
Mark Richardson, Numerical Algorithms Group Ltd.
Professor Martyn Chipperfield, School of Earth and Environment, University of Leeds
概要
TOMCATは大気化学および大気輸送プロセスのシミュレーションコードです。これは共有メモリー並列を起動するオプションを持ち、分散メモリーモードで実行します。このコードの、高解像度ケースをシミュレーションする場合について性能が調査されました。データ入出力量の増大のために、そのファイルアクセス・パターンが性能に影響を与えることが懸念されています。
コード性能の実測値から、十分に最適化されていることが示されていますが、その中で繰返し毎の計算フェーズの50%を一つのルーチンが占めています。しかしながらそのコード領域はファイルアクセスパターン計算です。この分析が示すところは、データ入出力の実際のコストは小さいが、出力前のデータ収集と入力後のデータ分配の性能が効率的でないことを示しています。
改善のために4つの関数が選ばれ、その内2つが劇的に性能改善しました。例えば、計算領域の標高プロファイルをレポートする関数は、オリジナルの形式では40秒程度のオーバーヘッドを持っていました。その改良バージョンは繰り返し毎のオーバーヘッドが0.05秒以下になりました。これら2つの関数は現状では多くは利用されていませんが、その改良バージョンはコードの他の場所で、別の関数と置き換えることも可能です。
目次
- 1. イントロダクション
- 2. Task1.1:現状の解析
- 3. Task1.2:性能改善のためのコード再構築
- 4. Task2.1:並列I/O
- 5. NetCFD機能の調査
- 6. 結論
1. イントロダクション
このプロジェクトは、nAG Ltd.が運営するHECToRの分散計算科学および工学(CSE)サービスの基に実行されました。英国の国立スーパーコンピューティング・サービスである、HECToR:英国リサーチ・カウンシル・ハイエンド計算サービスは、リサーチ・カウンシルを代行するEPSRCが管理しています。そのミッションは英国学術界の科学および工学の研究支援です。HECToRスーパーコンピューターは、エジンバラ大学、HPCx Ltd.およびnAG Ltd.のCSEサポートサービスにより管理運営されています。
本プロジェクトは大気プロセスシミュレーションコードTOMCAT(www.see.leeds.ac.uk/tomcat)の開発のために企画されました。本レポートは高解像度モデルにおけるコード性能分析の詳細を記しています。シミュレーション時間の改善が可能なコード個所の特定に、繰返し毎の実行時間とCray performance analysis toolを用いました。その改良によりスケーラビリティの改善も期待されます。この最終レポートはここで実行された4つの作業について記述します:一つは、高解像度モデルにおけるコードの振る舞いの分析で、その他は、性能改善のための変更、TOMACTのファイル操作手法の修正、および本プロジェクト開始前に組み込まれたNetCFDの機能に関する報告です。
現状のHECToRフェーズ3システム(Cray XE6)は、5632個のAMD Interlagosプロセッサから成ります。注意すべき事として、初期のTOMCATプロジェクトでは異なるフェーズのマシンを用いており、作業はそのハードウェアにマッチしたものだったことです。例えばMPIタスクは不飽和なノードで分散されて、OpenMPはそれ以外のアイドルするコアへ割当てられていました。HECToRフェーズ3はプロセッサ間の通信にCray Geminiインターコネクトを用いますが、コア当たりのメモリーは1GBしかありません。
シミュレーションの限られたステップ数(96)での解析にはCray PATツールを用いました。3種の異なるMPI領域分割(MPIタスクが80,160,400)に対して時間計測と解析を行いました。MPI_WTIMEによる計測時間から、最も負荷の高い処理を得ました。Cray PATのファイルアクセス・トレース機能を用いて、シミュレーション中の様々な外部ファイルの入出力量を決定しました。
TOMCATは化学移流輸送コードです。これは化学およびエアロゾルデータを処理し、全地球大気内の化学種の時間発展と分布を導き出します。以前のプロジェクトでは[1]、T42ケース(2.8°x2.8°)を用いていました。この時は幾つかの重要なルーチンの再構築と、MPI通信データの準備を行う関数の幾つかの修正によって、TOMCATの性能は改善しました。第2のプロジェクト[2]では、ノード当たりのMPIタスク数を削減して残りのアイドルするコアで5つのループ計算を共有することによって、性能を改善するためにOpenMP機能が追加されました。その結果、NUMAノード当たり1MPIタスクで4OpenMPスレッドを用いれば、128MPIタスクの場合よりも有効に128コアを活用できました。
本プロジェクトではより高解像度のT106(1.2°x1.2°)を用います。これは最初に、高解像ケースにおける80MPIタスク分割に用います。以降これを”1-by-1”と呼ぶことにします。これは実際には60レイヤーの320x160グリッドボックスであって、1度間隔になるわけではありませんが、T42より約9倍の計算セルを持ちます。
2. Task1.1:既存ソフトウェアの解析
最初に高解像度ケースにおけるこのソフトウェア・バージョンの性能プロファイルを解析します。様々なやり方が有りますが、一つはユーザが定義するタイミングレポートで、もう一つがCray PATを利用する方法です。後者は性能データ記録の上で選択的な測定が可能です。
ソースコードにはMPI_WTIME呼出しが含まれており、経過時間と繰返し毎の時間がレポートされます。タイミングレポートの検討から、繰返し時間は一様でなく、幾つかの繰返しの経過時間はその他多くの繰返しに掛かる時間よりも15倍程度大きなものになっています。
表1はコード最適化前の性能データを示します。これにはMPIとOpenMPのスケール性能情報が含まれます。本プロジェクトの多くは、単一スレッドのMPI配置に対して行われます。繰返し毎の経過時間の違いは、参照データのサイクリックな読込、シミュレーションの初期化及び終了といったファクターで生じます。
| MPI | OMP | NPROCI | NPROCK | MYLAT | MYLON | NIV | NBox per patch |
Time for initial step |
Time per interval step |
Time per 2 hour step |
Time per 6 hour step |
Time per 12 hour step |
Time per final step |
| 80 | T1 | 5 | 16 | 64 | 10 | 60 | 39040 | 332 | 1.00 | 3.37 | 5.7 | 15.21 | 13.59 |
| T2 | 345 | 0.73 | 2.18 | 4.1 | 17.58 | 13.87 | |||||||
| T4 | 359 | 0.55 | 1.42 | 3.6 | 16.08 | 14.50 | |||||||
| 160 | T1 | 5 | 32 | 64 | 5 | 60 | 19520 | 327 | 0.60 | 1.82 | 3.2 | 6.57 | 5.64 |
| T2 | 345 | 0.49 | 1.38 | 2.9 | 6.35 | 5.91 | |||||||
| T4 | 393 | 0.37 | 1.00 | 2.7 | 6.99 | 6.33 | |||||||
| 400 | T1 | 5 | 80 | 64 | 2 | 60 | 7808 | 323 | 0.47 | 0.94 | 2.2 | 7.95 | 7.02 |
| T2 | 338 | 0.44 | 0.71 | 2.1 | 7.30 | 7.25 | |||||||
| T4 | 388 | 0.36 | 0.72 | 2.2 | 8.30 | 7.99 |
ここでスケール性能を考えると、ステップ(中間ステップ)当りの時間はMPIタスクの増加に伴い非線形に減少しています。シミュレーションの最後のステップ時間はMPIタスク数に依存していません。ここでは大量の出力が発生している模様です。これら測定では、4コア毎に1MPIタスクになるように分散しました(aprunコマンドのオプション”-d 4”を用います)。こうするとOMP_NUM_THREADSを1,2,3,4とすることが出来ます。よってHECToRの最初のフェーズと同様にMPIプロセス当たり最大4GBまで割当てられます。
このシミュレーションは96回の繰返しを計算しますが、最初の一回は全てのMPI配置で約330秒掛かり、80MPIタスクの場合、中間繰返し毎の時間は約1秒です。従って約450秒の全実行時間がベースラインとして記録されています。中間の繰返し毎時間はファイルアクセスが最小あるいはゼロなので、スケール性はより明確です。
この解像度では、ハイブリッド並列実装が行われた低解像度で示された、OpenMPスレッドのスケール性が保持されています。実用計算では、3650x96オーダーの繰返しを必要とするシミュレーションは10年掛かるかもしれません。本調査の96回の繰返しで重大となる特徴が、実用計算でも同様に影響することはないかもしれません。
コードプロファイル測定のためにPerftoolsモジュールをアクティブにしました。このツールは高負荷部分の特定とファイル関連の追跡情報を採取することが出来ます。図1に示したように様々なやり方が有りますが、これらが本プロジェクトで用いる主要な方法です。
図1:Cray PATで用いるオプション
pat_build -O apa tomcat.exe (基本的なサンプリング測定) pat_build -g sysio,stdio,ffio,aio ?w ?t TraceList.txt tomcat.exe pat_build -g mpi,omp -u tomcat.exe pat_build -g mpi -w -t TraceList.txt tomcat.exe
Cray PATはソフトウェアの実行時間の詳細を調べるために用いられます。サンプリング測定は、より詳細な調査が必要になると考えられるルーチンを検出するために用いられます。トレース測定は、これら特定されたサブルーチンと他のサンプリング測定で示されたルーチンに焦点を当てて追跡するのに用います。さらに、外部ファイル入出力時の容量と速度をレポートするためにioグループを用いて測定をします。
中間の繰返しは経過時間が短いため、デフォルトでは僅かなサンプリングしか記録されません。ツールが何時データを記録するかを制御することによって詳細な解析が可能です。サンプリングレートは、サンプリング間隔を短くすることによって増やすことが出来ます。こうしてCray PATがアクティブである間に生じるサンプリング数を多く採取することが可能です。デフォルトの間隔(PAT_RT_INTERVAL)は10000(すなわち10ms)であるので、これを100マイクロ秒にすると1秒毎に10000サンプルが生じます。特定領域のサンプリングを定義するAPIもあります。測定ログファイル内にその領域のサンプル数(トレース測定であれば時間が)が示されます。サンプリングレートを増やすと測定実行が遅くなり、より大きなログファイルが生成されます。
“pat_record”は、どこでサンプリングあるいはトレース情報をアクティブにするかを選ぶのに用います。サンプリング測定情報を用いた情報採取は、個別の特定の領域毎にアクティブにされて、異なる採取領域に対して複数回実行されます。pat_recordの呼出しはプログラムの最初に行われ、情報採取はされません。それは予め決められた地点においてアクティブにされて、プロファイルが採取されます。これは収集されたデータ量を削減しますが、実行速度が速くなることはありません。これは何時指定した領域に入ったかを捕捉するために、より高い頻度で連続的なサンプリングが生じます。
特定の1繰返しに情報採取を絞ると、負荷のばらつきが明らかになります。中間の繰返し(特殊な処理を持たない標準的な時間ステップ)に対しては、繰返しの実行時間の50%がCONSOMで占められており、この関数の改善が試みられました。
3. Task1.2:性能向上のためのコード再構築
サブルーチンCONSOMは高負荷ルーチンに特定されています。本セクションではその構造を記述します。これは対流によるミキシング・トレーサの関数です。これまでこのサブルーチンはファイルにアクセスしており、それがコードの構造を表現します。通常開発者は、外側ループに配列次元の最後のインデックス(メモリー上最も長いストライド)を割当ててループ構造を組み立てます。このサブルーチンでは、外側ループは緯度(2番目のインデックス)です。理由は、緯度毎の対流項が計算後にディスクに保存されるためです。その計算は、次の緯度に移動する前にすべてのトレーサに対して標高と経度の平面内で実行されます。最内側ループは経度である(連続的なデータの)最初のインデックスで繰り返されます。
各サブルーチンがどのようにコンパイルされたかを表示するフラグを使うと、図2に示した結果が示されます。コンパイラはDOループのネストが多すぎると通常メッセージを示します。ループIとLの順序を入れ替えたというメッセージも表示されます。
図2:サブルーチンCONSOMのコンパイル出力の抜粋 % ftn -r8 -Minfo -Mneginfo -Minline,reshape -fast -Mextend -byteswapio -mp=nonuma
-c -o consom.o consom.f
consom: 62, Generated 3 alternate versions of the loop Generated vector sse code for the loop 76, Loop interchange produces reordered loop nest: 77,76,78 78, Generated 3 alternate versions of the loop Generated vector sse code for the loop 111, Memory zero idiom, loop replaced by call to __c_mzero8 116, Loop interchange produces reordered loop nest: 117,116,118
コンパイラの最適化に合わせてコードを書き換え、再度コンパイルすると同様のメッセージが出ますがこの時はループのネストは元の順序になります。以上の検証を踏まえて、CONSOM改善のための唯一の手法はキャッシュラインブロッキングのようなハードウェア依存のやり方であると結論づけました。しかしながら、それに必要な作業やポータビリティを考慮すると明らかな利点はありませんでした。
4. Task2.1:並列IO
4.1 並列IOタスクの背景
本セクションでは、外部ファイルの扱いに関する4種の特性について解析して報告します。ここで、3つの出力と1つの入力が有ります。出力関数のGBSTATとSORZMはデータの保存と通信においてほぼ同一の特性を持ちます。もう一つの出力関数PPWRITは入力関数PPREADと極めて似ていますが、処理が逆になっています。
関数GBSTATは地上観測所の経度と緯度の情報をレポートします。通常はこれは実験データを得た任意の場所を意味します(即ちシップボーンやエアボーン観測を含みます)。関数SORZMは、特定のスカラー値の周囲の平均を(即ち緯度に平行な直線に沿って)計算し、子午線平面内の結果を保存します。これらは共に”ギャザー”タイプの機能で、最初のものは補間計算、次のものは緯度に関する総和です。これらギャザー演算は負荷が高く、指定の全ての場をMPIタスク0へ転送する作業を含みます(実際に幾つかの場はこうして処理されます)。
関数PPREADは計測の最初に実行され、マスタータスクによる入力手法を用います。4番目のPPWRITはファイルへデータを書き込むのに用いられます。これら2つの関数は事実シリアル入力とシリアル出力を行います。ただし読込後のデータ分散および書込み前の他のMPIタスクからMPIタスク0へのデータ収集を実行する、複雑なラッパーも組み込まれています。
以下の3つのサブセクションでは、各関数の詳細と現状の手法の解析および代替手法について説明します。より詳細な説明は主開発者による報告に譲ります[3,4,5]。
4.2 地上観測所プロファイルのレポート
関数GBSTATは6時間毎の出力という特定のケースで実行されます。地上観測所に関して異なる数を出力するシミュレーションもあります。1時間毎に300サイトのデータを出力する測定もあります。
本作業ではGBSレポートを人為的に30分毎に実行し、既存の手法の弱点を顕在化させます。その変更の特性は表2に示します。
4.2.1 既存実装の概要
アルゴリズムは4つのセクションから成ります:最初のセクションはトレーサと場のデータに依るループが在り、その中でこれらはマスターMPIタスク0へ転送され、グローバルサイズの3次元配列内に保存されます。第2セクションでは、タスク0は補間用の周囲の4点を見出すのにグローバルデータを検索します。この時他のMPIタスクはアイドルします。第3のセクションではタスク0で補間が実行され、第4セクションではタスク0がファイルへ補間値を書き込みます。この関数はプロセス0と通信する膨大なデータ量を要求し、補間計算はルートプロセスで単独に実行されます。
4.2.2 新しい方法
Cray PAT解析から、ファイル書込み時間はサブルーチンの他の部分と比べて極めて小さいことが判ったため、シリアル実行マスターIOは互換性のため修正を行いませんでした。各MPIタスクはどの地上観測所を持つかを決定します。もし何らかの値を含めば、補間位置での場の変数を計算し、データ列をルートプロセスへ転送します。ここで、ハロ領域以外のパッチのエッジ近傍については特別な扱いが必要で、補間前に更新が必要です。地上観測所がパッチ境界上のgrid-box内に在る場合、幾つかのポイントが他のパッチに在ることが有り得ます。ハロ領域を含む一時配列を宣言し、場のデータをローカルな一時3次元配列へコピーします。全パッチはこれらシャドウデータを隣接パッチと通信して、それからこれを一時配列へコピーします。
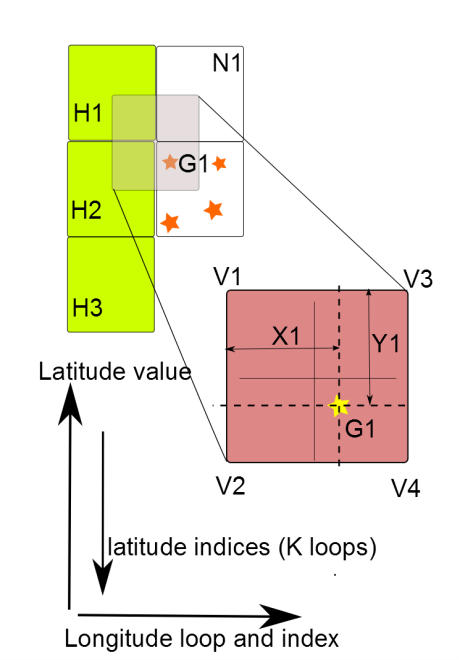
図3:バイリニア補間。ハロの更新が必要。
MPIタスク0への補間値転送は並列で実行されます。ローカル保存領域は小さいですが、全てのGBSが一つのパッチに在る場合でも十分なサイズです。ローカルに計算されたプロファイルの保存は、収集タスクの適切な領域に置き換えられます。出力は互換性のためシリアル実行のままとします。元の手法と比較して、最後の収集とファイル書込みのみがタスク0で行われ、他のタスクはアイドルすることになります。
4.2.3 メモリー容量と軽減
全場のデータのタスク0への転送を削除したため、ローカル領域が約330MB不要になります。ですが、ローカル配列に対するハロ領域と隣接PE上のハロへのシャドウデータ転送バッファを含む配列という、追加の一時領域が必要になります。このメモリー容量は70MBです。この関数では全部で260MBの削減になります。
4.2.4 通信の解析
もはやローカルな場のデータ全てをタスク0へ転送する必要はなく、通信量で280MBが削減されました。全MPIタスクでのハロ領域の更新には70MBが必要ですが、これはどのタスクがハロ領域が必要かを決定するよりも単純です。この量は分割によって変化し、タスク数がインターフェイス数を決めます。全体としては通信量は210MB減少します。
4.2.5 GBSTATのまとめ
このサブルーチンの改善により関連する実行も軽減されました。それはプロセスの並列化や、メモリー低減に起因します(以前の作業では、MPIタスクのスパースな分散はメモリー軽減により性能向上しました)。
| MPI tasks | 80 | 400 | ||
| Method | old | new | old | new |
| Normal step | 0.97 | 0.98 | 0.33 | 0.42 |
| Writing step | 8.80 | 0.99 | 39.30 | 0.51 |
表2は、出力ステップ時間の大きな変化を示し、地上観測所プロファイルの出力コストが大幅に削減されたことを示しています。
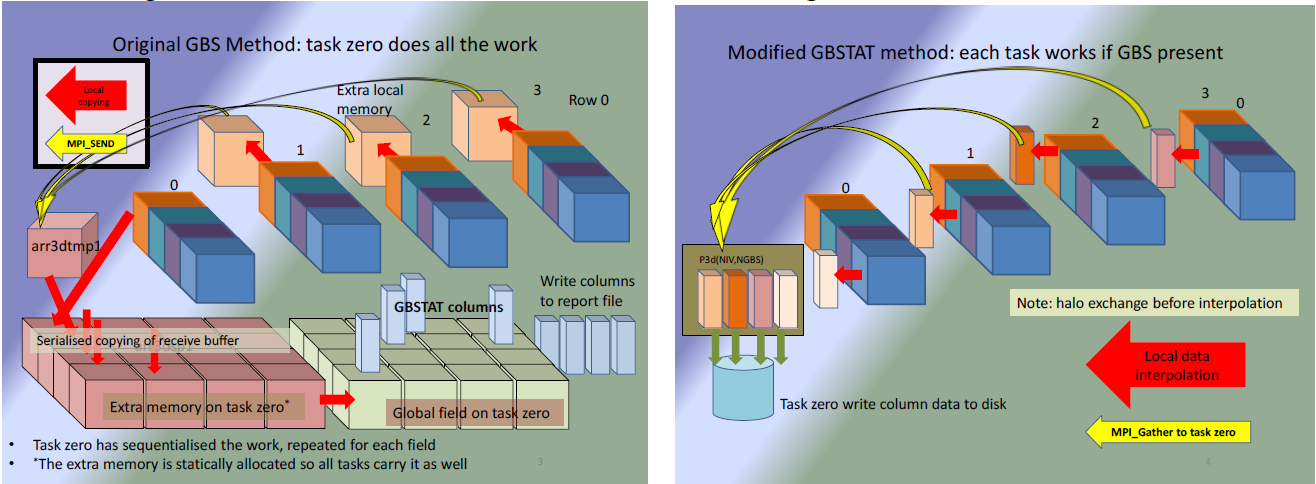
図4:左図は標準モデル、右図は修正モデル。
図4左図は、各MPIタスクの最初の値の列のみに対して1つの場のデータを集約する手順を示しています。16個のキューブから成る大きな形状は、4個の列から成り、分散された場のデータ用の保存領域を示します。4個の独立したキューブは各MPIタスク上の送信バッファを示します。図の下部に在る16個のブロックから成る2つのグループは追加の保存領域で、一つは入力バッファの組み立て用、もう一つは場の計算用です。SPMD形式と静的配列を用いるため、全てのMPIタスクに保存領域が確保され、共有ノードのメモリーサブシステムに多くな負荷を掛けます。
図4右図は修正された手法を示し、左図と同等の処理を少ない保存領域で実行することを描写しています。この処理は大きく単純化されており、保守と実装の容易さを備えます。
4.3 帯状平均計算
4.3.1 既存の実装の概要
SORZMは化学種に対して帯状平均を計算します。また、GBSTATのやり方を広く踏襲しています。場のデータはプロセス0へコピーされます。これはローカルデータをそのサイズの一時配列へコピーすることで得られます。サブドメインの参照位置がマスタータスクに送られてから、ローカルコピーはMPI_SENDを使ってマスターMPIタスク(タスク0)へ送られます。タスク0はこのバッファをグローバルデータ配列の対応する位置にコピーします。次にタスク0は緯度線に沿って値の総和を取ります。これは経度ループで繰り返され、次に化学種ループで繰り返されます。平均値は単純に総和を総数で割ることで計算されます(即ちsum(1:NLON)/NLON)。そしてマスタータスクはデータをファイルへ書き込みます。よってファイル構造は化学種毎の経度面から成ります。処理は図5の左図で模式されています。
4.3.2 SORZMの改良
改良された手法では、MPIタスク内の緯度線上の値は2次元配列へ総和されます。これはオリジナルと同じですが、各MPIタスクは同時に実行します。その後MPIリダクションを用いて、これら平面はMPIタスクの列に沿って総和されます。MPI_Reduceallを用いないので通信は最小で、最終的な値は、列の”root”(PE列のランク0)であるMPIタスクのみに保存されます。各列に対して別のコミュニケータを用い、関連するMPIタスクデータのみで総和を行うようにします。帯状平均が計算された後、MPI_GatherVでプロセス0へ格納されます。そして結果はファイルへ書出されますが、オリジナルバージョンと同じ順序である事が重要です。この性質を残す主な理由は、オリジナルの手法で生成されたファイルと同等にするためです。改良された方法は各”タスク列マスター”に該当するセクションを並列にファイル出力させます。これは出力時間を削減し、MPIタスク0への収集を不要にします。これはMPI-IO関数を必要とし、出力フォーマットは“stream”なのでオリジナルバージョンとの比較は困難です。この処理の概要を図5右図に示します。
平均値はシリアルバージョンと異なる可能性があります。シリアル実行は経度の降順に経度線の値を足し上げていきます。大きさ順に変化する変数の値を異なる順序で足しこむ場合、最終的な値は計算順序が異なるために同一にはなりません。小さな値に大きな値を加算することは、マシン精度限界を呈しますが、同じような大きさの値を多く足しこめば最終的に大きな値となり、別の大きな値に足しこむことが出来ます。ビニングと呼ばれる手法では、同じような大きさの数を加算して最終的に一つの”bin”として表現します。反対の符号を持つ数の加算でも同様の問題が生じます。大きな負の値と大きな正の値を加算すると、予期せずゼロにならない場合があります。
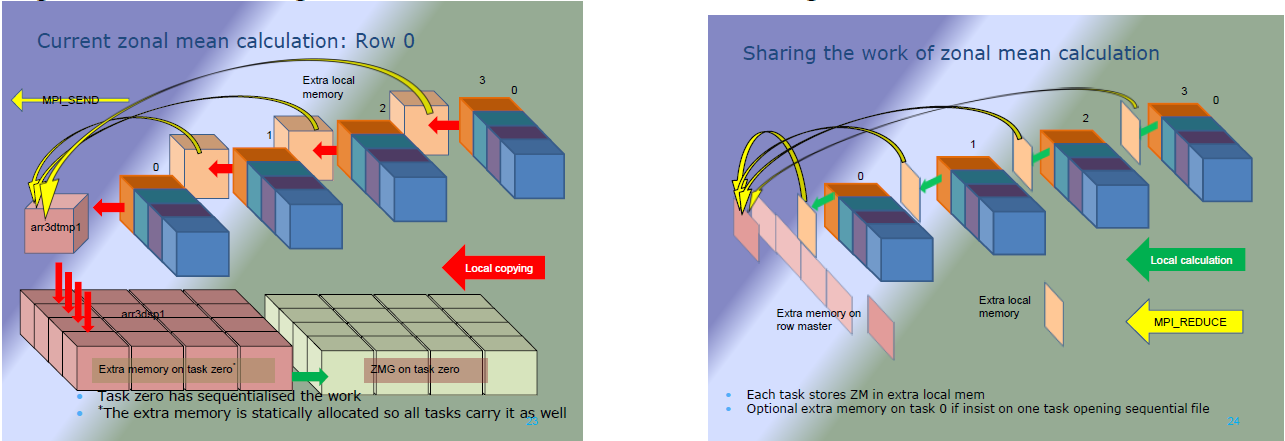
図5:帯状平均計算における、左図はオリジナルモデル、右図は修正モデル。
4.3.3 メモリー容量と軽減
この手法によるメモリー容量の推定削減量は330MBで、これは全球サイズの容量と幾つかの多次元配列コピーの削減によるものです。バッファと通信による総和計算用に多少の一時メモリーが必要で、約1MBが足されます。よって要求される容量は329MB削減されます。
4.3.4 通信の解析
元の手法では、場のデータ全てがルートMPIタスクに送られます。80MPIタスクを用いた場合、これは280MBのデータ転送が生じます。修正バージョンでは、最後の平面のより小さなデータを通信することになるため1MB以下です。この平面はMPIタスク数によってサイズが変化します。しかしながら、経度方向のタスク数が同じ(5)のこの解像度モデルでは、総和されるデータも同じです。よって全体の削減は279MBです。
4.3.5 SORZMのまとめ
表3は情報の出力の可否に対する繰り返し時間の比較を示しています。以前はこの関数は、MPIタスク数を増やすとオーバーヘッドが大きく(10倍)なっていました。新しい手法はMPIタスク数を増やしても時間ステップの10%以下です。
| MPI tasks | 80 | 400 | |||
| Method | old | new | old | new | |
| Normal | step | 0.53 | 0.53 | 0.33 | 0.33 |
| Writing | step | 4.65 | 0.55 | 41.55 | 0.35 |
帯状平均計算の改善により、データログ回数を増やすことが可能です。出力が少ない場合にこのデータをプロットすれば何らかのミスが生じるトレンドを察知できます。
図4と同様に図5はMPI列配置の違いを示しています。GBSTATと同様に大きくメモリーが減少します。
4.4 ギャザー/スキャッター性能の改善
4.4.1 専用データタイプの必要性
MPI関数にはインターフェイスに特定のデータ型が必要です。MPIで事前に定義されたデータ型の数は決まっています(システムのインクルードファイルmpif.hで約64個確認できます)。この基本データ型はユーザ定義のデータ型構築の基礎となり、データ構造はベクトル型の基本データ型よりも複雑です。
計算は、矩形の計算空間を2次元グリッドのサブ領域へ分割することで並列化されます。これはシミュレーションの前に明確に定義され、計算中には変化しません。既存のコードは、読み込んだら直ちにデータをスキャッターする“DISTF”を用います。この関数は大きなデータ移動を用います:最初に配列断片をプロセス毎のバッファへコピーし、各MPIタスクつまりMPI送信バッファに関するループを実行します。これは残念ながらシリアルに実行されており、MPIのシステムレイヤーを用いればより効率的になると考えられます。
こうしたやり方の代わりに3種の個別のデータ型を利用できます。これは計算ブロックへ纏められた連続データ列です;ある場合にはこのデータ型はハロデータ保存領域を持ち、第二のケースではハロデータを持ちません。これは、場合によってハロデータが必要だったり不要だったりする、TOMCATで用いる変数のデータ型に適切です。第3のデータ型はハロデータを持たない幾つかのデータ列から成ります。この列はサブ領域の平面成分です。これは、グローバルサイズの配列における内部ポイントのみをローカルな2次元配列へスキャッターするのに便利です。MPIにデータ型を登録すれば多くのバッファコピーはMPIレイヤーで行われます。その定義はFortranモジュールで行うのでデータ型はグローバルになります。
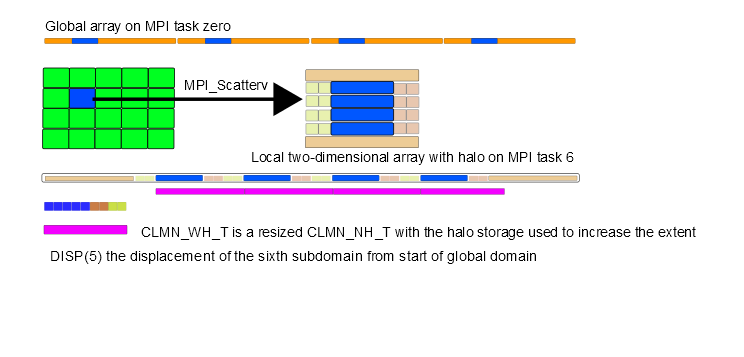
図6:MPI_ScatterVで用いる新しいデータ型の概念図
図6においてタスク0上のグローバル配列のマークされたセクションは、MPIタスク6で必要なデータの矩形領域へスキャッターされます。分散タスク上の箱はハロデータ無のローカル2次元配列です。
MPI_ScatterVはルートタスク上のデータに適用され、コミュニケ―タ内の全てのタスクに分配されます。
スキャッターにより、タスク0上のグローバル配列のブロック断片PFGを送信し、ハロデータ保存領域を持つローカル2次元配列PFLを受信します。既存コードでは、通信配列にハロデータが必要かどうかのフラグが用意されています。こうした間接的な指示は削除されてデータ型で置き換えられ、DISTFのコピー機能は図7に示されるMPIレイヤーで扱われます。
図7:PPRDでの呼び出し方 call MPI_Scatterv (PFG,NSND,DISPLS,blk_nh_t, & PFL(1,1),NRCV,clmn_wh_t, & ROOT,UCOMM,MPERR)
平面内では多次元配列が参照され、平面の中では2次元構造が1次元ベクトルに展開されます。これらはMPIの基本データ型で上手く処理されます。しかしながらベクトルデータを得るには、多くのユーザ定義の介入とデータの再配置が必要です。
4.4.2 ファイルリーダPPREADをPPRDで置き換える
TOMCATの既存バージョンは、疑似並列リーダ“PPREAD”を用いますが、実際にはDISTFの呼び出しによるシリアル実行です。PPREADの既存の実装は、2次元平面の要素のベクトルへの変換であり、インターフェイスにおいて変換するものです(呼び出し前に配列をベクトルへ形式的に変形するものではありません)。この時ファイルから全平面を読み込み、DISTFへ渡してその中で1次元ベクトルは2次元配列へ変換されます。これはMPIタスク毎のエントリーとしてバッファに渡され、パックされた配列は各MPIタスクに送信されます。そして各MPIタスクはバッファを2次元配列へコピーします。
DISTF呼び出しでは受信配列サイズは可変で、図8に示すようにデータの内容を示す複数の引数を持ちます。ある場合にはそのサイズはハロデータを保存する余地は無く、他のケースではハロデータ保存を許します。これは、ハロ情報が保存される欠損領域を持つ行列形式でベクトルの分配を行うアンパック処理が可能です。
図8: PPREADのインターフェイスとその中でのDISTF呼び出し SUBROUTINE PPREAD( KUNIT, PFL, LPTYPE, KPROC ) CALL DISTF( PFG, PFL, NLONMX, 1, 1, KPROC) CALL DISTF( PFG, PFL, (NIMX-NIMN)+1, NIMN, NKMN, KPROC)
DISTFでは、PFGは行き先のMPIタスクに従ってデータを保存するバッファへコピーされます。送受信シーケンス(個の実装ではシーケンスです)が完了したら、受信ベクトルは上述のようにPFLベクトルにアンパックされます。PPREAD呼び出し位置に戻ると、このベクトルはインターフェイスにより、MPIタスク上ですぐに使えるローカル2次元配列へ再配列されます。このやり方は“ユーザプログラミング”クラスであり、MPI実装に最も適したやり方ではありません。グローバル2次元配列からローカル2次元配列へのマッピングは、前のセクションでのユーザ定義データ型を用いて行うことが可能です。
図9: PPRDのインターフェイス call PPRD (IFRD,NIMN,NIMX,NKMN,NKMX,clmn_wh_t,SMOLD(nimn,nkmn,l))
PPRDへの置き換えはDISTFを用いず、ファイルから読み込まれる配列に適したデータ型を用います。図9に示すように、配列の内容の引数が必要です。
4.4.3 ファイルライタPPWRITをPPWRで置き換える
PPRDと同じように、ユーザによるギャザー機能”COLLF”を関数PPWRで置き換え、書式なしファイルへ書き込む前にMPIタスク0へ分散されたデータを収集するようにします。
既存のCOLLFのアルゴリズムは、開始時にバリア同期を持つ旧式の手法となっていました。ローカルな場の情報(ハロを含まない)は、プロセッサーにより異なるグローバルな全平面サイズのバッファへロードされます。引き続く条件付き構造で、連続してMPIタスク0は各サブ平面情報を受信します。他の全てのMPIタスクはその担当する平面(この巨大バッファの1スライス)情報をマスタータスクへ送信します。こうした巨大バッファを用いる場合、それが全てのタスク上に存在して、タスク0上で各タスクにより安全に格納ができるという特徴があります。これは、受信バッファをグローバルな場の配列へアンパックするデコードセクションの後に行われます。
4.4.4 並列ファイルアクセスモデルの開発
本作業で作成されたプロトタイプは、シリアル実行のマスタータスクIOを”row-master”手法へ強化します。行われたのは、既存の参照データファイル内のデータ構造の変更です。これは既存の手法が全データ平面を入出力しているため、”end of records”が並列入力に用いることが可能な緯度で腹べられていなかった為です。
外場のレコードが緯度別に並んでいれば、”row-master”上の緯度範囲に共通の緯度数にアクセスを制限することが可能になります。
4.5 Task2.1(並列I/O)のまとめ
このセクションでは、4つの関数(GBSTAT, SORZM, PPREAD, PPWRIT)が達成された例として選ばれました。最初の2つは大幅に書き換え、その機能を用いた場合大きな改善が示されました。この新しい手法は衛星データの取り扱いにおいて既に利用されています。この場合においては、異なる経度と緯度について1日当たり15サンプルが必要となり、低コストのアルゴリズムが重要となります。
次の2つの関数は、大きな性能改善は示しませんでしたが、それほど負荷の高いものではありません。その開発も、データ構造が緯度並びになるまでは利用価値の高いものではありません。ユーザ定義データ型はTOMCAT開発者により適用可能となり、PPRDとPPWTの置き換えもコードの他の部分でも可能です。それは例えば、DEEPTDINI, DEEPTDINT, OZNINI, OZNINT, STINI, STINT, TSINI, TSINT等です。これら4種のアルゴリズムにおいては、ファイルのシリアルアクセスを基本として残してあり、実計算ですぐに利用可能です。
5. netCFD機能の調査
本プロジェクトで用いたコードはNetCFDの開発バージョンを含みます。
FINITERではNetCFDを用いるか、書式無Fortranバイナリーファイルを用いるかの決定が行われます。続いてINICDF, INI_DIAGCDF, WRITE_CDFの呼び出しをします。この2つの初期化ルーチンは、最初に1回のみ実行されます。ライターはユーザー指定により繰り返しの最後に呼ばれます。
INCFD:これはファイルを生成し、変数の全てのセットを定義します。幾つかのメタデータの処理します(シミュレーション中は不変で、シミュレーション間で変化するもの)。
INI_DIAGCFD:これは特定の変数を出力します。これはタスク0内の多くの処理から成る複雑なサブルーチンです。また、既存のGBSTAT, SORZM, PPWRITと同じシリアルなライター手法です。その処理と出力前に、1つのMPIタスクへ全データを集めることが要求されます。PUT_CDF_VAR3D, PUT_CDF_VAR2D, PUT_CDF_VAR2D_INT, MONTHLY_MEANを含む他の関数はこのデータ収集に用いられます。
明らかに、並列NetCFDによる直接的なデータのギャザー処理、あるいは場合によってギャザーしないという処理を変更する2種の手法による改善の可能性があります。新しいデータ型は前者に適用できますが、後者には全てのフィルターと収集処理を除去するという余計な仕事が必要になります。その選択はまだ決まっていません。
6. 結論
本プロジェクトの作業において、コアの機能は既に極めて効率的であることが示されました。コードのコア部はさらに性能を上げるにはハードウェア特定のチューニングが必要でしょう。ファイルアクセスのボトルネックは、入出力に付随する処理にあることが分かりました。コードの2つの関数に対して、ファイルアクセス性能が大幅に改善されました。この変更はステップあたりの時間情報にはほぼ検出されないものです。
ユーザ定義データ型が実装され、出力の為のギャザーや入力の為のデータ分散が必要なコードにおいて何処でも利用可能です。これらは将来の開発の為に”re-inventing the wheel”とならぬように使用されるべきでしょう。
このレポートは2013年5月のCrayユーザグループミーティングで発表されました。
文献
| [1] | M.Richardson, “Improving TOMCAT/GLOMAP Mode MPI for Use on HECToR, a Cray XT4h system”, HECToR DCSE programme, www.hector.ac.uk , April 2009. |
| [2] | M.Richardson, G.W.Mann, M.P.Chipperfield, K.Carslaw, “Implementation of OpenMP within MPI-TOMCAT-GLOMAP mode”, Cray User Group Meeting, Edinburgh, May 2010. (also full report available on HECToR web-site). |
| [3] | Progress Report 1: M.Richardson, M.P.Chipperfield, “Performance Characteristics Of TOMCAT For High Resolution Simulations”, HECToR DCSE programme, www.hector.ac.uk , October 2012. |
| [4] | M. Richardson, Progress Report 2: Modification of GBSTAT, March 2013. |
| [5] | M. Richardson, Progress Report 3: Modification of SORZM, May 2013. |