.2 | 432 | 1348.436 | 1 |
| KPAR=3 | 432 | 766.196 | 1.76 |
| VASP 5.2.2 | 576 | 1473.4 | 1 |
| KPAR=4 | 576 | 607.69 | 2.425 |
| VASP 5.2.2 | 864 | 1562.76 | 1 |
| KPAR=6 | 864 | 410.018 | 3.811 |
| VASP 5.2.2 | 1296 | 1899.499 | 1 |
| KPAR=9 | 1296 | 278.585 | 6.818 |
| VASP 5.2.2 | 1728 | 1532.32 | 1 |
| KPAR=12 | 1728 | 215.757 | 7.1021 |

図2:テストケース2の速度向上(144コアを1とした)。
2.3 テストケース3
系はPbOで、126k点を用いました。元のコードは144コアで速度を落としています。k点並列版は1008コアまで十分にスケールしています。
| Test Case 3 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 144 | 120.388 | 1 |
| KPAR=2 | 288 | 69.208 | 1.740 |
| KPAR=3 | 432 | 48.315 | 2.492 |
| KPAR=6 | 864 | 30.234 | 3.982 |
| KPAR=7 | 1008 | 27.402 | 4.393 |
| KPAR=9 | 1296 | 40.443 | 2.976 |
| Test Case 3 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 288 | 130.688 | 1 |
| KPAR=2 | 288 | 69.208 | 1.888 |
| VASP 5.2.2 | 432 | 122.236 | 1 |
| KPAR=3 | 432 | 48.315 | 2.530 |
| VASP 5.2.2 | 864 | 320.196 | 1 |
| KPAR=3 | 864 | 30.234 | 10.591 |
| VASP 5.2.2 | 1008 | 318.516 | 1 |
| KPAR=7 | 1008 | 27.402 | 11.624 |
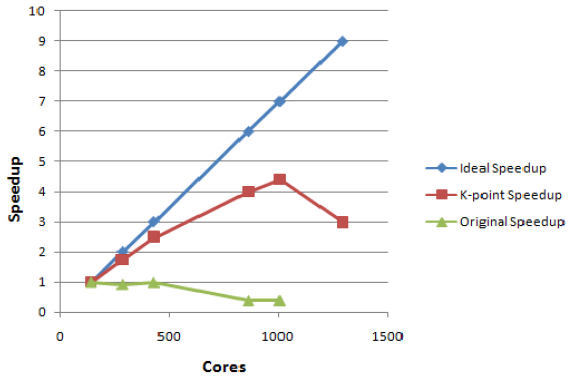
図3:テストケース3の速度向上(144コアを1とした)。
2.4 テストケース4
系はPbOで、24k点を用いました。この計算にはハートレー・フォック交換積分計算が含まれます。光学特性も議論されます。
| Test Case 4 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 256 | 14674.49 | 1 |
| KPAR=2 | 512 | 7578.614 | 1.936 |
| KPAR=3 | 768 | 4979.435 | 2.947 |
| KPAR=4 | 1024 | 3790.061 | 3.871 |
| KPAR=6 | 1536 | 2552.615 | 5.749 |
| KPAR=8 | 2048 | 1944.401 | 7.548 |
| KPAR=12 | 3072 | 1399.796 | 10.953 |
| KPAR=24 | 6144 | 1053.134 | 13.93411 |
元のコードは512コア以上の場合は実行できませんでした。K点並列版は3027コアまでスケールしています。
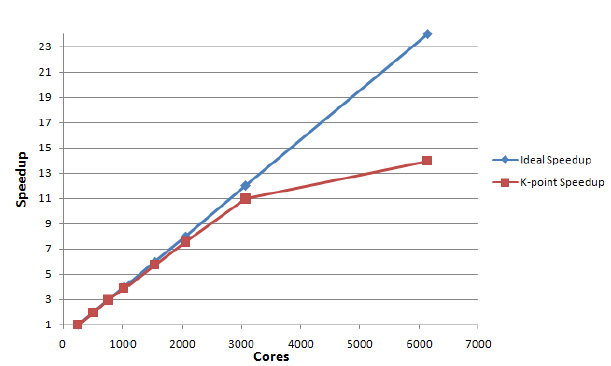
図4:テストケース4の速度向上(256コアを1とした)。
2.5 テストケース5
フォノン計算において、20k点を用いました。元のコードの計算では、NPARは総コア数と同じ数にしました。これはセクション1.2での議論から、線形代数演算が並列化出来ず、FFTのみ並列化しているためです。k点並列版においてもNPARは、1つのk点グループに対して総コア数を設定しました。
| Test Case 5 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 32 | 399.929 | 1 |
| KPAR=2 | 64 | 221.94 | 1.802 |
| KPAR=4 | 128 | 112.407 | 3.558 |
表9は、32コア数よりも大きい場合は元のコードが全くスケールしないことを示しています。FFT通信コストがボトルネックとなり、400秒以下で実行することは不可能です。
一方表8は、k点並列版では、4倍のコア数を用いて3.6倍の112秒で実行を完了しています。問題は、このテストの場合は640(k点数(20)×32)を用いる事も出来るはずですが、128コアより大きなコア数を使えないことです。これは計算中にk点メッシュが新たに生成されることが原因です。KPARがこの新しいメッシュのk点数を割り切れるならば、効率的な実行が可能ですが、そうでない場合は問題が生じます。この場合は、元のk点メッシュではk点数は20でしたが、二番目には52、三番目は68と変化していました。これら3つの数字の公約数は2と4です。よってKPARとして使える最大の数は4です。
| Test Case 5 | Cores | Time(secs) | Speedup |
| VASP 5.2.2 | 64 | 603.294 | 1 |
| KPAR=2 | 64 221.94 | 2.718 | |
| VASP 5.2.2 | 128 | 2477.339 | 1 |
| KPAR=4 | 128 | 112.407 | 22.039 |
| VASP 5.2.2 | 160 | 4651.663 | 1 |
| KPAR=5 | 160 | 64.96 | 71.608 |
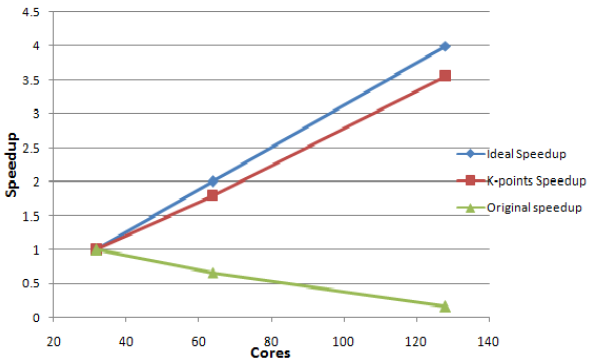
図5:テストケース5の速度向上(32コアを1とした)。
3.制限事項
ここで、開発されたk点並列版の制約について記載します。
- k点グループ数(すなわち、KPARタグの値)は、コア総数とk点数を同時に割り切れる数でなくてはならない。新たにk点メッシュが生成された場合も同様である(セクション2.5を参照してください)。
- 出力ファイルasprun.xmlは生成されない。
- k点並列版ではnon-collinearスピン計算は利用できない。
4.応用計算
UCLの研究者が、本コードを効率的に用いてある物理系の研究をしました。Maniopoulou A., Grau-Crespo R., Davidson E., Walsh A., Bush I.J., Woodley S.M.らの関連論文が草稿中です。ここではk点並列版を用いた、Aron WalshおよびRicardo Grau-Crespo博士により研究された2つの事例の結果を概説します。
4.1 酸化インジウムのエピタキシャル超薄膜の誘電関数
半導体材料の光学特性計算は、ブリルアンゾーンのk点に関して収束性が難しい問題です。光電デバイスで透明導電性酸化物として用いられる、酸化インジウムのエピタキシャル超薄膜の光学特性変化がその重要な例です。誘電関数の収束性は、k点に関する高周波誘電率(ε∞)の変化で評価されます。
HECToRフェーズ2b上で、標準的なコンパイルをされたVASP 2.5を用いると、12時間のキュー制限で可能な最大のk点数は、96コアを用いた2×2×2でしたが、k点並列版では6×6×6まで増やすことが出来て、1536コアまでスケールしました。これは、HECToRフェーズ2bでk点並列版のみが計算を収束させることが出来る事例です。
4.2 金属性VO2への四価元素ドープの溶解エネルギー
VO2に対する3種のドーパントの安定性が議論されました。純粋なVO2とドープされたものは室温で金属性のため、その計算には多くのk点が必要となります。
VASPのk点並列版を用いてGrau-Crespo博士は、純粋のVO2に対して4×4×4(18既約k点)および8×8×8(75既約k点)のメッシュを試しました。後者の計算にはHECToRフェーズ2bの360プロセッサーが用られ、24プロセッサーを用いた元のコードと比較して13倍の速度向上を示しました(理論的に予測される性能向上は15倍です)。ドープされたセルの計算は全168プロセッサーで計算され、各KPAR=7グループ(各々3つのk点を含む)は24プロセッサー毎に並列実行されました。各イオンに働く力が全て0.01eV/Å以下になる条件で、全座標が最適化されました。
5.結論
k点並列コードがより効率的に計算サイクルを使用していることを、テストケース2.1、2.2および応用例4.1で実証することが出来ました。この他元のコードが、大規模コアのテストケース2.3、2.5では動作しないことや、時間制限によりHECToR上では実行不可能であることを応用例4.2で示しました。全てのケースにおいてk点並列版が動作することが示されました。
謝辞
このプロジェクトは、nAG Ltd.が運営するHECToRの分散計算科学および工学(CSE)サービスの基に実行されました。英国の国立スーパーコンピューティング・サービスである、HECToR:英国リサーチ・カウンシル・ハイエンド計算サービスは、リサーチ・カウンシルを代行するEPSRCが管理しています。そのミッションは英国学術界の科学および工学の研究支援です。HECToRスーパーコンピューターは、UoE HPCx Ltd.およびnAG Ltd.のCSEサポートサービスにより管理運営されています。
著者は、本レポートへの貢献に対して以下の方々に感謝いたします。
Ian J. Bush博士に対して、本作業におけるサポート、実りある議論、コード開発中の修正、本レポートの精査と修正を頂いたことを感謝いたします。またHPC材料化学コンソーシアムとの協力を取り持っていただいたことにも感謝いたします。
Scott Woodley博士、Ricardo Grau-Crespo博士、Erland Davidson修士、およびAron Walsh博士に議論頂いたこと、テストケースとベンチマークの提供、およびk点並列版の結果精度の確認、セクション4でのコード適用に対して感謝いたします。
文献
| [1] | Car,R., and Parrinello, M., 1985, Phys. Rev. Lett. 55,2471 |
| [2] | Hohenberg, P., and Kohn, W., 1964, Phys. Rev. 136, 864B |
| [3] | Kohn, W., and Sham, L.J., 1965, Phys. Rev. 140, 1133A |
| [4] | Phillips, J.C., 1958, Phys. Rev. 112, 685 |
| [5] | Cohen, M.L, and Heine, V., 1970, Solid State Physics Vol 24,37 |
| [6] | Payne, M.C., Teter, M.P., Allan, D.C., Arias, T.A., and Joannopoulos, J.D., 1992, Rev. Mod. Phys.,64, 1045 |
| [7] | http://www.hector.ac.uk/service/hardware/ |
| [8] | Kresse, G., and Hafner, J., 1993, Phys. Rev. B. 47, 558 |
| [9] | Kresse, G., and Hafner, J., 1994, Phys. Rev. B., 49, 14251 |
| [10] | Kresse, G., and Furthmller, J., 1996, Comput. Mat. Sci., 6, 15 |
| [11] | Kresse G., and Furthmller, J., 1996, Phys. Rev. B, 54, 11169 |
| [12] | http://cms.mpi.univie.ac.at/vasp/vasp/vasp.html |
| [13] | http://www.hpcx.ac.uk/research/hpc/technical_reports/HPCxTR0303.pdf |
| [14] | http://www.hpcx.ac.uk/research/hpc/technical_reports/HPCxTR0510.pdf |
| [15] | Segall M.D., PLindan P.L.D., Probert M.J, Pickard C.J., Hasnip P.J., Clark S.J., Payne M.C J.Phys.: Cond.Matt. 14(11) pp.2717-2743 (2002) |
| [16] | Clark S.J., Segall M.D., Pickard C.J., Hasnip P.J., Probert M.J., Refson K., Payne M.C., Zeitschrift fr Kristallographie 220(5-6) pp.567-570 (2005) |
| [17] | Dovesi R., Orlando R., Civalleri B., Roetti R., Saunders V.R., and Zicovich-Wilson C.M., Z. Kristallogr. 220, 571 (2005) |
| [18] | Dovesi R., Saunders V.R., Roetti R., Orlando R., Zicovich-Wilson C.M, Pascale F., Civalleri B., Doll K., Harrison N.M, Bush I.J., DArco p, and Llunell M., CRYSTAL09 (CRYSTAL09 User's Manual. University of Torino, Torino, 2009). |
| [19] | Ashcroft, N.W., and Mermin, N.D., 1976, Solid State Physics (Holt Saunders, Philadelphia) |
| [20] | Bush, I.J, Tomic, S., Searle, B.G., Mallia, G., Bailey, C.L., Montanari, B., Bernasconi, L., Carr, J.M., Harrison, N.M., Proc. R. Soc. A 8 July 2011 vol. 467 no. 2131 2112-2126 |
| [21] | Bush, I.J., "The view from the high end: Fortran, parallelism and the HECToR service", ACM SIGPLAN Fortran Forum, Volume 29 (3) Association for Computing Machinery - Nov 12, 2010 |
| [22] | Amdahl, G., 1967, AFIPS Conference Proceedings (30): 483485 |
| [23] | Smith, C., Fisher T.S., Waghmare U.V., and Grau-Crespo. R. Physical Review B 82, 134109 (2010). |
| [24] | Chauke H.R., Murovhi P., Ngoepe P.E., de Leeuwand N.H., Grau-Crespo. R Journal of Physical Chemistry C 114, 15403-15409(2010). |
| [25] | Grau-Crespo R., Smith K.C., Fisher T.S., de Leeuw N.H., and Waghmare. U.W Physical Review B 80, 174117 (2009) |
| [26] | Grau-Crespo R., Cruz-Hernndez N., Sanz J.F and de Leeuw. N.H. Journal of Materials Chemistry 19, 710-717 (2009). |
| [27] | Perdew J.P, Burke K., and Ernzerhof. M. Phys. Rev. Lett., 77:3865, 1996. |
| [28] | Perdew J.P., Burke K., and Ernzerhof. M. Phys. Rev. Lett., 77:3865, 1996. |