
Lucian Anton, Ning Li and Phil Ridley
Numerical Algorithms Group
August 6, 2012
概要
ターボ機械設計において、レイノルズ平均ナビエ・ストークス(RANS)モデルは、対流後流や大規模剥離、複雑な渦構造などの非定常性が支配する乱流の取り扱いにおいて、通常は困難に直面します。これらは、基本的な噴流でさえ、RANSや非定常RANSへ理論的な疑問を提示します。一方、Large-eddyシミュレーション(LES)は、乱流構造をRANSのように近似することなく、数値的に解像するため、極めて信頼できる手法です。しかしながら、LESは、複雑な乱流構造を捕捉するために、億のオーダーのグリッド点を必要とします。乱流の揺らぎの4次の時空間的な補正の標準的なシミュレーションでは、12時間以上の長時間が必要です。本プロジェクトの目的は、構造CFDコード"BOFFS"の改善であり、メニーコアHPCマシンの有効活用です。その標的は、ブロック間転送のMPI通信であり、そのメモリーの有効利用と、ブロック内計算でのOpenMP性能の改善です。本作業のゴールは、現実的なターンアラウンド時間内で、超高解像の高次LESを、BOFFSによりHECToR上の数千コアと1億以上のグリッド点を用いて実行することです。
目次
1 イントロダクション
2 コード内容
3 プロジェクト目標
3.1 WP1:MPIバッファの改善
3.2 WP2:メモリー効率化
3.3 WP3:検証
4 プロジェクト成果
4.1 MPI通信の改善
4.2 座標の非同期通信
4.3 メモリー効率化
4.4 OpenMP並列の改善
4.5 検証
4.6 コンパイラー性能比較
5 シミュレーション例
5.1 高圧タービン
5.2 低圧タービン
5.3 リムシール
5.4 ラビリンスシール
6 結論
7 謝辞
1 イントロダクション
非定常乱流に対して、レイノルズ平均ナビエ・ストークス(RANS)モデルは、対流後流や大規模剥離、複雑な渦構造などの非定常性が支配する乱流の取り扱いにおいて、通常は困難に直面します。その例としては、ガスタービン動翼シュラウド流、ハブ・キャビティ/エンドウォール領域、タービン動翼内部冷却通路流、カットバック後縁部領域などがあります。エアーシステム内部キャビティ流も高度な乱流状態にあります。これらは、RANSや非定常RANSへ理論的な疑問を提示します。RANSモデルは、基本的な噴流でさえ貧弱な性能であることが文献[1,2]で示されています。
一方、Large-eddyシミュレーション(LES)は極めて信頼できる手法です。これは、乱流構造をRANSのように平均場近似することなく、完全に数値的に解像するためです。しかしながら、LESを用いる主要な困難さがメッシュサイズにあり、複雑な乱流構造を捕捉するためには、通常少なくとも1億オーダのグリッド点が必要となります。これは、乱流渦が非等方的になり、ストリーク構造が存在する壁付近で特に重要です。この構造を解像するには、流れ方向、壁垂直方向およびスパン方向に極めて細かいグリッドが必要です。ケンブリッジ大学のWhittle研究所において実施された音響領域のLESにおいては、乱流揺らぎの4次の時空間補正が必要でした。スペクトル情報(音響および乱流の両方)の構成には、低周波成分を正確に解くために長時間が要求され、通常は12時間以上必要です。
こうしたスケールにおいて、非構造CFDソルバーは更なるオーバーヘッドが露わになります。そこで、インハウスの構造CFDソルバーBlock overset Fast Flow Solver(BOFFS)が、キメラ(オーバーセット)メッシュを用いた大規模分散並列計算ソルバーとして開発されました。BOFFSは、Fortran90で記述され、並列化にはMPI/OpenMPハイブリッドを用いています。HECToR上でのスケーラビリティーは、1千万グリッド以下でリーズナブルな性能を示しますが、より大きなグリッド数では性能劣化します。1億グリッド以上を用いた計算において、現実的なターンアラウンド時間で実行するためにはスケーラビリティ改善が必要です。
本プロジェクトは、HECToRや他のメニーコアマシンでのBOFFSの性能改善を実施します。そのために、ブロック間データ転送に用いるMPIを最適化し、メモリー利用効率を改善し、ブロック内計算で用いられるOpenMPを改善します。
2 コード内容
BOFFSは、約22,000行のFortran90コードです。これは、3つの主要セクションに分けられ、各々はシミュレーションの異なるステージとして、グリッド前処理、時間積分、ポスト処理を担当します。分散データ分割では、オーバーセットメッシュの各グリッドブロックが一つのMPIプロセスに割当てられ、そのプロセス内ではOpenMPスレッドのチームが割り当てられています。各MPIプロセスは、メッシュ座標のブロックと境界条件を読み込み、もしリスタートする場合は対応する流れ場ファイルも読み込まれます。この時、前処理は、更なるデータおよび入力デック読み込みと、境界条件設定を行い、メトリックを計算します。新たなメッシュブロックには、このステージでインターフェイス補間データを作成します。補間ファイルを作成したら出力し、引き続くリスタート計算時に用いられます。このセクションのコードは、OpenMPで並列化されており、MPIは用いていません。
グリッド前処理が完了したら、メインの時間積分ループが開始されます。ここで、方程式の右辺が最初に構成されます。このシステムは、メッシュに依存して、ガウス-ザイデル法か、三重対角アルゴリズム(TDMA)の陰的緩和法のどちらかを用いて計算されます。次回の繰返し前に、境界値と配列が更新されます。この単純な解法は、効率に対して相対的に保存容量が少ないため、多くのCFDソルバーで一般的なものです。
時間発展解が収束したら、ポスト処理が開始されます。これは直截的に、場の量をリスタート用のフォーマット無バイナリーファイルへ出力します。これはPlot3Dによる可視化の入力にもなります。これら出力ファイルは個別にMPIプロセスが出力します。
コードにおいて最も時間の掛かる部分は、時間ステップ毎に必要となるブロック境界間の転送です。これは圧力、速度、温度と言った異なる流体変数を含みます。乱流モデルを用いた場合は、更に追加の変数の交換(転送)が要求されます。この転送のためのルーチンは、PackVar_SendおよびRecvvar_unpackです。
本プロジェクトを開始する前に、BOFFSコードのリファクタリングを行い、マイナーな性能改善を行いました。このリファクタリングには、不要な(コストのかかる)初期化の削除や、未定義変数の宣言、HECToR上の種々のコンパイラーによるコードテストが含まれます。コードは管理上の理由でファイル分割され、幾つかの関数はインライン展開されました。COMMONブロックはMODULEへ変更され、makefileが作成されました。
3 プロジェクト目標
典型的な32ブロックケースのシミュレーションを、HECToRフェーズ2b(XE6)の8つの完全飽和24コアノード(ブロック当たり6つのOpenMPスレッドを持つ4つのMPIプロセス)と、HECToRフェーズ3(XE6)の8つの完全飽和32コアノード(ブロック当たり8つのOpenMPスレッドを持つ4つのMPIプロセス)を用いて実施しました。ターンアラウンド時間は約1か月でした。
BOFFSのフェーズ2bとフェーズ3の性能を、4種のテストケースについて、表1と2に示します。各テストケースは、グリッド点数は固定で、4BLK_3Mケースはブロック当たり0,75百万グリッド、4BLK_12Mケースはブロック当たり3百万グリッド、32BLK_3Mケースはブロック当たり93,750グリッド、32BLK_12Mケースはブロック当たり375,000グリッドです。総実行時間を、データファイル入力、ポスト処理、メイン時間ステップ繰り返し部で掛かる時間が解るように分けて記載しました。この2つの表から、スレッド化されたこのコードは、一般的には極めて良い速度向上性能を持つことが解ります。しかしながら、4つのMPIプロセスを用いた4BLKケースの性能は、3百万、12百万共に良好ですが、32BLKケースは良好とは言えません。一回の繰返し実行時間は、6や8スレッドに対して2倍程度しか高速化していません。
| Cases with OpenMP threads |
Wall clock time in seconds | |||||
| Read Input | Post Processing | 1 time step | ||||
| 6 threads | 8 threads | 6 threads | 8 threads | 6 threads | 8 threads | |
| 4BLK_3M | 1.2 | 1.0 | 1.2 | 0.9 | 30.5 | 27.1 |
| 4BLK_12M | 5.8 | 5.5 | 6.1 | 5.9 | 149.5 | 122.2 |
| 32BLK_3M | 1.3 | 1.1 | 1.9 | 1.8 | 7.5 | 5.7 |
| 32BLK_12M | 5.8 | 5.7 | 7.8 | 6.5 | 36.1 | 27.2 |
| Cases with no OpenMP threads |
Wall clock time in seconds | |||||
| Read Input | Post Processing | 1 time step | ||||
| Phase 2b | Phase 3 | Phase 2b | Phase 3 | Phase 2b | Phase 3 | |
| 4BLK_3M | 1.4 | 1.1 | 1.4 | 1.1 | 106.7 | 82.4 |
| 4BLK_12M | 6.1 | 5.6 | 7.5 | 6.2 | 865.7 | 396.3 |
| 32BLK_3M | 1.4 | 1.3 | 1.9 | 1.7 | 34.3 | |
| 32BLK_12M | 6.4 | 5.8 | 8.1 | 6.6 | 84.6 | 62.5 |
これら実行時間は、GNUコンパイラーを用いています(フェーズ2bではバージョン4.5.1、フェーズ3では4.6.3)。
メイン時間ステップ実行時間は大きなサイスの問題に対してスケールしていません。自動プロファイリングツールの結果を図1に示します。同期してMPIバッファーをブロック間に渡ってパッキングするルーチン(PackVar_Send)が、問題です。図2の分析から、大きな負荷分散が生じており、これがMPIの同期時間を大きくしています。
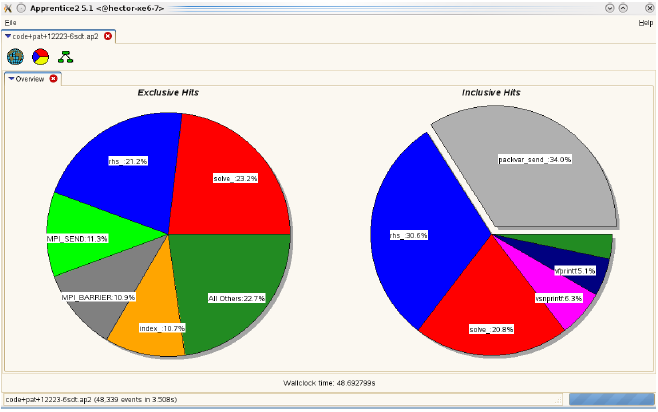
図1:3百万グリッド、32ブロックケースのプロファイリング結果
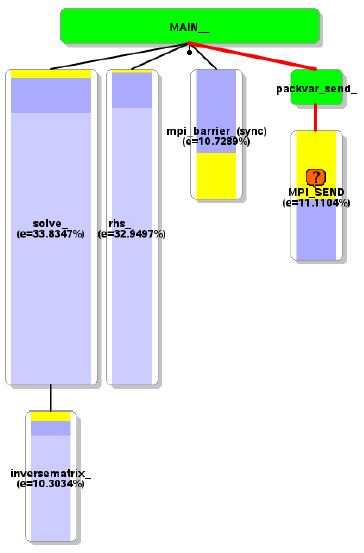
図2:PackVar_sendの負荷分散
スケーラビリティーの問題に加えて、調査の結果、GNUコンパイラーよりPGIコンパイラー(10.9.0)の方が、ループアンローリングとベクトル化において最適化が改善されており、性能が良いことが解りました。しかしながら、これは3Mグリッドの小さなケースの結果で、大きな問題ケースでは、静的に確保された配列がメモリーに収まりませんでした。さらに、OpenMPスケジューリングがブロック内計算において最適化されていませんでした。そこで、以下の作業が本プロジェクトで提案されました。
3.1 WP1:MPIバッファーの改善
WP1.1:MPIパッキング/アンパッキングルーチン:PackVar_sendおよびRecvvar_unpack内において、倍精度バッファーVar_Recv_Mpiは、時間ステップ毎に必要なデータ(圧力、速度、乱流式の各種量の境界値)を格納します。このバッファーのパッキング/アンパッキングは、以下のような3つの多重ループ内の5つのネストされたIF-THENブロックを用います。
do k = Nk1, Nk2 do j = Nj1, Nj2 zn_num = zonenumber(nblock,1,j,k) do z = 1, zn_num zn_type = zonetype(nblock,z,1,j,k) if (zn_type .ze. 0) then bnd1 = zoneboundm(nblock,z,1,j,k) bnd2 = zoneboundp(nblock,z,1,j,k) if (bnd1.eq.b_int) then if ((val .Eq. 0).or.(val .Eq. b_int)) then block = nbb(nblock,z,1,j,k) if (block.eq.from_block) then count = count + 1 PbndM(nblock,z,1,j,k) = Var_Recv_Mpi(count)
ここで、IF-THENブロックを削除するために、事前にデータ構造を並べ替えて修正します。ループカウントをインクリメントする代わりに、事前に決めたオフセットを用います。こうして以下のような形式で実装することが出来ました:
nblock = rank do np = 1, npbound i = mpi_index(np) j = mpi_index (np+1) k = mpi_index (np+2) z = mpi_index (np+3) count = countindex(np+4) PbndM(nblock,z,1,j,k) = Var_Recv_Mpi(count) enddo
ここで、mpi_indexは、前処理ステージの一部として計算され、補間ファイルに保存して置きます。こうすれば、多重ループと多重ネスト条件文は、一つのループとして記述でき、性能は改善されます。
WP1.2:ブロック間転送の性能改善において残された作業は、現在のシリアルMPI通信スキームを非同期手法で置き換える事で、同期時間の削減を図ることです。これは、現在のシリアル転送を用いる1対1通信パターンを置き換え、計算と通信のオーバーラップにより可能です。WP1.1の結果と合わせて、その性能は20%の高速化と、少なくとも100ブロック(1000コア強)までスケールすることが期待できます。
3.2 WP2:メモリー効率化
インターフェイス変数、基本変数(定常、非定常)、右辺項、境界値、出力メトリックスを含むすべての変数に対して、大きな静的配列が使用されています。12百万グリッドの場合、PGIコンパイラー(mcmodel=edium)が扱いきれない大きさになりますが、ダイナミックリンクを用いて動作は可能です。GNUコンパイラーでは静的配列のままでも可能です。ですが、3百万グリッドケースでは、GNUよりもPGIの方が10%高速であったため、ダイナミックリンクを用いずに全ての問題サイズでPGIコンパイラーを用いる方が得です。これは静的配列をallocatable配列へ変更し、不要な配列を削除して可能になりました。
3.3 WP3:検証
12百万グリッドケースで、4,32ブロックケースを用いて検証を完了しました。
4 プロジェクト結果
4.1 MPI通信の改善
MPIバッファーの改善のために、BOFFSの解析を更に進めました。PackVar_SendおよびRecvvar_unpackルーチンの改修の前に、これらルーチンを呼出す方法を修正しました。元のコードは、ブロック間データ交換にMPI通信ルーチンをシリアルに呼び出していました。ここで、各MPIプロセスは、先行するプロセスのデータ送信を待つブロッキング受信のMPIタスク総数のループを実行します。以下の例で、簡単のために5タスクを用いてこの状況を示します:
5つのMPIタスクは、各タスクは以下のように左隣のタスクへバッファデータを渡します: 0<-1<-2<-3<-4 call mpi_send(sbuff,...,myid-1...,ierr) ..... call mpi_recv(rbuff,...,myid+1,..,ierr)
ここで、各ランクは最初に、ブロッキング送信を左隣に向けて行いますが、ランク0のみは受信のみを行います(非周期境界条件とします)。次に、交換(0<-1)が完了したら、ランク1は受信待ち状態に移り、交換(1<-2)へ進み、以降こうした動作を続けていきます。この通信動作は、シリアル実行形式であり、並列動作可能な演算が2つしかありません。
コード性能の観点から見ると、以下の各関数別のプロファイルが示すように12百万グリッド/32ブロックケースでは、総実行時間の9.3%をMPIが占めており、その時間の中でブロッキングMPI_SENDルーチンがほとんどを占めています。
Time% | Time | Imb. | Imb. | Calls |Group 100.0% | 230.205369 | -- | -- | 14281280.8 |Total |------------------------------------------------------------------------------------------- | 82.3% | 189.357545 | -- | -- | 14280789.6 |USER ||------------------------------------------------------------------------------------------ || 38.6% | 88.894237 | 2.648718 | 3.0% | 40.0 |solve_.LOOP@li.212 || 12.8% | 29.496465 | 2.303737 | 7.5% | 1.0 |main_ || 9.8% | 22.588643 | 0.093898 | 0.4% | 42.0 |rhs_.LOOP@li.223 || 9.3% | 21.451923 | 0.090482 | 0.4% | 42.0 |rhs_.LOOP@li.1812 || 7.5% | 17.350544 | 0.079816 | 0.5% | 42.0 |rhs_.LOOP@li.1024 || 2.4% | 5.448789 | 2.663316 | 33.9% | 14280000.0 |inversematrix_ || 0.9% | 2.102017 | 0.009066 | 0.4% | 42.0 |rhs_ || 0.5% | 1.058167 | 0.028250 | 2.7% | 61.0 |boundaryupdate_.LOOP@li.144 || 0.3% | 0.692370 | 0.003452 | 0.5% | 40.0 |solve_ || 0.1% | 0.126090 | 1.943039 | 96.9% | 3.8 |boundaryupdate_.LOOP@li.479 || 0.1% | 0.117772 | 0.003597 | 3.1% | 61.0 |boundaryupdate_.LOOP@li.1182 ||================================================================= | 9.3% | 21.368852 | -- | -- | 112.4 |MPI ||------------------------------------------------------------------------------------------ || 7.7% | 17.813062 | 18.727963 | 52.9% | 40.7 |MPI_SEND || 1.1% | 2.603411 | 1.503864 | 37.8% | 1.0 |mpi_finalize || 0.4% | 0.951937 | 0.112093 | 10.9% | 40.7 |mpi_recv || 0.0% | 0.000376 | 0.000128 | 26.2% | 21.0 |MPI_BARRIER || 0.0% | 0.000051 | 0.000007 | 12.6% | 6.0 |mpi_wtime || 0.0% | 0.000006 | 0.000001 | 9.2% | 1.0 |MPI_INIT || 0.0% | 0.000005 | 0.000001 | 23.2% | 1.0 |mpi_comm_rank || 0.0% | 0.000004 | 0.000001 | 24.6% | 1.0 |MPI_COMM_SIZE ||================================================================= | 8.5% | 19.474334 | 19.223893 | 98.7% | 21.0 |MPI_SYNC ||------------------------------------------------------------------------------------------ | 8.5% | 19.474334 | 19.223893 | 98.7% | 21.0 | mpi_barrier_(sync) ||=================================================================
ここで単純なトリック(最初に奇数ランクを待たせ、偶数ランクが送信する)を用いると、パッキングルーチンがプロファイルランキング外になります。この方法では、以下のように2種の通信ペアが並列に動作します:
Stage 1: (0<-1), (2<-3), 4 Stage 2: 0, (1<-2), (3<-4) code pattern if ( mod(myid,2)==0)then call mpi_recv(rbuff,...,myid+1,..,ierr) ... call mpi_send(sbuff,...,myid-1...,ierr) else call mpi_send(sbuff,...,myid-1...,ierr) ... call mpi_recv(rbuff,...,myid+1,..,ierr) endif
前回と同じ条件での以下のプロファイルから、総実行時間の内MPIが占める割合は3.1%となり、その時間の中でブロッキングMPI_SENDルーチンの占める割合は1%以下になりました。このテストケースの場合、MPI_SENDの実行時間は約18秒から1.8秒へ減少し、全実行時間は230秒から203秒へ減少しました。
Time% | Time | Imb. | Imb. | Calls |Group 100.0% | 203.165181 | -- | -- | 14281280.8 |Total |------------------------------------------------------------------------------------------ | 93.2% | 189.367336 | -- | -- | 14280789.6 |USER ||----------------------------------------------------------------------------------------- || 43.8% | 89.040701 | 3.005270 | 3.4% | 40.0 |solve_.LOOP@li.212 || 14.7% | 29.898026 | 4.079582 | 12.4% | 1.0 |main_ || 11.2% | 22.674467 | 0.095291 | 0.4% | 42.0 |rhs_.LOOP@li.223 || 10.4% | 21.225894 | 0.077735 | 0.4% | 42.0 |rhs_.LOOP@li.1812 || 8.6% | 17.393574 | 0.079199 | 0.5% | 42.0 |rhs_.LOOP@li.1024 || 2.5% | 5.018218 | 2.621076 | 35.4% | 14280000.0 | inversematrix_ || 1.0% | 2.098218 | 0.008748 | 0.4% | 42.0 |rhs_ || 0.5% | 1.061462 | 0.028729 | 2.7% | 61.0 |boundaryupdate_.LOOP@li.144 || 0.3% | 0.679213 | 0.002862 | 0.4% | 40.0 |solve_ || 0.1% | 0.127722 | 1.979859 | 97.0% | 3.8 |boundaryupdate_.LOOP@li.479 || 0.1% | 0.119386 | 0.003574 | 3.0% | 61.0 |boundaryupdate_.LOOP@li.1182 ||================================================================= | 3.7% | 7.496753 | 6.046087 | 80.6% | 21.0 |MPI_SYNC ||----------------------------------------------------------------------------------------- | 3.7% | 7.496753 | 6.046087 | 80.6% | 21.0 | mpi_barrier_(sync) ||================================================================= | 3.1% | 6.296505 | -- | -- | 112.4 |MPI ||----------------------------------------------------------------------------------------- || 1.4% | 2.920704 | 1.907597 | 40.8% | 1.0 |mpi_finalize || 0.9% | 1.827206 | 2.685173 | 61.4% | 40.7 |MPI_SEND || 0.8% | 1.548190 | 0.217016 | 12.7% | 40.7 |mpi_recv || 0.0% | 0.000340 | 0.000057 | 14.8% | 21.0 |MPI_BARRIER || 0.0% | 0.000051 | 0.000005 | 9.2% | 6.0 |mpi_wtime || 0.0% | 0.000006 | 0.000002 | 29.7% | 1.0 |MPI_INIT || 0.0% | 0.000005 | 0.000008 | 65.4% | 1.0 |mpi_comm_rank || 0.0% | 0.000005 | 0.000004 | 44.5% | 1.0 |MPI_COMM_SIZE ||=================================================================
こうして、PackVar_SendおよびRecvvar_unpackはプロファイルに登場しなくなり、WP1のループ最適化は不要となりました。これらルーチンの実行時間は、全実行時間に対して極めて小さな部分を占めるのみになりました。
4.2 複雑な座標の非同期通信
MPI_SEND、MPI_RECVの偶奇グルーピング通信改善の後に、現状の通信手法は、BOFFSが扱うグリッドに関して、個々のブロックが1あるいは2個の隣接ブロックにのみ関係づけられているという制約がある事が指摘されました。これは、例えばコンプレッサーのブレードや噴流シミュレーションのような典型的なメッシュにおいては中央にコアブロックが存在し、その外部全てのブロックとインターフェイスを持たねばならない場合において、特に制約になります。
図3:噴流のメッシュ例
この状況は、MPI_ISEND、MPI_IRECV、MPI_WAITを用いて、非同期通信を実装することにより改善できます。これは、各ブロック(MPIタスク)の隣接ブロック数を保存した後に、PackVar_SendおよびMPI_ISENDを呼ぶ前に、MPI_IRECVを前後処理することで可能です。ここで、バッファがロードされ、各MPIタスクの準備が出来、その隣接ブロックからのデータ送信を待っている状態であるとします。各タスクは待ち合わせが必要ですが、一様な隣接ブロック分布を持つ場合は、この時間は極めて小さなものです。これにより、全体として通信性能が改善され、より複雑なブロック構造に対応させることが可能になります。この通信手法はまた、MPI_SEND/MPI_RECV偶奇グルーピング通信に1%の改善ももたらします。
4.3 メモリー効率化
元のBOFFSでは、インターフェイス変数、基本変数(定常、非定常)、右辺項、境界値、出力メトリックスを含むすべての変数に対して、大きな静的配列が使用されています。これらは、MODULE配列を定義するファイルarray.modにすべて含まれています。このモジュールに含まれる約100の静的配列を、順次allocatableへ変更しました。Allocatable配列は、コードへ柔軟性をもたらし、配列サイズは入力データから読み込まれるため、別のグリッドの場合に配列サイズを変更するための再コンパイルが不要になりました。
こうして、12百万グリッドに対して、PGIコンパイラーでコンパイル可能になり、GNUコンパイラーに比べ少なくとも10%の高速化が可能になりました。
4.4 OpenMP並列の改善
最初のプロジェクト目標に加えて、solve.f90におけるOpenMP部分のスケーラビリティーについて検討しました。このルーチンはTDMAソルバーであり、以前のCray PATプロファイルから、全実行時間の特にメインループにおいて、43.8%を占めることが解っています。当初のOpenMP実装では、ローカル領域が一方向に狭くなっているため(平均40:1)、6スレッド以上で性能劣化しています。
OpenMPのスケーラビリティ改善のために、solve.f90のメインループにred-black分割法を実装したところ、32スレッドまでスケールしました。さらに、利用可能なOpenMPスレッド数は、OMP_NUM_THREADS環境変数から直接その数を取得するomp_get_max_threads関数で確定されるようにしました。
HECToRでのスケーラビリティーテストにおいて、PGIコンパイラーが1スレッド以上を用いると問題がある事が指摘されていましたが、これは、以下のような整数配列mapをvolatile宣言していたことが原因であるとわかりました。
INTEGER, volatile :: map(0:maxsizeline,0:maxsizeline)
指示行!$OMP FLUSH(map)が既にコードには存在しましたが、volatile変数はFortran2003言語標準であり、当時、GCCとCCEはサポートしていましたが、PGIの当時のバージョンはサポートしていませんでした。
さらにソースコードを、コンパイル時間短縮のためファイル当り1モジュールへ分割し、配列外参照を幾つか修正しました。新しいBOFFSソースコードのmakefile依存性を生成するために、nAGコンパイラーを用いました。
4.5 検証
BOFFSの更新バージョンの検証をフェーズ3で実行しました。これにより結果のチェックと実行時間記録を行いました。全ての実行には、元のコードと同様にGCC 4.6.3を用いました。また、HECToRフェーズ3のノード32コア当たり1,2,4MPIタスクを用いて実行しました。元のコードと新しいコードの比較を表3に示します。見ての通り新しいコードのスケーラビリティーは、32BLK_12Mと32BLK_3Mのみ改善していますが、これは、これらが4BLKケースより多くのMPI通信を含むためです。シングルスレッド実行の場合は、新しいコードは4BLKの方が遅いですが、これは、TDMAソルバーの新しいOpenMP実装のオーバーヘッドによるものです。しかしながら、OpenMPの改善により、32BLKケースでは1.4倍高速化しています。
| Test Cases | Wall clock time to perform 1 time step(in seconds) | |||||
| Original code | New code | |||||
| 1 thread | 8 threads | 1 thread | 8 threads | 16 threads | 32 threads | |
| 4BLK_3M | 82.4 | 27.1 | 114.5 | 30.5 | 26.3 | 25.4 |
| 4BLK_12M | 396.3 | 122.2 | 544.15 | 137.4 | 122.0 | 115.0 |
| 32BLK_3M | 12.63 | 5.7 | 16.4 | 4.0 | 4.0 | 4.6 |
| 32BLK_12M | 62.5 | 27.2 | 62.8 | 18.5 | 18.1 | 18.5 |
4.6 コンパイラー性能比較
プロジェクト開始前に、BOFFSはGCCよりPGIコンパイラーの方が性能が良いことが解っていたことから、補プロジェクト目標として、コードをPGIでコンパイル可能なようにすることが設定されていました。その結果として、新しいVOFFSの性能を、HECToR上のコンパイラーGNU(GCC)、PGI、Cray(CCE)を用いた場合について示します。
BOFFS性能で最良のコンパイラーオプションは以下の通りです:
GCC 4.6.3 FLAGS= -Ofast -fopenmp PGI 12.5.0 FLAGS= -fast -mp CCE 8.0.6 FLAGS= -O ipa1
図4から7は、一般にCCEが最も性能が良く、時点でPGIが良いことが示されています。
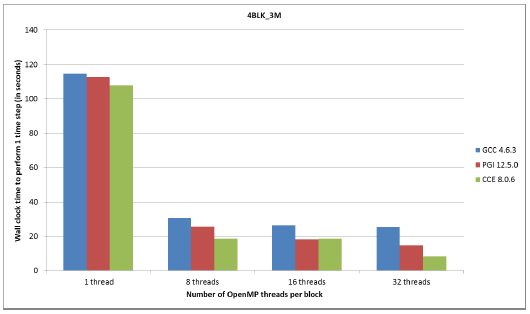
図4:3百万グリッド、4ブロックケースのコンパイラー別性能
図4,5で示されるように、OpenMPのスケーラビリティーは4BLK_3Mと4BLK_12Mテストケースの場合に優れています。これは、ブロック当たりのグリッド数が大きい(750,000および3百万)ため、8スレッドから32スレッドにおいて性能向上の余地が大きいことが要因です。8スレッドまでのスケーラビリティーは、全てのケースで良好です。
実行の全ては、8コアのNUMAダイ当り高々1つのMPIタスクで実行され、4BLK_12Mの場合には、メモリー要求のために、1つのinterlagosチップの16コアにMPIタスクを割当てました(つまり、ノードの半分を用いる)。図5,7の4BLK_12Mおよび32BLK_12Mテストケースでは、PGIおよびCCEによる性能は1.5倍高速でした。
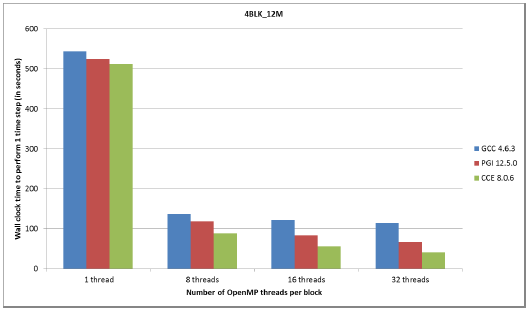
図5:12百万グリッド、4ブロックケースのコンパイラー別性能
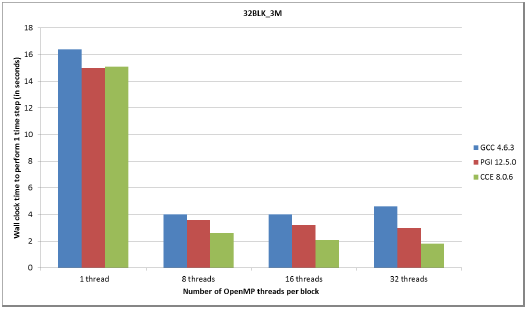
図6:3百万グリッド、32ブロックケースのコンパイラー別性能
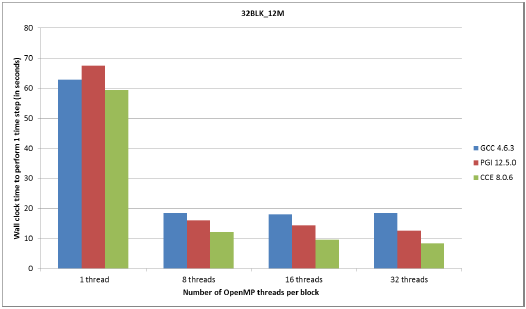
図7:12百万グリッド、32ブロックケースのコンパイラー別性能
5 シミュレーション例
本報告の最後として、HECToR上のBOFFSを用いた、LESおよびRANS-NLESハイブリッドシミュレーションの最近の結果を示します。
5.1 高圧タービン
図8は、高圧タービンブレード(HPT)のBOFFSによる計算から得られた瞬間流れ場で、ブレードのスパン方向に生成した、剥離した大規模渦構造を示しています。
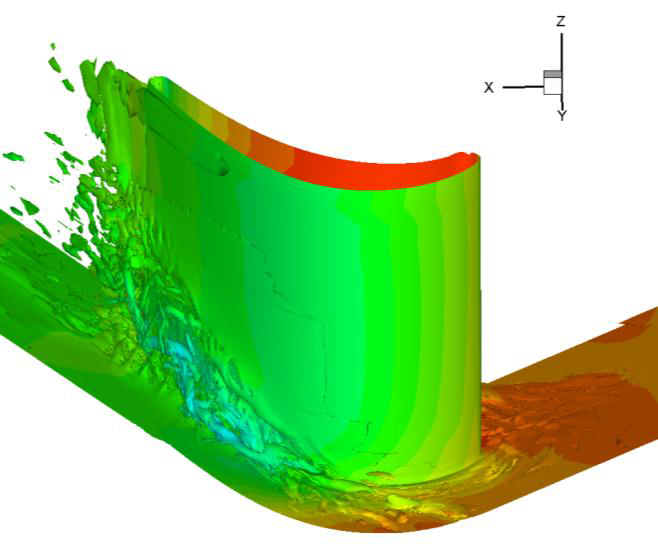
図8:RANS-NLESによる高圧タービン内の流れ
5.2 定圧タービン
定圧タービンブレード(LPT)の代表例として、圧力勾配を課した平板のBOFFSシミュレーションを示します。計算領域の上部境界は、図9に示すように、流れ方向に圧力勾配を課すような形にしています。
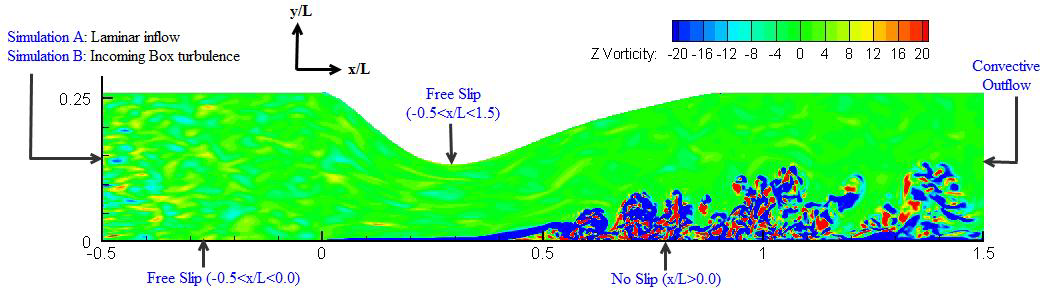
図9:計算領域と境界条件。入力box乱流と共に、z方向の流速のコンターを示しています。
これは、LPTブレードの先端周囲の流れの例です。主流乱流の入力有/無の2つのシミュレーション結果を、それぞれA,Bとラベルしています。入力乱流強度は、シミュレーションBでは4%に設定してあります。
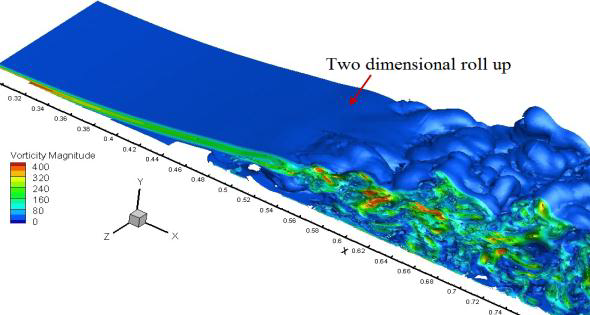
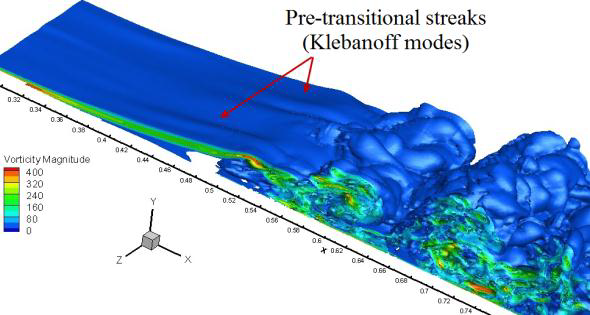
図9:層流入力シミュレーションA(左図)、および乱流入力シミュレーションB(右図)の速度等値面。
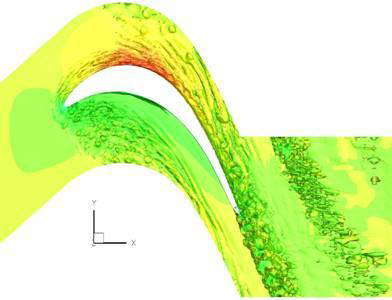
図11:T106Aブレードの、周期的後流により誘起される遷移と端壁の流れ。
図11は、シミュレーションAとBの測度の等値面を示ししています。遷移前の剥離剪断層はシミュレーションA ではほぼ2次元面であるのに対し、シミュレーションBでは、明らかにスパン方向にうねりが生じています。このうねりは、Klebanoffモードと呼ばれる現象です。乱流解像の成功には、LPTのモデリングに際してこうしたモードを捕捉することが必要となります。
5.3 リムシール
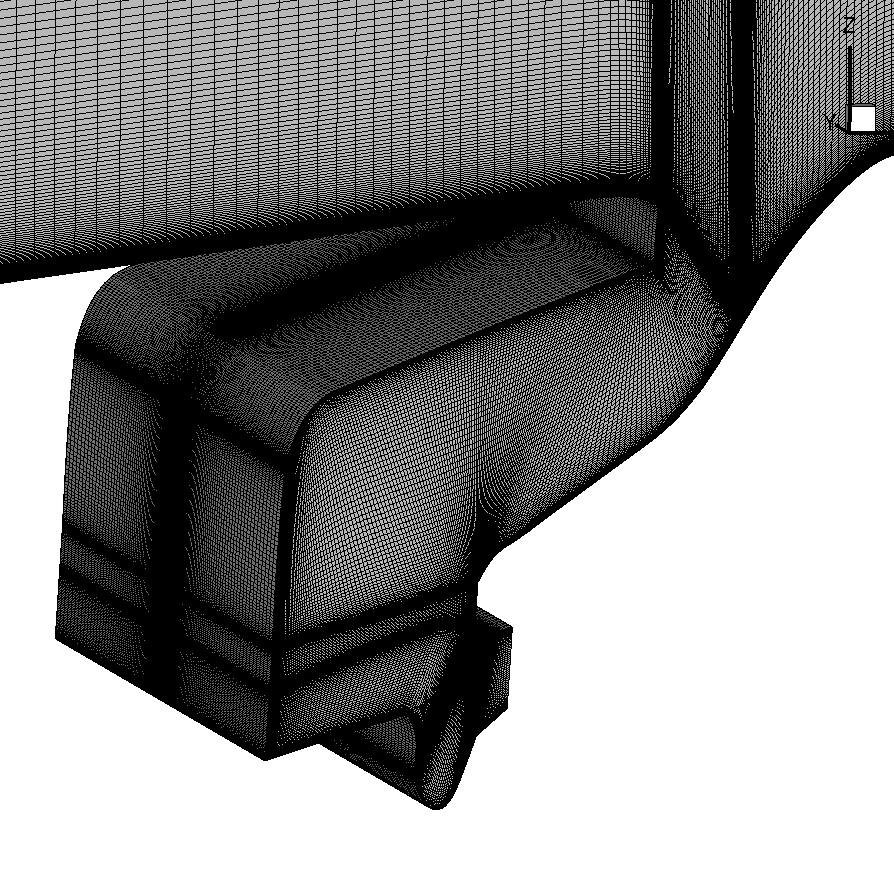
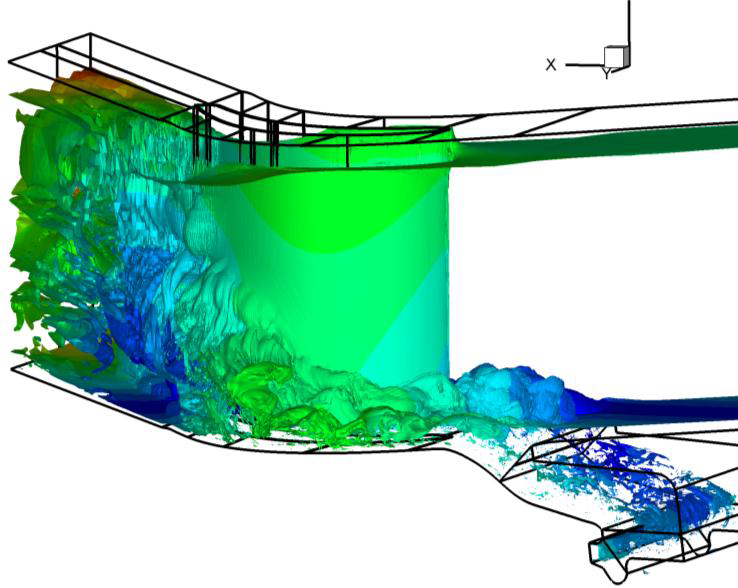
図12:LSEで用いたキャビティのグリッド(左図)、およびキャビティ形状の乱流強度等値面。
BOFFSは、的確なモデリング手法を用いて、シール材流と主流の相互作用をより深く研究することが可能です。一例として、図12(左図)は、リムシール・キャビティ流が主通路側壁と剥離領域に影響を与えることを示しています。LESとRANS-NLESハイブリッドシミュレーションにより、複雑な流体システムの研究をより詳細に実施することが出来、実験的なリグ試験よりも低コストです。
5.4 ラビリンスシール
ラビリンスシールの構造を図13に示します。これは、ブレードチップ/シュラウドやインターナルエアシステムで見られる現象の代表例です。このシールが生成する流れも複雑です。ここには、大きな加速や剥離、再循環、高速回転側壁が存在します。
図13(右図)は、流れ場の渦度の等値面を示しています。回転壁近傍に高渦度が有り、境界層タイプの流れを示し、渦が歯先から流されています。この流れは、後流および境界層タイプの乱流を含んでいます。
ここで示した全てのシミュレーションは、500コアを用いて1か月未満で計算可能です。
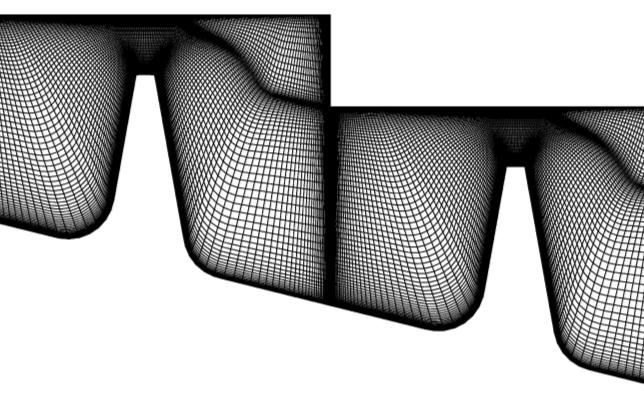
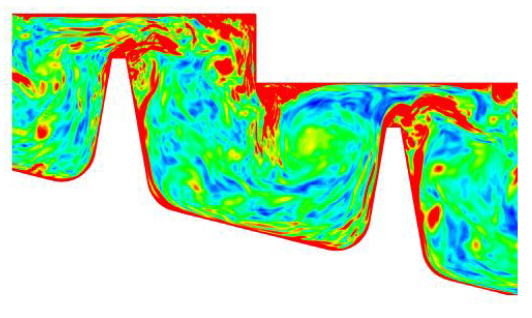
図13:ラビリンスシールのメッシュ(左図)、およびそのLES流れ場の渦度等値面。
6 結論
本プロジェクトの目的は、BOFFSコードの性能を、少なくとも20%高速化し、また少なくとも100ブロックまでスケーラビリティーを引き上げる事でした。セクション4では、この目標が達成されたことを述べ、OpenMPのスケーラビリティーも全体として8スレッドまで改善されました。特にPGIあるいはCCEでコンパイルした新しいコードは、12百万グリッド/4,32ブロックケースの場合、平均で1.5倍に高速化しました。さらに、12百万グリッド/4ブロックケースは、ブロック当たり3百万グリッドの例ですが、それより30倍大きな100百万グリッド以上および100ブロック以上まで、BOFFSは比較的良好な弱スケーリング性能を示しました。
BOFFSは多目的のオーバーセット構造コードとして、熱およびクーリングフィルム法を含む様々なターボ機械の問題にHECToR上で適用されていくことでしょう。これは、HECToRでジョブ当り4,000AUが必要な、広域ノイズ計算プラットフォームとしても提供されます。直近では、Cambridge UGTP Whole Engine Computational Aeroacoustics Consortiumのメンバーとのコラボレーションが計画されており、HECToR計算リソースのEPSRC研究予算を獲得しました。dCSEチームは、以前の研究で得られた新たなアイデアの開発とテストをHECToR上で容易にする作業を計画しています。また、UK Applied Aerodynamics HECToR consortiumを通して、国際的な先端的研究グループやより広いHPCコミュニティーとのコラボレーションも計画しています。BOFFSは、更に多くの研究予算による、複雑形状hot jetの空気力学、音響力学調査を計画しています。
謝辞
このプロジェクトは、nAG Ltd.が運営するHECToRの分散計算科学および工学(CSE)サービスの基に実行されました。英国の国立スーパーコンピューティング・サービスである、HECToR:英国リサーチ・カウンシル・ハイエンド計算サービスは、リサーチ・カウンシルを代行するEPSRCが管理しています。そのミッションは英国学術界の科学および工学の研究支援です。HECToRスーパーコンピューターは、UoE HPCx Ltd.およびnAG Ltd.のCSEサポートサービスにより管理運営されています。
文献
| [1] | Georgiardis, N. & DeBonis, J., 2006, "Navier Stokes Analysis Methods for Turbulent Jet Flows with Application to Aircraft Exhaust Nozzles". Progress in Aerospace Sciences., Vol. 42, pp. 377-418 |
| [2] | Secundov A. N., Birch S. F. and Tucker P. G. 2007, "Propulsive Jets and their Acoustics", Philosophical Transactions of the Royal Society (Series A: Mathematical, Physical and Engineering Sciences) Vol. 365, pp. 2443-2467. |