
Paul Roberts, nAG Ltd.
31st June, 2013
概要
本dCSEプロジェクトの目的は、地震波進行コードSPECFEM3D_GLOBEの性能改善です。
元々のプロジェクト計画は、コードを解析し、一連の最適化を行うことでした。実行が不安定なケースがあったため、これに関してソースの欠陥を調査し、結果としてこのコードの安定性と効率性が改善されました。この後、コードの2つの主要部をまとめ上げ、巨大な一時ファイル(少なくとも3TB)のディスク入出力を不要にしたところ、性能が改善されました。実行時間の約8%を占めるメッシュI/Oを削除したところ、同程度の速度向上を示しました。
本プロジェクトは2012年6月に5人月として開始され、2013年6月に完了しました。本作業は、ブリストル大学・地球科学のJames Wookey博士の指導および、同Andy NowackiおよびAndrew Walker両博士の助言と助力の元に行われました。
目次
1 イントロダクション
1.1 アプリケーションの概要
1.1.1 プロジェクト開始前のコードの状態
1.1.2 メッシャーxmeshfem3D
1.1.3 ソルバーxspecfem3D
1.1.4 コードの使用と安定性
2 プロジェクトの背景
3 実装
3.1 HECToR上での問題
3.1.1 管理ノードと計算ノード
3.1.2 Crayコンパイラー・フラグ
3.1.3 CrayPATとScalasca
3.2 SPECFEM3D_GLOBE修正の概要
3.2.1 安定性解析、最適化方法、ベンチマーク
3.2.2 メッシャーとソルバーの融合
4 結論
1 イントロダクション
1.1 アプリケーションの概要
コードSPECFEM3D GLOBE[1,2]は、地球内部での地震波の伝播をシミュレートします。スペクトル有限要素法を用い、時間領域の音響-粘弾性波動方程式を解きます。また、重力の影響、減衰、表面トポロジーおよびマントル中の完全に一般化された弾性構造の組合せを可能にしています。このコードはスペクトル有限要素法(SEM)を用いるため、時間ステップ毎に要素当り発生する通信は1回のみであり、特に大規模計算に適しています。このコードは、全ての通信はMPIで実装され、I/Oと正規表現パース用の2つのC言語ルーチンを付随する、約71,000行(約380ルーチン)のFortran95コードです。上記以外にライブラリーは用いてないため、HECToRを含むHPC環境や幅広いクラスター上で用いることが出来ます。
1.1.1 プロジェクト開始前のコードの状態
現状では2つの別々の実行形式を用いています:(i)SEMメッシュを生成してメッシュファイルをディスクへ書出す;(ii)メッシュファイルを読み込んでシミュレーションを実行し、指定された初期条件に従って解く。最初のものは現状のメッシュ生成ステージで、コードが明確に記述した地震モデルに従うか、指定されたフォーマット付きデータファイルを読み込むルーチンを用いるかのどちらかです。ディスクを用いたメッシュファイル入出力を使うことで、シミュレーション実行中に再メッシュ分割必要とせずにある種の性質を変えることが可能ですが、これは数百GBのファイルを扱うことになり、実際の実行では1万ファイル程度の書き込みが必要となります。Fortranのバイナリーファイルを用いても、I/Oに掛かる時間は無視できない時間になります(全経過時間の8%程度)。
現状のコードは、静的にメモリーを確保しており、特殊な例 (例えばファイル書出し先など) を除き、パラメーター(例えば地震モデルなど)を変えるたびに、再コンパイルが必要になります。Fortran95プログラムxcreate_header_fileは、2つの実行形式(メッシャー:xmeshfem3D、ソルバー:xspecfem3D)が必要とする配列サイズをパラメーターをベースに計算し、これらのコンパイル時に必要とされるヘッダーファイルを出力します。コンパイルはCrayコンパイラーを用いて、特にオプション指定の無いデフォルトオプションで行われます。このワークフローを図1に示します。
このパッケージは、デフォルトは単精度ですが、倍精度計算も可能です。スペクトル有限差分法を用いたほとんどの実行では単精度で十分であり、同等な地震記象を示し、なにより単精度は高速で省メモリーです。
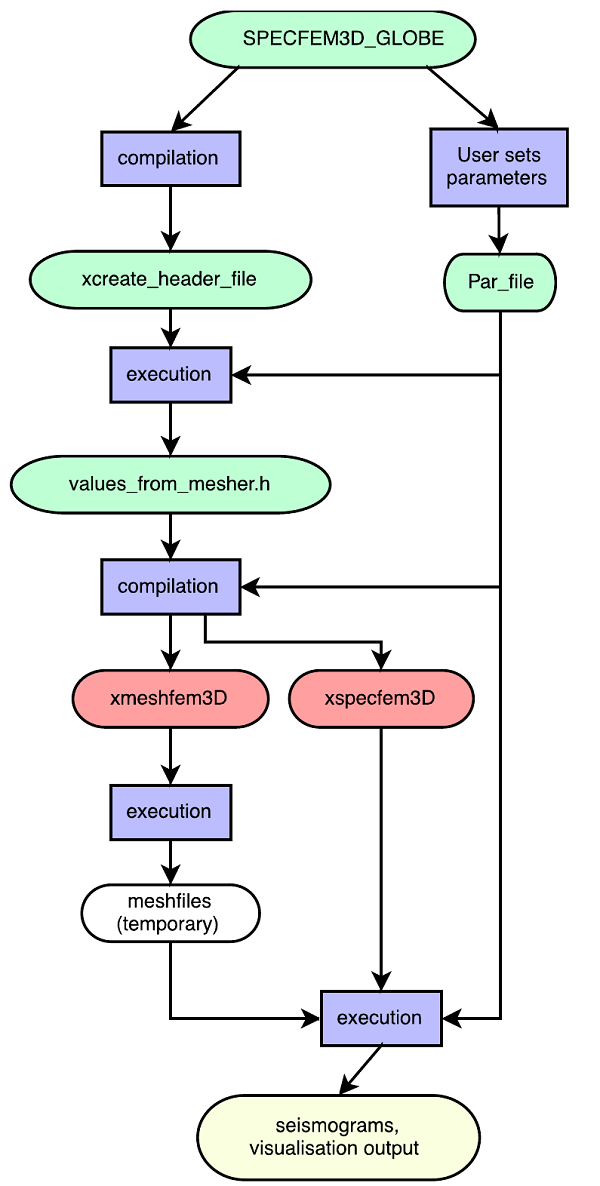
図1 : SPECFEM3D_GLOBE利用のフローチャート
1.1.2 メッシャーxmeshfem3D
このプログラムはユーザー入力を受け、オプション指定に従い、後の波動方程式を解くためのメッシュをxspecfem3Dを用いて生成します。これは各地球モデル用の一連のサブルーチンで構成され、1/6,2/6あるいは全地球に対して、動径方向のみ (1Dモデル)あるいは全方向(3Dモデル) 変化する弾性値を生成します。さらにこの弾性値は、方向に依存しない(等方性)あるいは方向依存(非等方性)的に扱うことが出来ます。
メッシャーは地震モデル、チャンク数、および境界条件等のユーザーオプションを、サブディレクトリDATAのパラメーターファイルPar_fileから読み込みます。
メッシュの例を図2に示します。ここで、AUは非等方性の強度です。モデルの他の部分では速度は等方的です。これはメッシュの2つのチャンクの内の一つの側面を示しています。要素は輪郭線で示され、表面、マントル中および外核においてメッシュが倍になっているのが見て取れます。海岸線は白線で示しています。

図2 : メッシュ例
1.1.3 ソルバーxspecfem3D
ソルバーはメッシャーが生成したメッシュを読み込みます。同じくソルバーのユーザー指定オプションを下記ファイルから読み込みます:
- DATA/Par_file:メッシュサイズ、メッシュパラメータ、診断および可視化に関するオプション
- DATA/CMTSOLUTION:地震波を生成する地震源を記述する
- DATA/STATIONS:地震波の伝播による表面ずれを記録する場所のリスト
1.1.4 コードの使用と安定性
SPECFEM3D_GLOBEのほとんどの利用者は、長波長地震現象を目的とし、最大周期fが0.01Hz以下のケースを議論しています。このような計算においては、周波数と計算の最大時間ステップに関して経験的な関連性が知られ、こうした計算は安定性を保証することが可能です。しかしながら、より短い波長の事象に興味を持つ多くのユーザーが存在し、より高い周波数でこのコードを用いたいと考えています。この場合は、経験的な安定性条件は存在しないため、高い周波数のシミュレーションの利用に制限があります。確かな性能を確保するには、コード安定性の精密な試験が必要です。こうしたことで、バグや、オーバー/アンダーフロー問題を発見することもあるでしょう。このような不安定性は、変位が無限に大きくなる、あるいはプログラムが不正に止まるなどの現象から直接判断できます。本プロジェクトを開始する前に、Andy NowackiはHECToR上で、1350コアを用いて、6時間の経過時間を使って、SPECFEM3D_GLOBEの0.05から0.1Hzのシミュレーションを実行しました。
2 プロジェクトの背景
本プロジェクトの目標は以下の項目です:
作業0:コードに慣れる(0.5人月)
864コア(6.7M要素、450Mグリッド)までのシミュレーションを、無変更の元のコードに対して実行する。
作業1:安定性解析、最適化およびベンチマーク(2人月)
高周波数計算のコード安定性を改善するためのデバッグとプロファイリングを行い、HECToRを用いた最適なコンパイラオプションを見つける。
作業2:メッシャーとソルバーをマージする(2人月)
性能上のI/Oボトルネックを削除する。現状かなり大きな(700GB以上)Fortranバイナリーメッシュファイルが生成されており、I/Oが全経過時間の8%までを占める。メッシュをMPIプロセスに振り合分けて並列に出力するように変更する。予定では50,000プロセスまでを使用する。2つの実行形式(メッシャーとソルバー)を一つにマージして、中間的なファイル入出力を不要とする。2プロセスの分離はユーザー実行時オプションで可能にする。
作業3:更新されたコードを開発ブランチへマージし、レポート提出(0.5人月)
3 実装
3.1 HECToR上での問題
3.1.1 管理ノードと計算ノード
HECToRフェーズ3において、計算および管理ノードは異なるアーキテクチャーを持ちます:計算ノードはより新しいAMD_Interlagosプロセッサーが搭載されていますが、管理ノードはIstanbul型です。この事は、xcreate_header_filesがコンパイル時に管理ノード上でコンパイルされ、デフォルトでは計算ノード用に構築されるため、ここで問題が生じます。よって、以下のどちらかにしなくてはなりません
- Crayラッパースクリプトftnを用いずに、直接コンパイラーを指定してxcreate_header_filesを構築する
- 管理ノード用にコンパイルするようにプログラミング環境を変更する
HECToR上で使うコンパイラーに依存しないので、上記2番目が適切です。Andy NowackiはこうしてMakefile内のモジュールをスワップする以下の実装を行いました:
${MODULESHOME}/init/sh # This adds directories to your PATH
module swap xtpe-interlagos xtpe-istanbul # Swap architecture
cd src/create_header_file; make # Make for head nodes
module swap xtpe-istanbul xtpe-interlagos # Swap back
xcreate_header_filesはメッシャーやソルバーの多くのソースファイルを必要とするため、新たにオブジェクトファイル用のディレクトリーを作成してリンクするようにしました。
3.1.2 Crayコンパイラー・フラグ
CrayのFortranコンパイラーへ、モジュールの.mod出力をさせるために、フラグ-emを渡しました。SPECFEM3D_GLOBEはOpenMPをデフォルトオプションとして持ちますが、XE6では目立つ性能向上は示しません。ノード内MPIが内部メモリー転送を効果的に減少させているためです。OpenMPを止めるために、オプション-h noompを指定しました。
PrgEnv-crayモジュールを用いると、CCE(Cray Compiling Environment)はシステムのmallocではなく、Googleのtcmallocライブラリーを使用します。これは、コンフィグ段階で、コンフィグスクリプトが2回それを用いてしまうため問題が生じます。コンパイラーフラグに-h system_allocを用いると、pgiとgnuがシステムmallocを用いる事になり、問題は回避されます。
3.1.3 CrayPATとScalasca
最初にCrayPATを用いてSPECFEM3D_GLOBEをプロファイリングしようとしたところ、うまく行きませんでした。メッシャーは正常に実行されましたが、pat_buildで構築したソルバーを実行しようとしたところ、繰り返しの初期の段階で止まってしまいました。ここで、Cray社のTom Edwardsが調査したところ、MPIライブラリーにおいて、タイマーコードがそのサンプリング時にアプリケーションを一時停止したときに問題が生じていましたが、トレースには影響がない様子が解りました。
APAのデフォルトのサンプリングの初期化に正規のタイマーを用いる代わりに、サンプリングのトリガーとしてハードウェアカウンター・オーバーフローを用いることが出来ます。そこで以降の環境変数には、通常と同じサンプリング周期(1,000マイクロ秒)で、トリガーとして経過時間でなくL1データキャッシュミスを用います。測定にはHWPCオーバーフローのプログラムカウンターを用いるよう変更しました。
export PAT_RT_HWPC_OVERFLOW="PAPI_L1_DCM:10000s" export PAT_RT_EXPERIMENT="samp_pc_ovfl"
これを用いれば初期のアボートを避けて、効率的に情報を得ることが可能です。これで確実にAPAファイルを得ることが可能になりました。一方、Scalascaは、最も時間の掛かるサブルーチンに関して必要な情報を得るための適切な選択肢です。
3.2 SPECFEM3D_GLOBE修正の概要
ポータビリティーのために、以下のような記述を
integer, parameter :: SIZE_REAL = 4, SIZE_DOUBLE = 8
ファイルconstants.h内では、以下のように書き換えの変更を行いました
integer, parameter :: SIZE_REAL=selected_real_kind(6) integer, parameter :: SIZE_DOUBLE=selected_real_kind(12)
また、ソース内の以下のような記述を
real(kind=4) DOUBLE PRECISION sngl(foo)
以下のように書き換えました
real(kind=SIZE_REAL) real(kind=SIZE_DOUBLE) real(foo,kind=SIZE_REAL)
SPECFEM3D_GLOBEのマージ・バージョンを、元のメッシャー/ソルバー別バージョンと後方互換性を持つようにしなくてはなりませんでした。この後にパラメーターファイルPar_fileにおいて、新しいマージ・バージョンを制御するための3つの論理パラメーターWRITE_MESH, READ_MESHおよびJUST_SOLVEを導入しました。メッシャーの単なるラッパーとしてダミードライブルーチンmeshfem3D_solo.f90を作成しました。これはメッシャーmesh_interfaces.f90のインターフェイスを持ち、切り離して用いることが出来できるためコンパイルチェック時に、また未アロケーション変数をルーチンンへ引き渡したい場合に便利です。
3.2.1 安定性解析、最適化、ベンチマーク
dCSEプロジェクトの間に、コードの安定性に影響する多くのバグがSPECFEM開発者により発見され、その修正が最新版にマージされました。そして、最初のテストとベンチマークが、CCEを用いて様々な問題サイズおよび問題タイプに関して実施されました。これらには、1あるいは2チャンクモードの局所シミュレーション[1]と、減衰を含めるか否かと共に6チャンクの全地球シミュレーション[3]が含まれます。これは約2倍のメモリーが必要となり、計算も膨大になります[1]。次に、標準的なコンフィグとメイクスクリプトを用いて、重要でないルーチンにはフラグFLAGS_CHECKを掛け、スピードが重要なルーチンにはFLAGS_NO_CHECKフラグを付けてコンパイルしました。さらに幾つかのテストでは、FLAGS_NO_CHECKを-O0へ変更して最適化を止めて、数値的な不安定性を防いで不正な実行エラー(メッセージ" the forward simulation became unstable and blew up in the solid")とならないようにしました。こうすることにより性能は劣化します。幸運にもHECToRに在る別のコンパイラーPGIは、以前は-O3レベルでフラグFLAGS_CHECKもFLAGS_NO_CHECKの場合も両方とも実行時エラーとなっていましたが、この場合は実行可能になりました。問題は1TBメッシュ、倍精度の場合は2.5TBのメッシュが生成されていることです。この問題を次のセクションで扱います。
3.2.2 メッシャーとソルバーの融合
SPECFEM3D_GLOBEは2つの実行形式から構成されます。最初にメッシャーxmeshfem3dはメッシュを生成し、その各プロセスが自身受け持つメッシュのFortranバイナリーファイルをディスクに書き出します。これを受けて、ソルバーxspecfem3dがこれらメッシュファイルを読み込み、指定された計算を実行します。これは、プログラムがメッシャーまで戻らなくとも再計算が出来るという点が利点を持ちます。これらのマージバージョンでもこの機能を残すことにします。現状のコードは静的にメモリーを確保しており、特殊な例 (例えばファイル書出し先など) を除き、パラメーター(例えば地震モデルなど)を変えるたびに、再コンパイルが必要になります。Fortran95プログラムxcreate_header_fileは、2つの実行形式(メッシャー:xmeshfem3D、ソルバー:xspecfem3D)が必要とする配列サイズをパラメーターをベースに計算し、これらのコンパイル時に必要とされるヘッダーファイルを出力します。
HECToR上ではメッシュファイルはグローバルファイルシステムLUSTREへ書出され、メッシャー、ソルバー両方でI/Oの競合を引き起こし、大きなボトルネックとなります。元のコードは、コア当たり51までのファイルを入出力します。前のセクションで記したように、このファイルは直ぐに数テラバイトの量になってしまい、大規模シミュレーションに重大な影響を与えます。
このボトルネックは、メッシャーとソルバーを一つのアプリケーションにマージ/融合することで回避できます。ここでメッシャーは、ソルバーから呼ばれる一つのサブルーチンとなり、データはI/Oではなくメモリーで渡されます。コードの融合は技術的には複雑で、2つの元々異なるアプリケーション間のメモリー管理と名前空間の統一が必要です。また、別々に実行させるという元の機能、あるいは両方実行するがI/Oも伴う機能の組込みも必要です。このために、パラメーターファイルPar_fileにおいて3つの論理パラメーターWRITE_MESH, READ_MESHおよびJUST_SOLVEを導入し、新たなドライブルーチンmeshfem3D_solo.f90を作成しました。現状は、プログラムxcreate_header_fileがvalues_from mesher.hへ書出すタイミングはコンパイル時ですが、将来はオプションにより実行時の選択が可能です。
最終的に、SPECFEM3D_GLOBEの2パーツ間の通信のためのI/Oは完全に消去され、中間ファイルのためにディスクを利用する必要はなくなり、I/Oによるペナルティーは解消されました。コード融合において直面した主要な問題は、メッシャーとソルバーの配列が同時にメモリー上に存在しなくてはならないことでした。これはコア当たりに必要なメモリーが増えることを意味するため、最終的な目標である高周波数シミュレーションでは、HECToRノードは飽和させてはならないことになります。これはコストに反映されてしまうことから、メモリー削減が課題となります。そのために、ソルバーの配列を用いるようにメッシャーを修正し、サブルーチン呼出しを分割することとしました。
例えば、元のルーチンcreate_reigions_meshは、クラストマントル、外核、内核の各領域に対して3回呼ばれます。create_reigions_mesh内ではその領域が割り当てられているメッシュが生成され、ディスクに書き込まれてデアロケーションされます。例えば配列xixstore,xiystore,xizstoreは以下のように宣言され、最後の次元をnspec actuallyとしてアロケーションされ、領域に依存して異なる値を持ちます。
real(kind=CUSTOM_REAL), dimension(:,:,:,:), allocatable :: & xixstore,xiystore,xizstore allocate(xixstore(NGLLX,NGLLY,NGLLZ,nspec_actually), & xiystore(NGLLX,NGLLY,NGLLZ,nspec_actually), & xizstore(NGLLX,NGLLY,NGLLZ,nspec_actually))
マージバージョンはI/Oを用いないで、アロケーションされた配列へ渡します(コンパイル時には静的配列、実行時には動的配列として)。以前に見た配列はソルバーからメッシャーへ、次にcreate_reigions_meshへ渡され、そこでは以下のように宣言されます
real(kind=CUSTOM_REAL), dimension(NGLLX,NGLLY,NGLLZ,nspec) :: & xixstore,xiystore,xizstore
これらは各領域に対する別の配列として分割されます。
real(kind=CUSTOM_REAL), dimension(NGLLX,NGLLY,NGLLZ,NSPEC_CRUST_MANTLE) :: & xix_crust_mantle,xiy_crust_mantle,xiz_crust_mantle real(kind=CUSTOM_REAL), dimension(NGLLX,NGLLY,NGLLZ,NSPEC_OUTER_CORE) :: & xix_outer_core,xiy_outer_core,xiz_outer_core real(kind=CUSTOM_REAL), dimension(NGLLX,NGLLY,NGLLZ,NSPEC_INNER_CORE) :: & xix_inner_core,xiy_inner_core,xiz_inner_core
これがソルバーでのこれら配列の扱い方です。この手法は配列生成およびメッシュI/Oを含む全てのルーチンで必要です。マージコードは結果が検証され、単一バイナリー形式で実行した場合に、メッシュのみ、ソルバーのみの実行、およびメッシュのディスク書込みも可能なものになりました。
4 結論
本プロジェクトの目的は、HECToR上での高周波数シミュレーションの安定的な実行を可能にするために、SPECFEM3D_GLOBEの2つの実行形式をマージすることでした。マージは達成され、SPECFEM3D_GLOBEのマージバージョンはHECToR上、あるいは他のHPCマシン上での利用が可能になりました。SPECFEM3D開発者によれば、最大周波数(f_max)は、90度チャンクの1辺に沿ったスペクトル要素数(NEX)によりf_max=NEX/(17*256)と推定されました。言い換えれば、NEX=256の場合に1/17≈0.06Hzの周波数シミュレーションが可能です。これまでで最大のシミュレーションは、NEX=960でf≈0.2Hzの場合で、以前から格段に進歩しました。最初の提案でのf=0.5Hzは極めて挑戦的な値で、NEXは2100程度が要求され、手法の精度も格段に高くなります。Andy Nowackiによれば、多くの場合観測されるのはf_max≈0.1Hzであり、本プロジェクトによりf_max≈0.2Hzが達成され、以前には成し得なかったコードの活用を可能にしました。今や多くの大規模サイズ問題がSPECFEM3D_GLOBEにより可能になっていくでしょう。
5. 謝辞
このプロジェクトは、nAG Ltd.が運営するHECToRの分散計算科学および工学(CSE)サービスの基に実行されました。英国の国立スーパーコンピューティング・サービスである、HECToR:英国リサーチ・カウンシル・ハイエンド計算サービスは、リサーチ・カウンシルを代行するEPSRCが管理しています。そのミッションは英国学術界の科学および工学の研究支援です。HECToRスーパーコンピューターは、UoE HPCx Ltd.およびnAG Ltd.のCSEサポートサービスにより管理運営されています。文献
| [1] | http://www.geodynamics.org/wsvn/cig/seismo/3D/SPECFEM3D_GLOBE/ trunk/doc/USER_MANUAL/manual_SPECFEM3D_GLOBE.pdf |
| [2] | Komatitsch, D, Tsuboi, S, Tromp, J The spectral-element method in seismology. in Seismic Earth (eds A. Levander and G. Nolet), American Geophysical Union, Washington, D. C..(2005) |
| [3] | D. Komatitsch and J. Tromp, Introduction to the spectral-element method for 3-D seismic wave propagation (1999) gji 139 806-822. |