
Phil Ridley and Yiqi Qiu
Numerical Algorithms Group
October 7, 2013
概要
ターボ機械設計において、レイノルズ平均ナビエ・ストークス(RANS)モデルは、対流後流や大規模剥離、複雑な渦構造などの非定常性が支配する乱流の取り扱いに、通常は困難に直面します。これらは、基本的な噴流でさえ、RANSや非定常RANSへ理論的な疑問を提示します。一方、Large-eddyシミュレーション(LES)は、乱流構造をRANSのように近似することなく、数値的に解像するため、極めて信頼できる手法です。しかしながら、LESは、複雑な乱流構造を捕捉するために、億のオーダーのグリッド点を必要とします。乱流の揺らぎの4次の時空間的な補正の標準的なシミュレーションでは、12時間以上の長時間が必要です。本プロジェクトの目的は、構造CFDコードBOFFSおよびNEATの性能改善であり、メニーコアHPCマシンの有効活用です。その標的は、ブロック間転送のMPI通信であり、そのメモリーの有効利用と、ブロック内計算でのOpenMP性能の改善です。柔軟な並列データ分割実装により、BOFFSの複雑なグリッドでのスケーラビリティーを改善します。ソルバーの最適化とOpenMP並列実装により、NEATの性能とスケーラビリティーを改善します。
目次
1 イントロダクション
1.1 全体概要
1.2 BOFFSコードの説明
1.3 NEATコードの説明
1.4 プロジェクトの概要
2 HECToRフェーズ3への実装
2.1 BOFFS
2.2 BOFFSの性能
2.3 NEAT
2.4 NEATの性能
3 BOFFSへの柔軟なブロック割当て手法の実装
3.1 実装
3.2 性能比較
4 NEATの線形ソルバーへのOpenMP実装
4.1 実装
4.2 性能比較
5 結論
6 謝辞
1 イントロダクション
1.1 全体概要
航空機エンジンの設計において、フルスケール実験は極めて高コストであり、CFDの活用が極めて重要です。ここでは、高解像度空気力学モデルと大規模HPC資源の活用が重要です。航空機エンジン流は乱流であり、時空間の広い範囲に渡るためモデル化が課題です。乱流の性質は、通常レイノルズ平均ナビエ-ストークス(RANS)方程式で解かれます。しかしながら、RANSおよび非定常RANSは、設計において正確性や信頼性共に適切でないことが知られています[1]。正確なモデリングおよびこうしたタイプの流れの理解に適切な手法はLarge-Eddy Simulation(LES)です[2]。この流体の物理のほとんどは、RANSのように平均効果をモデル化するよりも時間と空間で解像されるものですが、LESは明示的な乱流モデルにこのような高い要求を必要としません。
しかしながら、LESの大きな弱点は、複雑な流体構造を解くのに膨大な計算リソースが必要になることです。壁面ストリーク構造ととらえるためには、億オーダーのグリッド点が必要になります。さらに、音響で用いられるような統計平均を計算するには、低周波データを正確に取得するために膨大な実行時間が必要になります。
本プロジェクトは、主に航空機エンジン設計で用いられる2つのアプリケーションについて、HECToR上の性能を改善します。その一つがBlock Overset Fast Flow Solver(BOFFS)で、もう一つがNEATです。これらは、複雑な流体を構造化されたマルチブロック領域分割でモデル化します。これは、大きなリソースが必要な非構造ソルバーに比べて小さなオーバーヘッドを持ちます。
BOFFSは、HECToRにおいて様々なガスタービンエンジン部品の研究に用いられています。そこには、高圧タービンブレードや、定圧タービン、リムシール、ラビリンスシールが含まれます。このコードはまた、タービンブレードの表面粗さの影響調査にも用いられています。近年シミュレーションはタービン開発のための高忠実CFDを可能にしており、そこでは、十分な正確性や、より少ないコストで(可能であれば)リグ試験を置き換える一貫性が要求されます。一方、このことは、タービンで生じる複雑な流体の正確なモデリングのための設計サイクルの自動化を促進します。BOFFSで用いられている高次スキームやオーバーセット手法は、構造格子へ任意の複雑な設計構成を可能にし、理想的なLESツールとして位置付けるものです。
NEATも、様々な複雑な流体の研究に用いられ、LES,RANSおよび直接数値シミュレーション(DNS)を用います。NEATは、カルテシアン構造グリッドを用いた多くのRANS、LESモデルを使い、離散スキームの数値品質で、フレキシブルな、セル面への高次補間ステンシルによる時空間離散化手法を持っています。このコードは、LESを用いたよりカノニカルな乱流の効率的モデリングやRANSモデルのリファインに特に適しています。NEATも世界で広く用いられており、最近は、タービン冷却通路の熱伝導やラビリンスシールの高加速流のモデリングにも用いられています。
1.2 BOFFSコードの説明
BOFFSは、6面体構造メッシュ上の3D非定常ナビエストークス方程式を高次スキームで解き、任意の複雑な形状に対してマルチブロックオーバーセット(キメラ)グリッドを生成する機能を持ちます。BOFFSは、乱流についてはRANS、非定常RANS、LESを用います。このコードは、オーバーセット構造グリッドによるLESの実行に専ら用いられ、主たる応用はターボ機械です。
対流項は流束分離法を用いて解き、Van Leer[3]によるMonotone Upstream Centred Scheme(MUSCL)法がベースです。非粘性項には6次以下の中心差分が可能です。時間積分はガラーキン法[4]で、二重時間刻み法と疑似時間の繰返しと共に用います。面と線上の陰的緩和スキームに必要な線形システム解法には、三重対角法(TDMA)およびガウス-ザイデル法(GS)が可能です。
BOFFSのマルチブロック性は、並列データ分散の便利なプラットフォームで、多くのマルチブロックコードに共通した性質です。ここで、BOFFSの動作には4種類あります:シリアル実行(非並列かつブロック分割無し)、OpenMP並列(ブロック分割無し)、MPI並列(グリッドブロックの分割)、MPI/OpenMP並列(MPI並列とTDMAやGSルーチンでのOpenMP並列)。シリアル実行の場合、各ブロックは順次処理されます。並列ケースでは、各サブ繰返し(非定常計算の場合)やグローバル繰返し(定常計算の場合)において、圧力、速度場成分、スカラー変数はMPIによりブロック間で転送されます。
1.3 NEATコードの説明
NEATは3D非圧縮性流体ソルバーで、主にLESで用いられます。このコードはスタッガード構造カルテシアンメッシュを用います。複雑流体研究のための、任意のソリッド領域が定義可能です。LESに加えて、様々な乱流モデルを含むRANSおよび非定常RANSを用いることが出来ます。また、収束加速にマルチグリッド法を装備しています。現在NEATは、主にLESで用いられ、ターボ機械、電子機器冷却やその他の領域での熱伝導に適用されています。
ソルバーの中では、セル面の流れを得るのに二次の中心差分を用い、時間発展に二次のクランク-ニコルソン法を用います。より高次の離散化も可能です。各時間ステップは、各変数の収束のための多くの繰返しループを含みます。圧力と速度場は、Semi-Implicit Method for Pressure Linked Equations(SIMPLE)法を用いて連携します。スタッガードグリッドは、(圧力チェッカーボード問題のような)数値計算問題を回避させるのに役立ちます。グリッドの線、平面、体積上の計算にはGSおよびTDMA法を用います。
1.4 プロジェクトの概要
本プロジェクトは、BOFFS、NEAT両方に対して、HECToRや他のメニーコアHPCマシンで十分効率的に動作する事を目的に開発を行います。この作業の全体目標は、100百万点と数千ブロックのグリッドを用いて、これらソルバーを効率的に活用することにより、更なるターボ機械研究を推進することです。BOFFSとNEATは共にマルチブロック・コードですが、幾つかの機能的な違いがあります。NEATはBOFFSと違い、圧力速度場結合にスタッガードグリッドを用いますが、BOFFSは曲線(curvilinear)メッシュと、圧力チェッカーボード問題回避のため空間スキームに明示的な平滑化を用います。
本プロジェクトの目標は以下の通りです:
WP1:BOFFSでの柔軟なMPIプロセス割当ての実装
BOFFSの既存の並列分割コードは、各グリッドブロックが一つのMPIプロセスへ割当てられるように設計されています。各MPIプロセス内への並列機構の追加は、OpenMPスレッド群をグリッドブロック内に割当てることで達成されます。複数のブロックを一緒にして、各MPIプロセスにマルチブロックデータを割当てることで、新しいMPIの分割手法を実装します。
BOFFSには2つの通信サブルーチンが存在します:一つはバッファ間でパッキングと送信を扱い(packvar_send)、他方は受信とアンパッキング(recvvar_unpack)をします。これらのサブルーチンに対して、MPIプロセス当たりの様々なブロック数に応じられる柔軟な手法を組み込みます。更に、ブロックの割当てをユーザー指定する構成ファイル'mpi_cfg.in'の読み込み機能も実装されます。
分割の柔軟さの有効性を評価するために、50百万セルと100グリッドブロックの複雑な構造のテストケースをHECToRで実行します。これにより分割の実行時間は、元のMPI当り1ブロックの分割手法に比べ、少なくとも2割の削減を示すでしょう。
WP2:NEATのTDMA,GSルーチン内へのOpenMPの実装
NEATもマルチブロック構造グリッドを用いるため、BOFFSと同様に、MPI当り1ブロックの分割手法を用いています。しかしながら、BOFFSとは違い、プロセスへのマルチブロック割当ては、NEATでは実行時間の改善に大きな効果があるわけではありません。何故なら、全実行時間の50%あるいはそれ以上が、線形システムソルバーとその関連ルーチンが占めているからです。NEATには2つの線形ソルバー:TDMAとGS、が有ります。これらは共に、最適な数値的収束を達成するために各平面(x,y,z)で用いられ、その選択は流れの性質に依ります。
TDMAとGSルーチンはサブルーチンsolve3に在り、1400行以上のコードです。本作業は、これらルーチンへのスレッドセーフなOpenMP実装であり、少なくとも20以上のループの開発が必要です。ルーチンsolve3では、ほとんどの変数がスレッド内でPRIVATEに宣言され、可能な限りCRITICALを用いずに、NO WAITを用いて動的スケジューリングさせます。MPI実装コード内において効率的にハイブリッド性能を達成するために、マスタースレッドのみMPI呼出しを行うようにします。こうして十分大きな問題において、NEATはMPIプロセス当たりのコアをより多く利用することが出来ます。
新しいハイブリッド並列分割では、各MPIプロセスは単一ブロックで動作しますが、ブロック内ではOpenMP並列がTDMAとGSソルバーへ追加されます。新しいハイブリッド並列コードの性能実証のために、128ブロックと8つのOpenMPスレッド(プロセス当たり8スレッドの128個のMPIプロセス)を用いた非定常流れのテストケースを用いて、元のコードと比較しました。実行時間で20%以上の削減が見込まれます。
WP3:NEATのその他の補助ルーチン内へのOpenMPの実装
NEATでは線形ソルバーとその他の補助ルーチンで50%の実行時間が掛かり、それぞれ約40%および10%の割合です。よって残りの作業は、補助ルーチンのスレッドセーフなOpenMP実装です。これらは、速度場U,V,W、圧力、温度の節点変数への重みを付ける係数とソース項(coeffu,coeffv,coeffw,coeffp,coefft)の計算に用いられます。これらの各ルーチンは約200行で、OpenMP並列が必要なループを2個か3個含んでいます。
これらOpenMP性能の検証のために、WP2と同じテストケースを用います。この実装により、WP2のコードから更に3%の実行時間削減が期待されます。
2 HECToRフェーズ3への実装
2.1 BOFFS
BOFFSは、約22KラインのFortran90コードです。MPIは、コードがブロック分割を用いた場合に、圧力、速度場、温度という物理的な流体変数の通信に用いられます。OpenMPは、TDMAとGSルーチンにおける並列化に用いられます。コードのセクションは主に、グリッド前処理(およびリスタートのための流体計算処理)と、時間積分、ポスト処理に分けられます。可視化のための出力ファイルは、リスタートファイルと共にPLOT3D形式のバイナリーファイルとして出力されます。
計算部分においては、最初に境界条件とメトリックが設定され、次に時間積分のメインループにおいて、方程式右辺が構築され、TDMAとGSによる陰的緩和スキームで解かれます。ソルバーの選択は、メッシュと流体特性に依ります。境界値と配列内容は、次の繰返しの前に更新されます。効率よりも保存量の低減のために、このシンプルな解法はCFDソルバーで広く採用されています。
2.2 BOFFSの性能
BOFFSは、単純なグリッドの場合(そのグリッドが、ブロック当たり1,2個の隣接グリッドを持つ場合)は少なくとも1000コアまで良好なスケール性能を示します。このようなグリッドは、「ブロック」に分割され、その一つのブロックへ一つのMPIプロセスが割り当てられます。しかしながらオーバーセットメッシュの複雑なグリッド構成では、ブロック隣接数は様々で、このブロック分割手法は適しません。
このような構成では、例えばクーリングホールが有る場合のように、グリッドに中央セクションが存在する場合があり、それらは特殊なメッシュタイプ、少数のグリッドから成る「コア」ブロックであるため、別種のブロックとして扱われます。ブロック分割はメッシュのトポロジーに支配されるため、グリッドに対する元のMPIデータ分割手法では、ブロック当たりの隣接数が分散して、スケーラビリティーが悪化します。そこでWP1では、MPIプロセスに複数のブロックを割り当てる柔軟な分割手法を実装しすることにより、データ転送性能を向上させました。
2.3 NEAT
NEATもFortran90コードで記述されており、約30Kライン、約20サブルーチンから成ります。BOFFSと同じく、MPIを物理的な流体変数の通信に用います。
シミュレーションの最初において、前処理は壁距離計算を行い、(必要であれば)高次スキームの多項式係数を計算します。時間積分メインループ内の陰的ソルバーは、TDMAとGSを用います。シミュレーションの最後に、流体データは、リスタート用のバイナリーファイルと、可視化のためのTecplot360形式でアスキーファイルに出力されます。
2.4 NEATの性能
NEATの並列性能と効率は、あるグリッドと問題サイズに対しては良好ですが、大きなグリッドや256コア以上では悪化します。プロファイル解析から、実行時間の46%がsolve3(TDMAとGS)、次に29%が、補助ルーチンに掛かっています。ルーチンsolve3の非効率性は、MPIプロセスに掛かる時間のインバランスが原因で、最も遅いMPIプロセスは最速のものに対して2倍時間が掛かっています。
よってWP2は、solve3のメインループ内にOpenMPを実装することによりNEATの並列性能を改善します。同様にWP3は、補助ルーチンの並列性能を改善します。TDMAとGSソルバーに対してOpenMPによるred-black法を適用することにより、各MPIプロセス(あるいはブロック)は効果的にハイブリッド並列実行が可能です。OpenMP化はまた、大規模問題サイズでの少ないグリッドブロックに対して、より多くのコアを用いる事も可能にします。
3 BOFFSへの柔軟なブロック割当て手法の実装
3.1 実装
最初に配列exchangematrix(1:MaxNBlkMPI, 1:MaxNBlkMPI)を修正します。これは、隣接プロセス間で渡されるデータ用のMPIメッセージバッファサイズを保存するものです。この配列は、全MPIプロセス(MaxNBlkMPI数)でコピーされます。各プロセスは、送受信する隣接データバッファサイズのみを知る必要があることから、このサイズをローカル配列RecSize(1:MaxNBlkMPI)とSendSize(1:MaxNBlkMPI)へ保存したほうが効率的です。
元のBOFFSのMPI分割は、MPIプロセス当たり1ブロックに固定されています。よって次にやることは、ユーザーコンフィグレーションファイルmpi_cfg.inへ、柔軟なMPIプロセス割り当てを記述する機能を追加することです。このファイルは、マスタープロセスで読み込まれて、他のプロセスへブロードキャストされます。以下のデータが読み込まれます(ここで、MaxNBlkiは各プロセスでの実際のブロック数です):
プロセスiのMaxNBlki値 (ni),…,(i=0,MaxNBlkMPI-1) プロセスiのブロック数リスト (ni entries),…,(i=0,MaxNBlkMPI-1) (ここで、σni=総ブロック数) 例:MPIプロセス当たり1ブロックで、12MPIプロセスへ12ブロックを割当てる場合: 1,1,1,1,1,1,1,1,1,1,1,1 1,2,3,4,5,6,7,8,9,10,11,12 例2:5MPIプロセスに12ブロックを割当てる場合: 3,3,3,2,1 1,2,3 4,5,6 7,8,9 10,11 12
プロセスiのブロック数リストは、プロセス/ブロック割当ての決定手法のために、昇順で指定する必要があります。データは配列num_rankblock(1:MaxNBlkMPI)へコピーされ、この配列は各プロセスのMaxNBlk値を保存し、ローカルからグローバルブロック番号への対応リストrank_block(1: num_rankblock(1: MaxNBlkMPI),MaxNBlkMPI)も保存されます。
シリアルフォーム(mpi_flag==0)と並列フォーム(mpi_flag==1)を比較すると、元の分割の修正により影響を受けるBOFFSのコードには、以下のループ構造が有ります(以下においてnumblocksはブロック総数を意味します):
IF (mpi_flag==0) THEN DO i = 1, numblocks … CALL currentblock(i) ! set offsets for data pval(i,:,:,:)等のローカル配列の計算 … END DO ENDIF IF (mpi_flag==1) THEN … CALL currentblock(my_rank) ! set offsets for data pval(my_rank,:,:,:) 等のローカル配列の計算 … ENDIF
並列の場合は、各プロセスはそれ自身のブロック(すなわち、元のコードでは1ブロック、新しいコードは複数ブロック)のみを扱います。ですが、シリアルの場合は全てのブロックを順繰りに扱います。そこで、以前のループ構造を以下のように置き換えます。
DO i = 1, numblocks CALL currentblock(i) ! set offsets for data setblock = .FALSE. IF (mpi_flag==0) THEN setblock = .TRUE. nblock = i ENDIF IF (mpi_flag==1) THEN nrcheck = num_rankblock(my_rank) DO rcheck = 1, nrcheck IF (rankblock(rcheck,my_rank)==i) THEN setblock = .TRUE. nblock = nblock+1 ENDIF END DO ENDIF IF (setblock) THEN … nblock<MaxNBlkの場合のローカル配列pval(nblock,:,:,:)の計算。 … ENDIF ENDDO
こうして、特定の各MPIプロセスはそれ自身のブロックのみを扱うことになります(setblocksがTRUEの場合)。この新しいループ構造の実装は、105箇所以上に渡りました。さらにルーチン:externalblockboundariesmpi, packvar_send and recvvar_unpackについても、追加のデータ保存が必要なため、修正されました。
サブルーチンexternalblockboundariesmpiは、ローカル変数の更新を行います。このサブルーチンは、更新データを隣接ブロック境界へ送信する前と、更新された境界値を隣接MPIプロセスから受信した後に呼ばれます。元のブロック分割では、MPIプロセス当たり1ブロックに固定されていましたが、新しい方法では複数ブロックが存在します。よって、externalblockboundariesmpiは、ローカルブロック(同じMPIに割当てられたブロック)と外部ブロック(隣接MPIプロセスに割当てられたブロック)を扱うように修正されました。
ローカルブロックと外部ブロックを区別して扱うようにするために、各MPIプロセスでLOGICAL配列mpineighs(1: MaxNBlk)を定義しました。この配列の要素は、各ローカルブロックを全ての他のローカルブロック間で一度だけチェックして作成されます。これは、配列rank_block(ローカル/グローバルブロック番号リスト)を用いて、ローカルブロックであればmpineighs(i)をFALSEに、外部ブロックではTRUEにすることで実装します。そこで、externalblockboundariesmpiにおけるローカル変数の新しい更新方法は、最初に外部ブロックに対して実行し、次にローカルブロック境界を実行します(ローカルブロックそのものに対しては実行しません)。
サブルーチンpackvar_sendとrecvvar_unpackは、データバッファーのパッキング/アンパッキングを実行します。ここでパッキング/アンパッキングにおけるブロックの順序について考える必要があります。これは、元のMPIプロセス当たり1ブロックの状況では不要なものです。その順番のために、ローカル配列rankneigh(1:3, 1:MaxNBlk)を各MPIプロセスへ追加しました。この配列要素には、(from_block)からのコピーを必要とするブロックデータのグローバル番号と、(to_block)へのコピーが必要なブロックデータのグローバル番号と、隣接MPIプロセス番号(つまり、ここでMPIプロセスのグローバル番号を決定できます)を含みます。
ブロックデータバッファーのアンパッキング時に正しい順序を達成するには、さらにローカル配列unpackord(1: MaxNBlk)も必要です。これは、アンパッキングされるブロックの間接アドレッシングのためのルックアップテーブルです。これは、各MPIバッファーには複数のブロックデータが含まれているため、正しい順序でブロックをアンパッキングするのに必要となります。つまり、各MPIプロセスは、元のデータがパッキングされた順序を知る必要があります。例えば、MPIプロセス1と3が隣接するブロックを持っている場合、プロセス1から3へデータを送信する際に、プロセス1からのデータが(1,8) (1,9) (2,9) (3,7)の順序でパッキングされ、プロセス3から(7,3) (8,1) (9,1) (9,2)の順序(つまり、プロセス3でパッキングされた順序)で受信する可能性があります。この場合には、プロセス3からのデータの正しいアンパッキング順序は、配列unpackordを参照して得ることが出来ます。
最後に、データをパッキング/アンパッキングする際に正しくバッファーを扱うために、バッファーへ/から新しいデータを追加/取得する際のオフセットも保存しなくてはなりません。ブロック境界の幾つかのローカル変数は、一つかそれ以上の別のブロックへ通信されなくてはなりません。そこで、配列countn(1: MaxNBlk)を追加します。これは、データバッファ内で、各隣接MPIプロセスからの次のローカルブロックデータがどこに在るかを示す先頭位置が保存されます。
3.2 性能比較
柔軟なブロック割当てを用いた新しいBOFFSの性能を、HECToRフェーズ3で検証しました。テストケースには、亜音速噴流のLESについて、50百万グリッドと108グリッドブロックを用いました。このケースの遷移状態を図1に示しました。図2に示す複雑なグリッドを用いています。ここでは異なるブロックを、色を変えて示しています。軸に関する特異性を避けるために、中央に「コア」ブロックを置きました。この領域は、図2(a)の水平線上の黒色で示す薄い矩形領域として表現されています。中央外の「コア」ブロックは、x,y方向に比較的少数の点を含んで領域に渡って伸ばされていることに注意してください。元の1ブロック/1MPIの割当て手法では、図2(a)で示すように、「コア」領域周囲には色付けされた膨大な隣接ブロックが存在します。新しい柔軟なブロック割当てを用いると、図2(b)に示すように「コア」領域は多数のより小さなブロック(マルチ「コア」ブロック)に分割されます。ここで、周囲の局所ブロック群を同じMPIプロセスへ割当てれば、各MPIは同程度の隣接数になり、負荷バランスとスケーラビリティーの改善が見込まれます。

図1:50百万グリッドを用いた亜音速噴流のLESについてのU速度場の等値面

(a)

(b)
図2:噴流メッシュに対する(a):シングル「コア」ブロックでのブロック構造と(b)マルチ「コア」ブロックを用いたブロック構造
10時間ステップ実行時の経過時間を、aprunパラメーターと併せて表1に示します。この結果はGCC 4.7.2とPGI 12.10.0を用いたものです。PGIのフラグは、-fast Mipa=fast、GCCでは、-Ofast -funroll-loops -ftree-vectorizeを用いました。
| N | n | d | S | mppwidth | Time(s) GCC | Time(s) PGI |
| 108 | 4 | 1 | 1 | 864 | 144.92 | 151.81 |
| 108 | 4 | 2 | 1 | 864 | 102.79 | 114.13 |
| 108 | 4 | 4 | 1 | 864 | 78.76 | 89.23 |
| 108 | 4 | 8 | 1 | 864 | 67.28 | 78.87 |
| 54 | 8 | 1 | 2 | 224 | 231.61 | 243.08 |
| 54 | 8 | 2 | 2 | 224 | 124.05 | 132.77 |
| 54 | 4 | 4 | 1 | 448 | 72.18 | 77.70 |
| 54 | 4 | 8 | 1 | 448 | 50.10 | 53.84 |
本作業の目標は、元の1ブロック/MPIプロセス割当てに比べ、新しい柔軟な分割が20%の時間削減を示すことでした。期待されるよりも良好な性能がBOFFSで達成されています。8スレッドを用いたシングル「コア」ケース(N=108)に比べ、マルチ「コア」ブロック(N=54)は、ほぼ半分のコア数を用いて実行時間は、67.28秒から50.10秒(GCCの場合)へ減少しました。
4 NEATの線形ソルバーへのOpenMP実装
4.1 実装
NEATにおいては、MPIデータ分割はマルチブロック構造をベースにしています。しかしながら典型的な実行では、全実行時間の少なくとも50%が、線形ソルバーとその補助ルーチンで費やされています。NEATではTDMAとGSという2種のソルバーが用いられています。これらは各平面(x,y,z)上で用いられ、流れの性質に依り選択され、最適化計算における数値的収束に用いられます。TDMAとGSスキームは共に、3次元のネストしたループで計算される広範に利用されている手法ですが、NEATではより速い収束のために、流れの性質を利用する修正バージョンを用いています。
TDMAとGSルーチンはサブルーチンsolve3に在り、1400行以上のコードから成り、TDMA x(non-periodic),TDMA x(periodic),GS x,TDMA y,GS y,TDMA z(non-periodic),TDMA z(periodic),GS zに対して、約18のメインループを持ちます。OpenMPを実装する前に、メインループを再構築することが性能向上に有益と判断しました。
WP2での最初の修正は、TDMAやGSのループのメモリアクセス改善でした。このループは、TDMA/GS xについてはz,y,x、TDMA/GS yについてはx,z,y、TDMA/GS zについてはy,x,z(外側から内側ループへの並び順で)と構成されています。このループは、非対角要素の係数計算と3D配列への保存に用いられます。ここでは、最内側の最初の配列インデックスを用いるTDMA/GS xに対してのみ修正しました。その他のy,zについては最内側で対応する平面内の計算のため、修正は行いません。
次に、これらループの少なくとも最内側ループについて、IF THENブロックを可能な限りループの外へ移動するか、あるいは分岐を最小限にするように修正しました。ほとんどの分岐は、以下のような実行中に変化しない境界条件に関するものだったため、修正は可能でした。
DO i=isq,id-1 IF (i==isq)THEN … ENDIF IF (i==id-1)THEN … ENDIF END DO これを以下のように書き換えました 「i=isq」の場合の計算 DO i=isq+1,id-2 「i=isq+1,id-2」の場合の計算 END DO 「i=id-1」の場合の計算
最内側から条件文を外したことにより、TDMA/GS xループはベクトル化されました。その他のルーチンに対しては、各グリッドでそれが境界であるかどうかによって値が0.0か1.0とした新たな配列を用意し、条件文処理を、配列の乗算で置き換えました。
次に、これらループの最外側に対してOpenMP並列を実装しました。ここではSTATICスケジューリングを用いましたが、テストケースに対して最も良い性能を示しました。更に、red-black法をGS法へ実装しました。当初のループはxyz順です。red-black法オーダーでは、最外側ループは偶数と奇数インデックスのループに分割されます。これらのループは、通常良く用いられるやり方通りに、独立にOpenMP並列で実行されます。本ナビエストークス方程式解法においては、7点ステンシル(3D)が用いられており、実際のループ順序がスレッドセーフな解を得られるように注意が必要です。
WP3にも同じようにして、NEATの補助ルーチンを修正しました。これらはファイルp.F,t.F,u.F,v.F,w.Fに在るルーチンです。これらルーチンは、速度場U,V,W、圧力、温度の節点変数への重みを付ける係数とソース項(coeffu,coeffv,coeffw,coeffp,coefft)の計算に用いられます。メモリーアクセス効率化のために、以下のように多くの2重ループが修正されました。
DO i=2,id-1 DO k=ks,ke IF(nbl(i,jd,k)==-1.AND.nbl(i-1,jd,k)==-1)THEN IF(((v(i,jd,k)+v(i-1,jd,k))/2)>0.0)THEN … ENDIF ENDIF ENDDO ENDDO これを以下のように書き換えました DO k=ks,ke DO i=2,id-1 IF(nbl(i,jd,k)==-1.AND.nbl(i-1,jd,k)==-1)THEN IF(((v(i,jd,k)+v(i-1,jd,k))/2)>0.0)THEN … ENDIF ENDIF ENDDO ENDDO
以上で元のMPIデータ分割へのOpenMP並列実装が完成しました。
4.2 性能比較
元のコードと新しいコードの性能比較を図3に示します。テストケースは、12,642,048グリッド点と128ブロック(すなわち、ブロック当たり98,766グリッド点)の構造格子を用いた非定常流体です。HECToRで実行し、GCC 4.7.2とPGI 12.10.0を用いました。PGIのフラグは、-fast Mipa=fast、GCCでは、-Ofast -funroll-loops -ftree-vectorizeを用いました。横軸はコードのバージョンを示します:new version1は前のセクションでの、新しい配列による乗算への修正を除く実装で、new version2は更にベクトル化された新しい配列による配列乗算を施した実装です。
実行は1000時間ステップで、実行時間はI/Oを除く計算時間のみを計測しました。MPIプロセス数は、ブロック数と同じ128固定です。使用コア数を、128〜1024まで変化させました。128コア以上では全てのコアが利用されませんでしたが、28%から36%の実行時間の削減が示されました。OpenMP並列を用いない場合(d=1)は時間が掛かっていますが、大規模問題でOpenMPを使用する場合には、本コードが有効です。
図3から、OpenMPを用いない場合でも、元のコードに比べて新しいコードは既に24%実行時間が減っています。また、MPIのみのNEATでは、PGI 12.10.0の性能はGCC 4.7.2に比べて優れています。
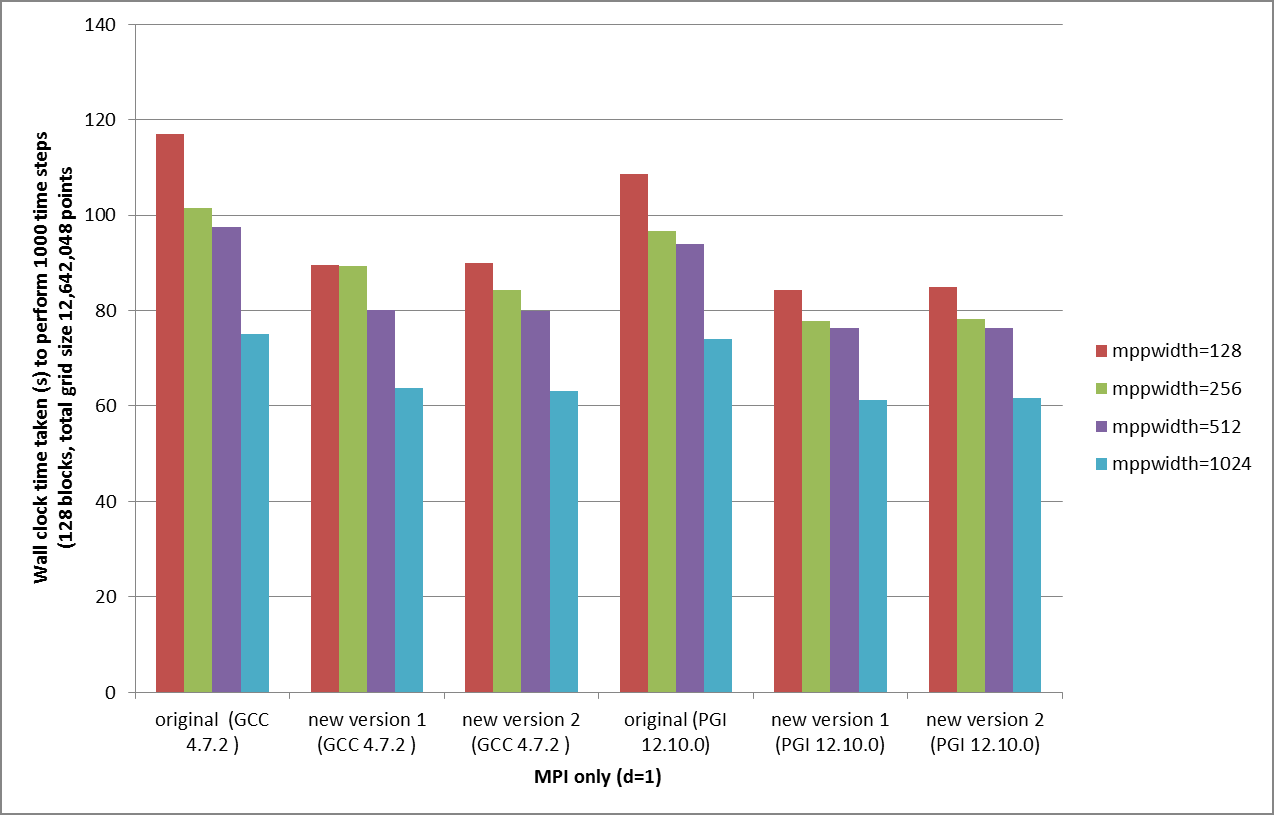
図3:OpenMP無(MPIのみの計算)での、コンパイラーとコードバージョンの性能比較
OpenMPを用いた新しいコードの性能を図4に示します。ここでは図3と同じテストケースを用いました。ここではNEATは、WP2に従ったTDMAとGSのOpenMP並列を用いた、ハイブリッド並列モードで実行されています。最初に述べるべきことは、全てにおいてGCC 4.7.2がPGI 12.10.0よりも性能が良いことです。スケーラビリティーに関しては、mppwidth=1024で8スレッドの場合とそれに対応する図3の4MPI,mppwidth=1024実行と比べると、8スレッドまでは良好と言えます。結果として、新しいコードの実行時間は元のコードの半分以下になりました。また、WP3での補助ルーチンの修正により、さらに3%の削減が認められます。
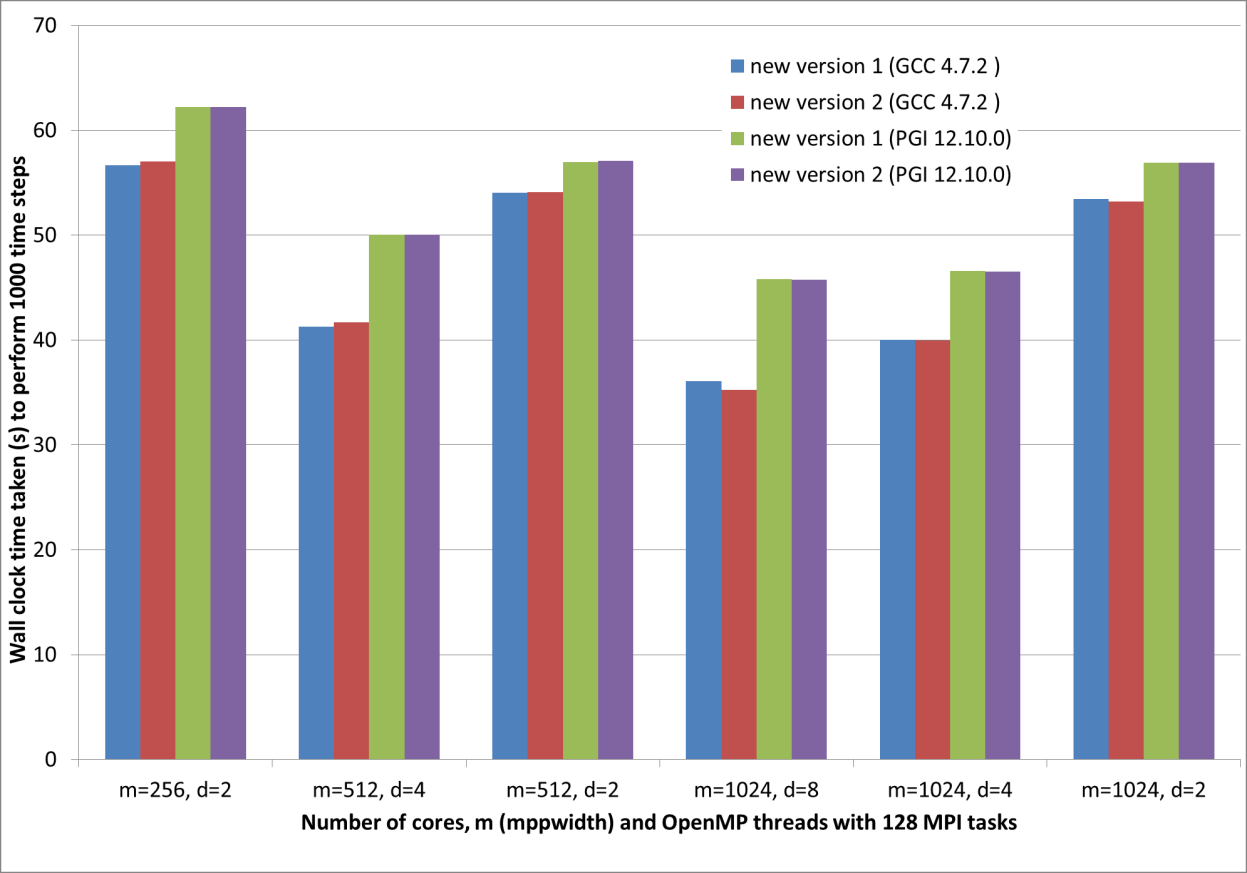
図4:OpenMP/MPIハイブリッドでの、コンパイラーとコードバージョンの性能比較
5 結論
本プロジェクトの目的は、HECToRおよび将来のハイエンドHPCアーキテクチャーにおいて、2つのマルチブロック構造格子コード(BOFFSとNEAT)の並列化実装による性能改善でした。BOFFSについては柔軟な並列データ分割を実装し、NEATに対しては、最も時間の掛かるコード部分(三重対角法、ガウス-ザイデル法および補助ルーチン)をOpenMPを用いたハイブリッド並列を実装することにより、本目的は達成されました。
BOFFSについては、新しい柔軟な分割手法が、元の1ブロック/MPI分割に比べて、50百万セル、100グリッドブロックのテストケースにおいて20%の実行時間削減が目標でした。新しい柔軟な分割手法がBOFFSに実装されました。これは、同じMPIプロセスへ任意の数のブロックを割当てることが可能です。50百万セル、108グリッドブロックを用いた亜音速噴流のLESに対して、新しい分割手法は期待以上の効果を上げました。8スレッドでのシングルコアブロック(N=108)とマルチコアブロック(N=54)の性能比較から、半分のコアを用いた場合に経過時間は、67.28秒から50.10秒へ削減されました(GCCを用いた場合)。
NEATについては、TDMAとGSソルバーをハイブリッド並列化し、128ブロック、8スレッド(プロセス当たり8スレッドの128MPIプロセス)の非定常流体テストケースにおいて、1024コアを用いたMPIのみの場合に比べ20%の実行時間を削減することが目標でした。さらに補助ルーチンへのOpenMP追加により3%の時間削減も期待されました。
新しいred-black法がNEATのTDMAとGSソルバーへ実装され、補助ルーチン内の主な計算ループのメモリー効率化を図りました。12,642,048グリッド点、128ブロック(すなわち、ブロック当たり98,766グリッド)の構造グリッド上の非定常流体を、テストケースを1000時間ステップ実行しました。メモリーアクセス効率向上とループ再構築により、MPIのみで実行した場合、新しいバージョンは元のコードと比較して実行時間で24%削減されました。これはノードを飽和させた場合の比較です。より多くのコア(mppwidth=1024)を用いた性能は、実行時間で16-18%しか削減されず、元のコードもノードが非飽和な場合は性能が向上しました。また、MPIのみで実行した場合は、BOFFS、NEAT共に、PGI 12.10.0がGCC 4.7.2の性能を上回りました。
TDMAとGSソルバーでOpenMP並列を実行したハイブリッド並列の場合も、同じテストケースを実施しました。ここでは、GCC 4.7.2がPGI 12.10.0の性能を上回りました。mppwidth=1024で8スレッドの実行は、それに対応する4MPIのみのmppwidth=1024実行と比べると、8スレッドまでは良好なスケーラビリティーを示しました。全体としてみれば、新しいコードは元のコードの半分以下の実行時間となりました。
6 謝辞
このプロジェクトは、nAG Ltd.が運営するHECToRの分散計算科学および工学(CSE)サービスの基に実行されました。英国の国立スーパーコンピューティング・サービスである、HECToR:英国リサーチ・カウンシル・ハイエンド計算サービスは、リサーチ・カウンシルを代行するEPSRCが管理しています。そのミッションは英国学術界の科学および工学の研究支援です。HECToRスーパーコンピューターは、UoE HPCx Ltd.およびnAG Ltd.のCSEサポートサービスにより管理運営されています。
有益な議論を頂きました、BOFFS開発者であるケンブリッジ大学のRichard Jefferson-Loveday博士と、NEAT開発者のJames Tyacke博士に感謝いたします。
文献
| [1] | M. A. Leschziner, "Turbulence Modelling for Separated Flows with Anisotropy-Resolving Closures", Philosophical Transactions: Mathematical, Physical and Engineering Sciences, Vol. 358, pp. 3247-3277. |
| [2] | C. Klostermeier, "Investigation into the Capability of Large Eddy Simulation for Turbomachinery Design", University of Cambridge, 2008. |
| [3] | B. van Leer, Upwind-Difference Methods for Aerodynamic Problems Governed by the Euler Equations, Lectures in Applied Mathematics Vol. 22, pp. 327-336, 1985. |
| [4] | P. G. Tucker, Computation of Unsteady Internal Flows, Kluwer Academic Publishers, Norwell, MA, 2001. |