
Mark Richardson,
Numerical Algorithms Group Ltd.
September 2009
概要
GLOMAP Mode MPIとそのホストソフトウェアである化学輸送モデルTOMCATに対して、dCSEサポートにより解析され、英国国立スーパーコンピューティング・リソース、HECToRのCray XT4h(hはハイブリッドの事で、Cray X2を指します)システム上での性能を改善する実装が行われました。これまでこのコードはXT4上の小さなコア数(32コア)を用いて利用されていました。この構成において、コンパイラオプションを-O3から-fastへ変更したところ、3.3%の小さな性能改善が生じました。さらにコードに対して、化学計算セクションの固定緯度平面上の計算を改良することで、より大きな16.2%の改善を達成しました。通信機能周りの改良では9.4%の改善を示しました。時間ステップ当りの実行時間は、3種のチューニング作業結果の総和として、従来のバージョンに比べて12.4%改善しました。
この改善により、より経済的に、より多くのコアの利用が可能になり、シミュレーションで64コアを使用した場合、ステップ時間は合計で16.5%削減されました。
本作業の結果は、HECToRリソースのより大規模かつ、より効率的な活用を可能にします。
目次
1 イントロダクション
1.1 背景
1.2 プロジェクト目標
1.3 実行の概要
1.4 コード生成
1.5 実行形式のビルド
1.6 データファイルのコピー
1.7 ジョブ投入
1.8 ジョブの終了
1.9 シミュレーション実行時の推奨事項
1.10 本プロジェクト内の変更点
2 Cray X2での変更点
2.1 Cray X2の概要
2.2 Cray X2での作業
2.3 Cray X2での基本的な性能
2.4 作業のまとめ
3 Task1:コンパイラによる性能の比較検証
3.1 コンパイラオプション
3.2 コンパイラオプションの調査
3.3 コンパイラオプションの結果比較
3.4 Task1の結論
4 Task2.1:一般的なコード最適化
4.1 性能解析ツール
4.2 サンプリング測定レポート
4.3 トレース測定
4.4 コード構造修正の結果
4.5 Task2.1の結論
5 Task2.2:並列演算の最適化
5.1 現状の並列実装
5.2 ソースコードレビュー概要
5.3 通信セクションの変更の結果
6 Task2.3:ファイルの入出力改善のため並列ファイル操作
6.1 概要
6.2 既存バージョンにおけるケーススタディー内のファイルアクセス解析
6.3 ファイルアクセス性能改善のための推奨
6.4 ファイルデータ構造の実装
7 全体の要約
8 全体の結果
9 今後の作業計画
10 将来的な方向性について
1 イントロダクション
1.1 背景
本レポートは、エアロゾル・シミュレーションコードGLOMAP(Global Modelling of Aerosol Processes)の概要とその性能解析について記述します。その性能向上が見込まれる変更が提案されました。それらの内の幾つかの実装に関する性能改善結果をここに報告します。本レポートは、HECToR XT4hにおけるGLOMAP Mode MPIの性能解析と、提案内容、実装およびその性能結果について詳細に記述します。
本プロジェクトは、リーズ大学・地球環境学部のGraham Mann博士が開始しました。彼はNCASの創設研究者です。National Centre for Atmospheric Science(NCAS)は、大気科学研究における、研究プログラムと英国全体の設備サポートを提供しています。
本プロジェクトの基盤であるdCSEサポートは、英国研究評議会(UK Research Councils)により提供されます。それは、英国のNational High Performance Computing Facilities(HECToR)により、研究者に対して計算プログラムの性能と研究作業の改善に役立てられています。これを行うのは、具体的には、より良いソフトウェアエンジニアリングとこれらの施設の利用者の教育を通じて、英国の計算リソースの利用性を向上させるサポート作業を行うように特定された人物です。
ニューメリカルアルゴリズムズグループ(nAG)は、数学的な数値計算手法の計算ライブラリー分野に特化した非営利団体であり、Fortranコンパイラの開発も行っています。nAGは、HECToR設備をサポートし、ユーザーがアプリケーションの実行で問題が生じた場合にその支援をします。更に、研究会議への提案の中での計算的側面の評価や、dCSE担当者の支援も行います。
HECToRは、テラスケールのハイエンド計算リソースです。これは、5664個のAMD64 Opteron CPU(dual core)のCray XT4hシステムと、112個のCray X2プロセッサー(より詳細にはwww.hector.ac.ukをご覧ください)で構成されています。本システムで重要な点は12のサービスノードがあることです。それは8つのログインノード、2つのaprunジョブランチャー共有ノード、および2つのシリアルバッチ実行共有ノードから成ります。ジョブスケジューラーはPBS Pro 8.1.4で、8192個までのCPUを割当てる数種のキューを持ち、ジョブ実行の最大時間は12時間です。デフォルトコンパイラはPGIで、デフォルトのターゲットはOpteronプロセッサーのXTです。OS環境の設定と変更には「モジュール」システムを用います。このシステムは最近になって、デュアルコアからクアッドコア(Barcelona-64)へ変更されました。ログインノードとサービスノードはデュアルコアのまま残っています。本レポート内では用語「プロセッサー」をマルチコア構成品として用います。「CPU」はプロセッサー上のコアを指します。PEはprocessing elementの略で、コアおよびCPUと同義です。X2アーキテクチャーでは、プロセッサー当たり1CPUであり、PEと言った方が好ましいです。
GLOMAP Mode MPIは、全地球のエアロゾル・プロセスをシミュレートするFORTRANプログラムです。これは、ガスフェーズ化学/体積と、地球環境の微量ガス、エアロゾル種の移流を積分するアルゴリズムを持つ化学輸送モデルTOMCAT、および核化、凝固、凝縮、雲生成といったプロセスをシミュレートするサイズ分解エアロゾルの微視的物理モジュールであるGLOMAPの主要部を組み合わせたものです。
シミュレーションは地球の中層大気(10hPaまで)以下を対象に、本プロジェクト用のデータセットは、31の鉛直レベル解像度(ハイブリッドσ-p座標で)と、T42スペクトル(2.8x2.80緯度/経度)の水平解像度という"中程度の"解像度を持ちます。大気を形成する流体体積は、3次元カルテシアン矩形ブロックの計算空間へマッピングされます。各方向のセル数は以下の通りです:
- 緯度:128(コードではIループ)
- 経度:64(コードではKループ)
- 水平方向レイヤー:31(コードではLループ)
GLOMAPは、輸送と湿性除去を駆動するのに"offline meteorology"を用い、他の気象数値シミュレーションソフトウェア(6時間毎のECMWF解析)が生成したデータを読み込みます。GLOMAPにはModeとBinという2つのバージョンが有り、それぞれエアロゾルのmodalおよびsectionalなアプローチを取ります。それぞれにOpenMPバージョンが有りますが、本研究の対象はGLOMAP Mode MPIです。OpenMPバージョンはSMPマシン(例えば以前の国立HPCシステムのCSARとHPCx)で稼働していますが、スレッドの最大数は最外側ループ(緯度)により制限されています。このテストケースでは64です。GLOMAPのMPIバージョンは最近になって開発されたものであり、OpenMPバージョンとの違いは主にTOMCATのセクションで、MPIは並列タスク間通信に用いられています。通信は、決まった命名規則を用いたTOMCAT本体とは異なる別のサブルーチンセットで制御されています。例えば、サブルーチンMPI_SENDRECVは、MPE_SENDRECVにラップされます。インターフェイスは、MPE_*ルーチンへはより少ないパラメーターが渡されることが異なる点です。通常は、ラッパーではMPI_COMM_WORLDがコミュニケーターであるとされて、それ以外のコミュニケーターのパラメーターは省かれています。MPE_*ルーチンは皆、インジケータがパラメータとして指定されていても、通信されるデータオブジェクトのクラスを決定するためにMPE_TYPEの呼出しをしなくてはなりません。
基盤となる化学輸送プロセスはTOMCATにサポートされており、GLOMAPは、初期化やエアロゾル化学ステージと言ったコードの特定の場所へ挿入されます。GLOMAPのプロセス全ては、個々の計算セル(grid-box)上で行われるため、並列通信の影響は小さいですが、必要メモリーへの影響が有ります。現状の典型的なHECToRでのジョブは32MPIタスクを用い、1年の大気プロセス計算に12時間が掛かります。通常のシミュレーションは(年間のエアロゾルのライフサイクルの議論を可能にするために)1か月のジョブに分割され、PBSスケジューラーでそれらを続けて実行させます。
ジオメトリー分割は、各計算ノードへ仕事を割り振るのに用いられ、各タスク間ではMPI通信を使用します。分割線は緯度と経度の線上にあり、きっかりの度数間隔を持ちません(この場合は2.8125°です)。
領域分割自由度は事前にGLOMAPに決められており、体積に対する表面積の比を小さくするために分割された矩形が正方形になるように行われます。これは計算に対する通信の比を最小にすることと同じです。しかしながら、これがこのソフトウェアが適用されるケースタイプに最良であるとは限りません。ループ長やハードウェア構成も考慮すべきです。
MPI計算の際には、ジオメトリーは緯度線と経度線に沿ったより小さなブロック(パッチ)に分割されます。各ブロックは、地表から最大高度までの大気の層を持ち、このケースではこれは31層です。分割はシミュレーションを基礎に事前に設定されます。
| Number of MPI Tasks |
NPROCI | NLONMX | NPROCK | NLATMX | Remarks |
| 2 | 2 | 64 | 1 | 64 | Too coarse |
| 4 | 4 | 32 | 1 | 64 | Too coarse |
| 8 | 4 | 32 | 2 | 32 | |
| 16 | 4 | 32 | 4 | 16 | |
| 32 | 4 | 32 | 8 | 8 | |
| 64 | 4 | 32 | 16 | 4 | |
| 128 | 4 | 32 | 32 | 2 | Current maximum |
| 256 | 16 | 8 | 16 | 4 | |
| 512 | 32 | 4 | 16 | 4 | Minimum number of points in (I,K) |
表1は、T42に対する事前設定の領域分割を示しています。128PEを超えて用いる事も考えられますが、それは効率的でなく、通信に対する計算の割合が減少してしまいます。より小さな分割にはより大きな配列が必要になり、メモリー制限のためにテストが実行できませんでした。この領域分割では、サブ領域の最大数は128で、経度方向のタスク当たりの計算セルの最小数は2で、緯度方向のタスク当たりの計算セルの最小数は、座標の極、即ち最小K値と最大K値の平面内で満足する条件により設定されます。FFTでの領域分割に似たジオメトリーの領域分割を行えば、変換前の通信オーバーヘッドは削減されるでしょう。
1.2 プロジェクト目標
本作業は6人月と予定され、以下の4項目が目標となります:
作業1では、HECToR上でのMPI版GLOMAPとMPI版TOMCATの性能とスケーラビリティーを検証します(1人月)。
ここで、MPI版GLOMAPとホストであるMPI版TOMCATのHECToR上の性能を、コンパイラオプションを変えてより詳細に、標準的なスカラーMPPマシンのXT4システムと2008年8月に導入された新しいベクトルコンポーネント"black widow"の両方を用いて検証します。ベクトルとスカラーシステムの両方でGLOMAPの性能が十分であることを確認することが重要になります。なぜなら、このコードは、Met Office Unified ModelのUKCAサブモデルの一部として、Met OfficeのNECのベクトルスーパーコンピューターSX-6とSX-8でも稼働しているためです。
GLOMAPにおいて高コストなルーチンを特定して、次の作業での最適化対象候補とします。その後、CPU数に対するスケーラビリティーテストを、中規模解像度において実施します。
以上により、最初の作業では、経過時間の生データと並列スケーリングデータによりGLOMAP Mode MPIを解析し、性能向上のための方針を提供します。
第二の作業は3つの作業を含みます。この作業はMPI版GLOMAPの最適化とアルゴリズム改良です(5人月)。
MPI版GLOMAPのプロファイリングにより、エアロゾル/化学インターフェイス"CHIMIE"ルーチンと粒子凝固ルーチンが、スカラーMPPのXT4システム上で最も高コストであることが示唆されています。"CHIMIE"ルーチンは主に配列コピー(および少量の計算)に用いられており、そのオーバーヘッドから、(スカラー)HECToR上では性能劣化することが示唆されます。粒子凝固ルーチンもまた、高コストなため、性能改善の作業が必要です。その他の幾つかのルーチンも目立っており、関数インライン展開や、近似計算をルックアップテーブルへ置き換えたり、最新のアルゴリズムを用いるライブラリー(FFT)呼出しへの置き換えることにより、更に性能改善が期待できます。これらと共に一般的なコード最適化の適用を行うことが最初の作業(M2.1)です。次の作業はHECToRのスカラーおよびCray X2ベクトルシステムのアーキテクチャー特性を生かす最適化作業です(M2.2)。ここでは、キャッシュ有効活用と通信オーバーヘッド削減が重要になります。第三の作業(M2.3)は、TOMCATとGLOMAPへパラレルI/O利用を調べることで、更にパフォーマンスを強化していきます。作業(M2.1)と(M2.2)を行えば、CPUを多く使用する場合に、I/Oのオーバーヘッドは目立たなくなると期待できます。
以上により、第二の目標(M2.1)は、一般的なコード最適化で、第三の目標(M2.2)は、(Cray X2およびAMD64 Opteronの両方に対する)アーキテクチャーに焦点を当てた最適化です。キャッシュ効率化については、MPI通信効率に焦点を当てることとします。第四の目標(M2.3)は、ファイル操作を解析して、マスターI/Oモデルのボトルネックを回避するための並列I/Oの見通しを立てることです。
1.3 実行の概要
GLOMAPのシミュレーションは2つのファイルから開始されます:問題を特定する入力ファイルと、ビルド・コンパイル・実行(PBSテンプレートスクリプトを含む)のLinuxスクリプトファイルとしての"サブファイル"です。このサブファイルは、PBSコマンドと並列関連機能(例えばaprun)を消去あるいは利用不可にして、テスト用にコマンドラインから実行可能です。また、付属のperlスクリプトは、個別のサブファイル全てに対する一連のJOB投入に用いry、一連のPBSスクリプト(例えば、年間の各月毎のサブファイルへ分割する)生成に利用できます。これはチェックポイントファイルを生成し、キューの時間制限12時間以上の実験が可能です。最初に、コード生成と、実行形式のビルド、ファイルコピーおよび並列実行から成るPBSスクリプトを準備しました。更にもう一つのPBSスクリプトは、リスタートとユニークな識別子を持つ結果の保存を行うものです。
1.4 コード生成
サブファイル・スクリプト内の"here documents"と"echo"を用いると、"update"ファイル(.up)を生成できます。"nupdate"プログラムは、TOMCATサブルーチンの参照バージョンを修正する編集命令から成る.upファイルを実行するために用いられます。最終的にnupdateシステムによりprog.fファイルが生成され、参照ディレクトリーからコピーされ連結された補助的なソースコードを通したGLOMAPコードが含まれます。
1.5 実行形式のビルド
ジョブスクリプト内の"ftn"文は、FORTRANソースコードのコンパイルと実行形式のビルドを制御します。この時のオプションは、-O3, -Mextend, -Mbyteswapio, -r8, -i4、です。これらはHECToRのデフォルトコンパイラPGIのものです。最適化レベルは" chained.functions"スクリプトで設定され、シェル変数$COMPILER_SETTINGSに保存されます。これは用心深い最適化レベルです。コンパイルにより、GLOMAP.exeとpdgc.exeという2つの実行形式がビルドされます。
1.6 データファイルのコピー
スクリプトは、GLOMAP.exeが生成されたことを確認し、もし成功していれば、HECToRのLUSTREファイルシステムを用いている場合、必要に応じて多くの関連するファイルをローカルディレクトリーへコピーします。他の参照ディレクトリーへのシンボリックリンクが生成され、シミュレーションのステージに応じた他の参照データへアクセス可能にします。
1.7 ジョブ投入
リスタートの場合、スクリプトはファイルfort.30をローカルディレクトリーへコピーした後、aprunコマンドが並列実行起動のため発行されます。Aprunオプションは、入力ファイル内容に基づいてperlスクリプトで処理されます。例えば、64CPUを用いる場合は、(デュアルコアの場合)以下のようにします:
aprun -n 64 -N 2 ./GLOMAP.exe
クアッドコアの場合は"-N 4"とします。その他のファイル、fort.93,fort.94,fort.95は入力ファイル内の値から生成されます。.upファイル内の幾つかのコードは、スクリプト処理中に"here"ドキュメントに必要な修正がなされます。
1.8 ジョブ終了
並列ジョブの終了後にスタンドアローンプログラムpdgc.exeが実行され、結果を倍精度から単精度へ変換し、新しく生成されたfort.9を再度、fort.25へ変更します。この処理でファイルサイズは元のfort.9に比べ半分になります。Fort.25はリネームされ、スクリプトの最後へ移されます。研究者らはこれらの出力結果をリーズ大学に持ち帰り、彼ら自身のIDLで処理/解析されます。このpdgc.exeはシリアルコードであり、計算ノードが空いているが既に予約されている場合はキュー管理ノードで実行されます。これは他のジョブの邪魔をしています。
1.9 シミュレーション実行時の推奨事項
扱い難いジョブ投入ファイルを5つのステージ:ビルド、コピー、並列実行、リダクション、結果の転送、に分けることが推奨されます。Nupdateツールは個別に適用されるべきであり、ユーザーは自身の.upファイルあるいはその修正版あるいは標準版のカタログを維持することが可能です。これは、軽いシーケンシャル処理として、ログインノード上で対話的に実行されるのが望ましいです。実行形式のビルドはメイクファイルで可能で、ログインノード上でも可能ですが、シリアルジョブ投入によっても可能です。転送のための結果の変換はシリアルジョブで行うべきですが、並列IOを用いることが出来るならジョブ実行の一部としても可能です。こうすればfort.9の生成は速くなり、fort.25ファイルへの直接の単精度変換を行うことが出来ます。
1.10 変更点
これら変更点については適用はしましたが、リーズ大学での実用には至っていません。採用基準を満たすための条件の満足と、新しい研究者がすぐに仕事が出来るようにするためには、更に作業が必要です。
ケースディレクトリーの作成を行いましたが、ソースコードは未だ単一ジョブ投入スクリプトの一部となっています。しかしながらスクリプトは、リスタートファイルがケースディレクトリーへコピーされた後に起動されますが、これはGLOMAP.exeが生成された場合に限り行われます。ソースはこの時、要求されたPE数に相当する名前のディレクトリーへ分割され、汎用メイクファイルのコピーを添えられます。ビルドは、CPU数に関わらず単純にコマンド"make -f make.pgf90 xtgmm"の発行で行います。NFSとLUSTREファイルシステムの特性から、HECToRではソースは$HOME内に、テストケースは$WORK内に置くことが推奨されています。これらはPBSバッチファイルとaprunコマンドで用いられる仕組みです。
Prog.fに対して様々な試験を行いましたが、いずれもジョブ投入ファイルのnupdate命令に組み込まれました。最終的にオリジナルの参照ライブラリーを作成し、より簡単なコード生成が可能なように複数のやり方を用意しました。
2 Cray X2での変更点
2.1 Cray X2の概要
Cray X2は、Cray XT4へ装着するハードウェアで、名称XT4hはハイブリッドマシンであることを表します。しかしながらこれは真のハイブリッドでなく、X2はXT4と独立に利用されるものです。これらは、ログインノードをホストにした共通のOSとファイルシステムを持ちます。計算ノードはCray Node Linuxのバリエーションを持ちます。プロセッサーは、単一命令を複数データへ同時に実行することが可能な、大きなベクトルレジスターを持ちます。例えば複数搭載された128ワードレジスターです。もし128要素の配列Aが一つのレジスターへロードされ、128要素の配列Bが別のレジスターへロードされ、スカラーCがスカラーレジスターへロードされた場合、D=AxB+C計算は、スカラープロセッサーでの768ステップでなく、6ステップで実行されます。
コンパイラCFTN 6.0.0.1はログインノードにホストされ、コマンドラインで対話的にクロスコンパイルが可能です。コンパイラコマンドftn利用には、環境設定"module load x2-env"が必要です。異なるオプションセットが必要な場合は、異なるメイクファイルをつくります。こうすれば、全ジョブスクリプトの再実行をせずに実行形式のリビルドが可能です。
2.2 Cray X2での作業
スクリプトはaprunコマンドの発効前に一旦停止します。この時、ソースコードが生成され、PGIコンパイラによりGLOMAP実行形式がビルドされます。ソースコードは、X2のメイクファイル(make.cftn)により繰返しビルドしなければならず、また性能分析ツールに用いるために、ケースディレクトリーから別のディレクトリーへ移動させられます。GLOMAP研究者グループが通常行う操作では、シミュレーションの度に全スクリプトを実行していますが、こうすると最初のPBSスクリプトの実行毎にソースが消去されてしまいます。本作業においては、並列実行用の別のPBSスクリプトを作成しました。これはログインノードのコマンドラインから起動しますが、自動ジョブ制御のサブステップとして埋め込まれます。
2.3 Cray X2での基本的な性能
コード変更は、主に移植目的の修正がほとんどでした。移植には、ハードウェアの違いだけでなく、コンパイラの違いやFORTRAN標準への適応による修正も含まれます。Crayコンパイラ(CFTN 6.0.0.1)はPGIよりも厳格で、ビルド中にコーディングに関する問題を指摘します。また、実行時のメモリーフォルトにおいて異なるメモリー制御もします。CFTNコンパイラは他のコンパイラに比べメッセージが詳細でないため、問題のありそうな領域を特定するために、nAG FORTRANコンパイラをコンパイル段階で用いました。これはHECToRで利用可能です(F95 v5.1 for Linux 64bit)。ビルド時にTOMCATでコーディングエラーを発見したため、修正しました。修正内容については全てリーズ大学と連絡を取り合いました。また、CrayPATの利用に問題はありませんでした。
表2は、X2システム上のGLOMAP-MODE-MPI v1_gm2の実行時間情報を示しています。図1は、これらをXT4のものと比較した図です。ここで、XT4の実行時間は、X2と同じコードを用いた、クアッドコアシステムの値です。そこでは-fastフラグでコンパイルし、ノード当たり2コアを用いた2ノードで計算しました。
す。そこでは-fastフラグでコンパイルし、ノード当たり2コアを用いた2ノードで計算しました。| GLOMAP Mode v2 on Cray X2 (base code) time in seconds | |||
| Number of MPI tasks | 8 | 16 | 32 |
| Initialisation time | 95 | 92 | 93 |
| End step 143 | 1074 | 477 | 260 |
| End step 144 | 1099 | 500 | 283 |
| End of simulation | 1131 | 534 | 321 |
| Average time per step | 6.89 | 2.71 | 1.17 |
| Equivalent XT4 timing on two cores per QC node | 12.57 | 5.25 | 2.61 |
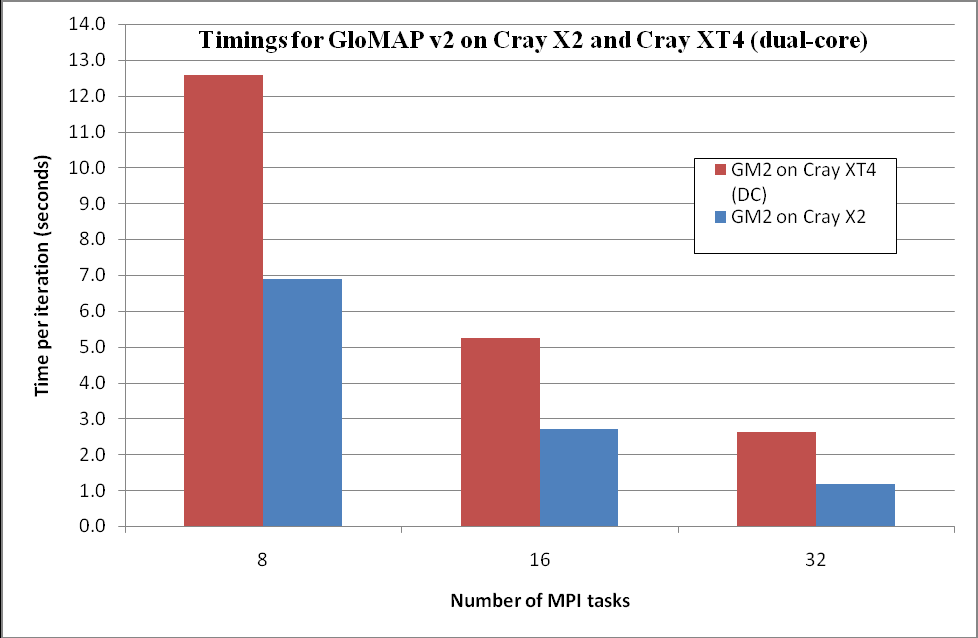
図1:X2とXT4でのGM2の実行時間
これは、通常このカテゴリのアプリケーションで予想される非理想的な挙動とな異なり、ステップ当りの実行時間が2倍以上に改善するという「スーパースカラ」挙動を示しています。より多数のPEを用いれば、その担当領域が小さくなるので、より良好なメモリー/キャッシュ効率を導くことが予想されます。X2はコア当たり8GBメモリーを持ち、XT4は2GBですが、ノード当たり2MPIタスクしかないのでMPIタスク当たりは4GBです。最内側ロープ長は32で(1からNLONMX)、緯度ループ長は1/2になっています(表1に在る通り、8,16,32PEに対してNLATMXは各々32,16,8となります)。
以降は、様々な理由からX2での作業を停止して、XT4での作業を優先しました。
2.4 Cray X2の作業結果
一般的に言えば、ノード当たりの性能に関してCray X2はCray XT4よりも遥かに高速です。その性能は25.6Gflopsであり、XT4コアは5.5Gflopsしかなく、最新のアップグレードでも9.2Gflopsです。しかしながら、これらは理想的なLINPACKベンチマークの観点のものです。種々の要因により本調査は中断しました。一方XT4システムでのコードレビューにより、インライン展開やキャッシュブロッキングオプションについて更に調査を進める事となり、これらが性能を改善することが期待されました。
3 コンパイラによる性能の比較検証
3.1 コンパイラオプション
このプログラムの内部では、大気プロセスをシミュレートする手法が高レベル言語で記述され、数学的手法の良い表現となっています。しかしながらこれは常にその計算プラットフォームに適しているとは言えません。性能向上に向けたコードの構造レビューをタスク2.1で議論しました。その他の性能向上には、高レベル言語を解析し、特定のハードウェアにチューニングされた効率的な機械語へ翻訳するコンパイラの利用が有ります。
GLOMAPコードは、-O3オプションでコンパイルされていますが、これは開発者にとって簡単で、かつ、デフォルトオプション-O2よりもそれなりに優れた性能を示したためです。より詳細な情報を得るには、オプション"-Mneginfo"および"-Minfo"が便利です。ビルド時のメッセージ抜粋を以下に示します。
pgf95 -Mneginfo -Minfo -fast -o xtgmm.exe prog.f produces this: 102046, Memory copy idiom, loop replaced by call to __c_mcopy8 102054, Loop not vectorized/parallelized: contains call 102058, Generated an alternate loop for the inner loop Generated vector sse code for inner loop Generated 1 prefetch instructions for this loop Generated vector sse code for inner loop Generated 1 prefetch instructions for this loop
GLOMAPでは、ビルド時のログファイルから、最適化が不可能になる場所が多く示されます。これら全ての調査は行いませんでしたが、修正を行って最適化を進めました。
3.2 コンパイラオプションの調査
コンパイルオプションの効果はコードの構造により変わります。例えば、プリント分や条件文がループ内に在れば、ベクトル化は失敗します。現状のコードは、最適化レベル-O3を用いたPGIコンパイラを用いています。-fastオプションは、AMD64チップをターゲットとしたPGIコンパイラの様々な機能を起動し、性能改善が期待できます。これらの機能には、ベクトル化、インライン展開、ループ・アンローリングが含まれます。
-fast : Common optimizations; includes -O2 -Munroll=c:1 -Mnoframe -Mlre -Mautoin
line -Mvect=sse -Mscalarsse -Mcache_align -Mflushz
残念ながら-O3と-fastの組合せは、後に説明するように不正な結果を与えました。
オプション-Minlineはコンパイラーに対して、頻繁に呼び出されるサブプログラムを与えられたファイルから解析し、それらを呼出し地点に挿入したアセンブラコードを生成することを指示します。これは実行形式サイズの増加を招きますが、実行時間を削減します。
上記に加えて以下のオプションが望ましいです:
-Mipa=inline -Mipa=reshape
多くのコードは、内部手続き解析として知られる機能を用いて最適化可能です。これは、PGIコンパイラでは-Mipa=オプションで利用できます。サブプログラムのコンパイル時に、コンパイラはインライン展開可能なセクションを特定します。単純なラッパー関数が多く存在しており、これらはコンパイラーにより取り除くことが出来ます。リンク時には、オブジェクトファイルは更新されて新しい情報でコンパイルされます。こうしてより効率的な実行形式が与えられます。サブルーチンの入り口の多くの箇所で、2次元配列を1次元配列へ変換するといった、配列の形の変形が存在するため、オプションreshapeも適用しました。
しかしながら、GLOMAPへインライン展開を適用すると2つの影響が有ります:一つは、advanced IPA inliningがエラーとなることで、もう一つは-fastと-O3の組合せが結果不正になることです。よって-fastのみを残したところ、それでもベクトル化とより安全なインライン展開により性能は向上しました。これについてはバグフィックスを待って時間計測をすることとしました。
ソースコードはモノリシックファイル(および複数のGLOMAPが指定するファイル)として生成されます。これは単純なシングルレベルのインライン展開機能を持つコンパイラにとっては好都合です。全ての関数は同じソースファイルに在る場合は、コンパイラはインライン展開対象をより容易に特定できます。これは自動最適化に有利ですが、幾つかの最適化が特定のサブルーチンに有害になる可能性があるため、個別のサブルーチンへコンパイルオプションを適用する方法が可能です。よってIPA機能が正しく動作すれば便利でした。GLOMAPへこれを適用しなかったもう一つの理由は、研究者の仕事をシンプルにする既存の作業慣行から大きく外れることになることでした。
3.3 コンパイラオプションの結果比較
プロジェクト期間中に、ソースコードバージョンはGM2,GM3,GM4へ更新され、それぞれについてコンパイラ最適化レベルをテストしました。表3は、デュアルコアシステムにおいて様々なコンパイラ最適化オプションによる実行時間を示しています。
| Optimisation level | -O3 | -fast | -fast -O3* | -Minline -fast -O3 |
| Version GM3 (DC) | 390.34 | - | 369.09 | 385.81 |
| Version GM4 (DC) | 349.64 | 332.91 | 327.93 | 372.55 |
| Percentage change from "-O3 only" | 0 | -4.78% | -6.21% | +6.55% |
*:結果不正
この初期のテストでは、全経過時間に注目していましたが、残りの解析では、これを初期ステップと、143ステップ目、144ステップ目、およびシミュレーション終了までの時間を測定しました。ステップ当りの時間は、通常利用におけるより代表的な性能です。これを表4,5に示します。ここで、テストは更新されたクアッドコアシステムで計測され、-O3オプションを用いた場合、クアッドコアがどの程度既存の作業に影響を与えるかを検討できます。
| NCPU | 8 | 16 | 32 | 64 |
| Tinit | 98 | 51 | 148 | 168 |
| T143 | 1583 | 834 | 597 | 502 |
| T144 | 1597 | 845 | 608 | 538 |
| Ttotal | 1605 | 855 | 621 | 563 |
| Ttot-T143 | 22 | 21 | 24 | 61 |
| T143-Tini | 1485 | 783 | 449 | 334 |
| (T143-Tinit)/142 | 10.45 | 5.51 | 3.16 | 2.35 |
| Speed-up | 1.00 | 1.89 | 3.31 | 4.44 |
| NCPU | 8 | 16 | 32 | 64 |
| Tinit | 116 | 56 | 63 | 108 |
| T143 | 1503 | 798 | 497 | 410 |
| T144 | 1527 | 807 | 507 | 423 |
| Ttotal | 1534 | 817 | 519 | 445 |
| Ttot-T143 | 31 | 19 | 22 | 35 |
| T143-Tini | 1387 | 742 | 434 | 302 |
| (T143-Tinit)/142 | 9.77 | 5.23 | 3.06 | 2.13 |
| speed up | 1.00 | 1.86 | 3.19 | 4.59 |
| Change in time per step over "-O3 only" | -6.51% | -5.08% | -3.16% | -9.36% |
"module load xtpe-quadcore"(現在はxtpe-barcelona)により、隠れたオプション"-tp=barcelona-64"も効いています。ビルドをジョブスクリプトで行う際には、スクリプト内に同様のモジュールコマンドも必要です。同じソースコードを、最適化レベル-fastとxtpe-quadcoreモジュールを用いて、単一makefile(付録A)で単一の実行形式へコンパイル可能です。
これら値は、複数回の実行結果から選んだ最速値で、ステップ毎の時間を図3で示しました。これら一連のテストは、直接PBSスクリプトを繋げて行いました。複数回のテストで、初期ステップ実行時間が遅くなったり、また-fastが-O3 の場合に比べて遅いというケースが有りました。
検証のためにfort.25ファイルを参照ファイルと比較しました。図2は結果不正の例で、"perturbed"と"control"データ間で大きな差があります。ここには領域境界の水平線の形状に明らかなアーチファクトが有ります。この16PE分割結果を4PE分割の参照データと比較したところ、特定のサブルーチン内で配列次元に間違いが見つかりました。バグを修正版は一様な白色で、結果に差がないことを示します。
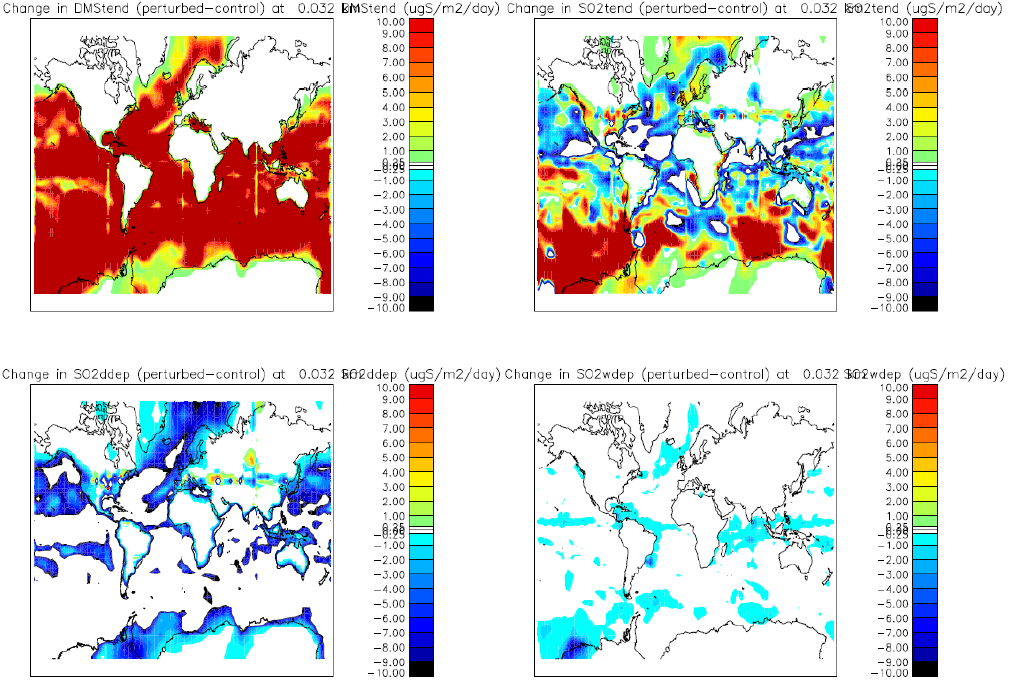
図2:Cray X2のGM2の実行結果の比較:controlは4PE分割、perturbedは16PE分割を示す。
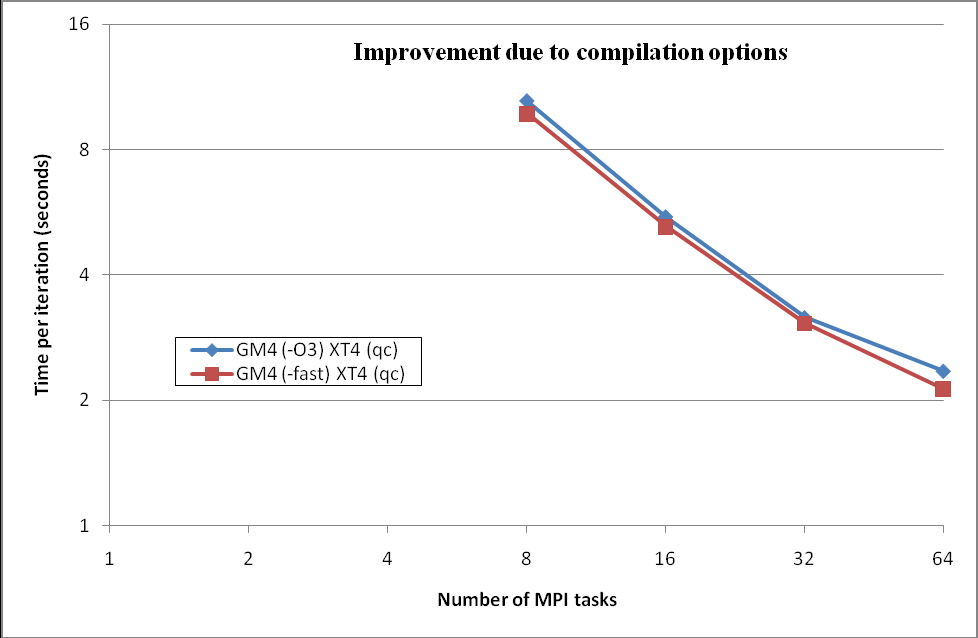
図3:Cray X4のクアッドコアノード上での、PGIコンパイラのオプション2種のGM2の比較
良好な性能を示す32PEから64PEへの性能劣化の原因は複雑です。表1に示すNLONMXとNLATMXの値は、この領域分割が緯度ループのみを減少させることを示しています。これはKループと関係のない部分が、シミュレーションの主要部になりつつあることを示唆しています。化学ステップで扱うデータは、(32x31)グリッドボックスの平面であり、ほぼ200種の評価対象が有り、負荷が大きな部分です。ですが、領域分割に無関係に常に同じサイズです。
3.4 Task1の結論
現在は、-O3より性能が改善する-fastオプションが用いられています。コンパイラオプションの変更により実行時間は改善しますが、スケーラビリティ改善には小さな影響しか与えません。このことは図3で示されていますが、詳細は全結果のまとめ図13をご覧ください。この最適化は並列通信パターンに影響しません。これについては後の作業でレビューします。
異なる最適化を指定したか否かに関わらず、結果は注意深く検証すべきです。基本となる参照ケースは-O0(最適化無し)オプションで作成します。シミュレーションは長時間かかることになりますが、その結果は比較のベースとなります。
4 Task2.1:一般的なコード最適化
4.1 性能解析ツール
Crayは、オブジェクトコードにシステムコールを挿入して、実験タイプ別の実行形式を作成する性能解析ツールを提供しています。GLOMAPを5つに分割すれば、CrayPATツールで実行形式を繰返しビルドするのに便利です。このコードを一度通常のやり方でビルドしてテストします。次にCrayPATアプリケーションを起動するために環境変数を変更し、新しい環境下で再度ビルドします。実行形式の再ビルド方法により、異なる実験を行うことが出来ます。コード性能の解析は主に、サンプリングとトレースという2種の測定があります。サンプリング測定は、コードを通常間隔(100ミリ秒)で実行し、ルーチンの実行がそのサンプリングポイントで記録されます。トレース測定は、特定の関数に焦点を当てて、その関数の実行時間量を記録します。実行中には、追加の測定ファイル(name.xf)が出力されます。測定ファイルを追って処理すると、標準出力にテキスト形式のレポートが出力され、プログラム性能に関する情報を含む幾つかの追加ファイルも出力されます。
リーズ大学の研究者らによる初期のサンプリング測定によれば、シミュレーション時間に多くを占めるサブルーチンが明らかになっていました。CrayPAT解析は以下に述べるようにこれを再現しました。
4.2 サンプリング測定レポート
基本的なサンプリング測定から、ADVY2,ADVX2,ADVZ2,CONSOMの4つのサブルーチンが期待通りに多くの実行時間を占めていました。TOMCATにおいても、初期の解析からこうした特性が明らかにされていました。しかしながらここでは、CHEMIEとUKCAサブルーチン群という、予期せぬ高負荷で、特にCPUカウントの低いルーチンが明らかになりました。これらは図4のUSERセクションに見ることが出来ます。これらの内2つをさらに詳しく調査し、修正を施します。
GM3バージョンの32PEを用いた場合のCrayPATサンプリング測定レポート。UKCA_COAGWITHNUCL()が目立っている。
Table 1: Profile by Function
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
100.0% | 30997 | -- | -- |Total
|----------------------------------------------
| 58.5% | 18143 | -- | -- |USER
||---------------------------------------------
|| 8.3% | 2579 | 112.91 | 4.3% |advy2_
|| 7.5% | 2314 | 44.16 | 1.9% |chimie_
|| 5.5% | 1696 | 81.25 | 4.7% |ukca_coagwithnucl_
|| 4.1% | 1260 | 27.44 | 2.2% |advz2_
省略
Table 2: Profile by Group, Function, and Line
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
| | | | Source
| | | | Line
| | | | PE='HIDE'
100.0% | 30923 | -- | -- |Total
|------------------------------------------------
| 58.5% | 18090 | -- | -- |USER
||-----------------------------------------------
|| 8.3% | 2577 | -- | -- |advy2_
3| | | | |
gm3_spunup/CoagWithNucl/src_32e/prog.f
||||---------------------------------------------
4||| 1.2% | 385 | 47.56 | 11.3% |line.13203
4||| 3.4% | 1047 | 78.59 | 7.2% |line.13370
4||| 3.6% | 1110 | 74.16 | 6.5% |line.13459
||||=============================================
|| 7.5% | 2310 | -- | -- |chimie_
3| | | | |
gm3_spunup/CoagWithNucl/src_32e/prog.f
||||---------------------------------------------
4||| 1.3% | 408 | 26.62 | 6.3% |line.32966
4||| 3.6% | 1101 | 11.38 | 1.1% |line.33056
4||| 1.4% | 419 | 50.06 | 11.0% |line.33300
||||=============================================
|| 5.5% | 1694 | -- | -- |ukca_coagwithnucl_
3| | | | |
gm3_spunup/CoagWithNucl/src_32e/GLOMAP.f90
||||---------------------------------------------
4||| 1.5% | 466 | 30.66 | 6.4% |line.3422
||||=============================================
図4:GLOMAPのサンプリング測定レポート抜粋の例
複数回サンプリング測定を行い、高負荷がどこに在るかを特定しました。典型的な測定では、USER、MPI、ETCの3つのセクションに分かれます。図4は、USERセクションの抜粋です。58%部分が示すのは、40%以上がGLOMAPの計算部分以外が占めていることを示しています。ETCとMPIセクションでの情報は、本レポートの他の部分で議論します。このセクションは高負荷なソースコード行番号を示します。
CHIMIEとUKCA_COAGWITHNUCLの調査を分けて原因を検討します。目的はCHIMIEとUKCA_COAGWITHNUCLの実行時間の削減です。
多くのコードレビューを行い、好ましくないループ順序がある事が解りました。例えば、このシミュレーションコードのTOMCAT部はカルテシアン座標をベースにするため、多くの箇所で以下のようなループパターンが存在します:
DO L = 1, NIV
DO K= 1, NLATMX
DO I = 1, NLONMX
WORK ON ARRAYS WITH INDICES (I,K,L)
END DO
END DO
END DO
これはFORTRAN配列のメモリー格納順序に沿った、ベストなやり方です。TOMCATは古くから利用されており、ヴェクトルプロセッサ向けに最適化されてきました。しかしながら最新のヴァージョンでは、サンプリング測定で明らかになった高負荷部分の幾つかは、この自然なループ順序に従っていませんでした。幾つかの箇所は明らかにプログラミングミスだったため修正しました。他の箇所では、移流計算に用いるデータ構造をFFT計算に合わせたデータ構造へ変換する部分が高負荷でした。これについては、付録BでSPETRU1, GATHERROW, SCATTERROWに対しても解析しました。
図5a、5bの例は、USER,MPI,ETCの3セクションを示しています。これらは8コアと64コアでの異なる領域分割を用いた実行における、テストシミュレーションの負荷の変化を示します。これらはPE数が多くなるにつれて、MPIセクションが重要になることを示しています。
8PEを用いた、GM3(Cray XT4 Dual Core)のCrayPATサンプリング測定
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
100.0% | 123650 | -- | -- |Total
|----------------------------------------------
| 79.8% | 98686 | -- | -- |USER
||---------------------------------------------
|| 27.3% | 33702 | 109.25 | 0.4% |chimie_
|| 8.8% | 10857 | 174.38 | 1.8% |ukca_coagwithnucl_
|| 6.0% | 7360 | 60.25 | 0.9% |advy2_
|| 3.9% | 4795 | 238.50 | 5.4% |consom_
|| 3.5% | 4364 | 29.88 | 0.8% |advz2_
|| 3.2% | 3956 | 59.12 | 1.7% |advx2_
|| 2.4% | 2945 | 90.12 | 3.4% |ukca_water_content_v_
|| 2.1% | 2586 | 169.75 | 7.0% |ukca_conden_
|| 2.0% | 2448 | 13.50 | 0.6% |ukca_coag_coff_v_
|| 1.8% | 2256 | 73.88 | 3.6% |ukca_solvecoagnucl_v_
|| 1.8% | 2171 | 79.12 | 4.0% |ukca_cond_coff_v_
|| 1.6% | 2016 | 103.00 | 5.6% |ukca_volume_mode_
|| 1.6% | 2003 | 50.38 | 2.8% |prls_
|| 1.3% | 1583 | 110.62 | 7.5% |jac_
|| 1.0% | 1274 | 63.75 | 5.4% |emptin2_
|| 1.0% | 1188 | 34.00 | 3.2% |initer_
||=============================================
| 17.4% | 21498 | -- | -- |ETC
||---------------------------------------------
|| 7.9% | 9808 | 309.00 | 3.5% |__c_mzero8
|| 2.6% | 3212 | 83.75 | 2.9% |__c_mcopy8
|| 1.1% | 1369 | 61.62 | 4.9% |__fmth_i_dexp
||=============================================
| 2.8% | 3466 | -- | -- |MPI
||---------------------------------------------
|| 1.3% | 1587 | 584.38 | 30.8% |mpi_sendrecv_
|| 1.0% | 1264 | 532.00 | 33.9% |mpi_recv_
|==============================================
図5a:8および64領域分割のサンプリング測定の比較。図5bと比較して、8PEではCHIMIEが突出している。
64PEを用いた、GM3(Cray XT4 Dual Core)のCrayPATサンプリング測定
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
100.0% | 22117 | -- | -- |Total
|----------------------------------------------
| 39.1% | 8647 | -- | -- |USER
||---------------------------------------------
|| 5.3% | 1179 | 107.09 | 8.5% |advy2_
|| 3.9% | 871 | 38.41 | 4.3% |chimie_
|| 3.5% | 781 | 40.91 | 5.1% |ukca_coagwithnucl_
|| 2.7% | 601 | 15.22 | 2.5% |advz2_
|| 2.7% | 589 | 10.84 | 1.8% |consom_
|| 2.3% | 512 | 270.48 | 35.1% |advx2_
|| 1.6% | 348 | 112.12 | 24.8% |emptin2_
|| 1.4% | 312 | 50.08 | 14.1% |ukca_water_content_v_
|| 1.3% | 297 | 160.19 | 35.6% |fillin2_
|| 1.3% | 279 | 66.77 | 19.6% |prls_
|| 1.1% | 241 | 18.44 | 7.2% |ukca_coag_coff_v_
|| 1.0% | 218 | 283.30 | 57.4% |spetru1_
||=============================================
| 32.2% | 7118 | -- | -- |MPI
||---------------------------------------------
|| 15.8% | 3486 | 2032.61 | 37.4% |mpi_recv_
|| 11.9% | 2638 | 2207.33 | 46.3% |mpi_sendrecv_
|| 3.8% | 834 | 668.56 | 45.2% |mpi_ssend_
||=============================================
| 28.7% | 6352 | -- | -- |ETC
||---------------------------------------------
|| 7.2% | 1595 | 90.95 | 5.5% |__c_mzero8
|| 7.0% | 1548 | 421.45 | 21.7% |PtlEQPeek
|| 1.9% | 429 | 54.33 | 11.4% |__c_mcopy8
|| 1.8% | 395 | 139.33 | 26.5% |PtlEQGet
|| 1.7% | 372 | 158.47 | 30.4% |PtlEQGet_internal
|| 1.0% | 215 | 79.30 | 27.4% |ptl_hndl2nal
|=============================================
図5b:8および64領域分割のサンプリング測定の比較。64PEではプロファイルは分散された。
関数CHIMIEは8PEでは高負荷です。これは、3次元データ構造を同サイズの1次元配列への変換を行います。この情報はUKCA_AEROSTEPサブシステムで用いられるものです。これは各MPIタスクでシミュレートされる大気部分の3次元体積上で用いられます。全3次元領域が1次元配列へマッピングされることを意味します。
図5aと5bの違いから、シミュレーション性能はMPIタスク数に敏感であることが解ります。CHIMIEは、大きなMPIタスクを用いた場合はサンプリング測定結果テーブル内で順位が下がっていることから、問題サイズが負荷に直接影響することが解ります。ここで、GLOMAPのGM3バージョンで用いられるCHIMIEの手法は、大気の線体積を処理していました。UKCA_AEROSTEPサブシステムは一回に緯度の単一平面上で処理を行うため、この方法を修正し、これをGM4と呼ぶこととします。この平面は緯度毎に構成されるため、その次元は水平レイヤー数と経度ポイント数になります。GM3のテストケースでは、64PE分割において領域当り1/4データ量、8PE分割領域当りでは1/32データ量が処理されます。これはTOMCATの化学セクションで用いられている方法で、GLOMAPの初期バージョンのデータ処理方式です。
4.3 トレース測定
ベースラインのソースをAPAオプションを用いてCrayPATサンプリング用にコンパイルしました。これはapaファイルを生成します。apaファイルは、トレース測定用の実行形式を用意するための全ての情報を含んでいます。サトレース測定用に繰返し実行形式をビルドするには、サンプリング測定を何度もする必要がありません。トレース測定は、トレース測定は、pat_reportツールを用いて処理される新たな測定ファイルを生成します。そのレポートには、トレースされた関数名とそれらの処理にかかった時間が含まれます。
CrayPATは、サブルーチンのトレース情報を採取する特定のタイミングポイントを挿入するAPIインターフェイスを提供します。このタイミングポイントは、ネームタグを与えられ、ポスト処理された測定ファイル内でのそのセクションを特定するのに用いられます。この手法を、サンプリング及びトレースレポートにおいて高負荷順位に現れる関数UKCA_COAGWITHNUCLの調査に多用しました。図6は8MPIタスクで実行した結果です。これはGM3バージョンを用いており、CHIMIEは高負荷として示されています。
Cray PAT API "11 loop init mtran" in UKCA_COAGWITHNUCL call pat_region_begin(11,'11 loop init mtran',pat_stat) ! !!! DO IMODE=1,NMODES !!! NDOLD(:,IMODE)=ND(:,IMODE) !!! DO ICP=1,NCP !!! MDOLD(:,IMODE,ICP)=MD(:,IMODE,ICP) !!! DO JMODE=1,NMODES !!! MTRAN(:,IMODE,JMODE,ICP)=0.0 !!! ENDDO !!! ENDDO !!! ENDDO ! ! replace triple loops above with F90 array syntax (let compiler decide) NDOLD=ND MDOLD=MD MTRAN=0.0 call pat_region_end(11,pat_stat)図6:UKCA_COAGWITHNUCLにおける問題のあるループとその修正
図6では、オリジナルのネストしたループの代わりに別のコーディングを載せています。例えば、"11 loop init mtran"は3次元配列をゼロに初期化するコードブロックです。F90文法により3重ループの個々の変数を取り去る等、幾つかの方法も調査しました。コンパイラはこれらを"idiom: __c_mzero8"へ置き換えました。これはオプション-Minfoを用いればレポートされます。
図7のトレースレポートにおいて、ハッシュ番号ラベル(#11, #5, #2, #10, #7)はCrayPATのAPIを用いて挿入したものです。実際には1から11まで挿入しましたが、この他は負荷の高位には現れませんでした。以上によりUKCA_COAGWITHNUCLは対象から消え去りました。
この他にはコード修正案は見つかりませんでしたが、コンパイラはこのセクションにおいてベストの性能を示しました。
UKCA_COAGWITHNUCL性能向上調査における、8PEでのGM3バージョンのAPI情報を用いたCrayPATトレースレポート
Time % | Time | Imb. Time | Imb. | Calls |Group
| | | Time % | | Function
| | | | | PE='HIDE'
100.0% | 2058.854843 | -- | -- | 6731515 |Total
|----------------------------------------------------------------
| 94.5% | 1945.732550 | -- | -- | 6557264 |USER
||---------------------------------------------------------------
|| 36.9% | 759.508205 | 6.805455 | 1.0% | 144 |chimie_
|| 6.9% | 142.135909 | 8.451937 | 6.4% | 1440 |#11.11 loop init mtran
|| 6.8% | 140.708321 | 41.589230 | 26.1% | 1 |main
|| 6.6% | 136.060100 | 2.901422 | 2.4% | 288 |advy2_
|| 4.0% | 82.400176 | 1.758459 | 2.4% | 144 |consom_
|| 3.9% | 79.572205 | 0.500504 | 0.7% | 144 |advz2_
|| 3.1% | 64.781270 | 2.547494 | 4.3% | 288 |advx2_
|| 2.4% | 50.124924 | 1.249039 | 2.8% | 3456 |ukca_water_content_v_
|| 2.4% | 48.938390 | 2.616689 | 5.8% | 1440 |ukca_conden_
|| 2.3% | 47.166706 | 1.214859 | 2.9% | 4032 |ukca_coag_coff_v_
|| 2.1% | 43.071936 | 3.410142 | 8.4% | 1440 |#5.5 imode loop
|| 2.0% | 41.345881 | 0.211065 | 0.6% | 864 |ukca_volume_mode_
|| 1.9% | 39.174169 | 2.602136 | 7.1% | 7200 |ukca_solvecoagnucl_v_
|| 1.8% | 38.046784 | 1.764512 | 5.1% | 14400 |ukca_cond_coff_v_
|| 1.8% | 37.836103 | 2.580603 | 7.3% | 1440 |#2.imode loop
|| 1.8% | 37.507454 | 1.191105 | 3.5% | 25920 |#10.10 ncp loop
|| 1.8% | 36.644806 | 1.473848 | 4.4% | 1440 |#7.7 imode loop
|| 1.7% | 34.149579 | 1.831906 | 5.8% | 2617 |prls_
|| 1.4% | 28.488018 | 1.145093 | 4.4% | 2617 |jac_
||===============================================================
| 3.6% | 73.941021 | -- | -- | 155216 |MPI
||---------------------------------------------------------------
|| 2.1% | 42.940114 | 10.573601 | 22.6% | 29385 |mpi_sendrecv_
|| 1.0% | 20.905757 | 8.770574 | 33.8% | 35596 |mpi_recv_
||===============================================================
| 1.9% | 39.181272 | -- | -- | 19035 |MPI_SYNC
||---------------------------------------------------------------
|| 1.4% | 28.908872 | 4.654048 | 15.8% | 1123 |mpi_bcast_(sync)
|================================================================
図7: UKCA_COAGWITHNUCL調査でのトレースレポート例
CHIMIEの調査では複数の修正を行いました。外側ループは緯度であることから、オリジナルの全大気領域の3次元から1次元への変換を、3次元から緯度平面内の1次元へのマッピングへ修正しました。GM4に組み込まれた修正は以下の通りです:
- JLと同時にJLABOVEを計算する。
- 地表レベルの配列計算は、2dから1dへのマッピングに対する条件テストを避けてより小さな分離されたループで行う。
- 同様に、モード半径とモード数計算は地表レベルでのみ行うため、これらは3重ループでなく新たな1重ループで行う。
- JLインデックス計算を修正し、4次元から2次元配列へのS0A, S0G, STGマッピングを分離する。
- 大気のエッジでJLABOVEをリセットする。
また、リバースマッピングに対しては、以下のようにしました:
- S0A, S0G, STGに対して、2Dから4Dへのマッピング時にはインデックスカウンタLJ計算を簡略化する。
この他に、6時間毎の濃度に対する補間方法、JLがインクリメントカウンタでなく明白に計算される箇所での条件文とその他のループの再構成、等の修正もありましたが、作業時間制限のため行っていません。
4.4 コード構造修正の結果
GM3はGM4バージョンへ更新されました。主な変更は、CHEMIE内のUKCA_AEROSTEPに対する緯度平面内のデータ処理です。データは多次元配列(高度、経度の緯度平面)から、1次元配列へマッピングされ、エアロゾルと化学計算に用いられます。Task1で決定した最適化を考慮に入れた2つのバージョンの性能差を、表6と図8に示します。
| Number of MPI tasks | 8 | 16 | 32 | 64 | 128 |
| GM3 seconds per step (dc with -O3) | 13.75 | 6.15 | 3.18 | 1.95 | 1.64 |
| GM4 seconds per step (dc and -fast) | 7.91 | 4.45 | 2.66 | 1.77 | 1.29 |
| Improvement (%) | 42.49 | 27.62 | 16.27 | 9.09 | 21.12 |
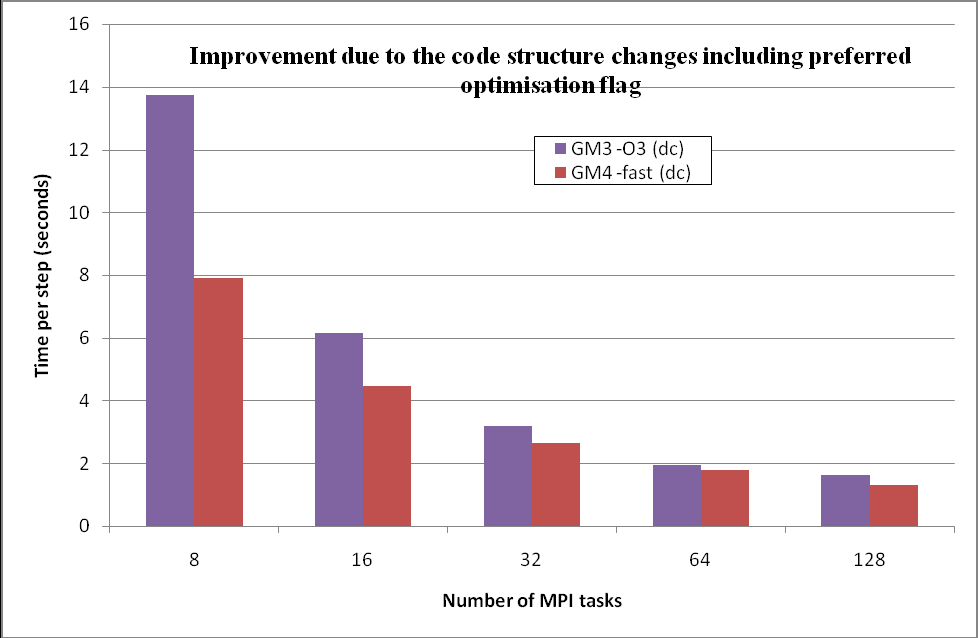
図8:GM3とGM4の性能比較
領域サイズが大きい場合に大きな利得が得られています。例えば、8MPIタスク分割では、GM3は31744ボックス(32x32x31)ですが、GM4では992ボックス(32x31)です。64MPIタスク分割では、GM3は3968ボックス(32x4x31)ですが、GM4では992ボックス(32x31)です。化学サブステップ(UKCA_AEROSTEP)で用いる配列サイズは、緯度毎にデータが処理される場合は極めて小さくなり、サブ領域で処理される緯度ポイント数に間接的に比例します。T42解像度では、高いレベルでの追加の緯度ループは有りますが(CHIMIEサブルーチン)、処理されるデータは1/64です。
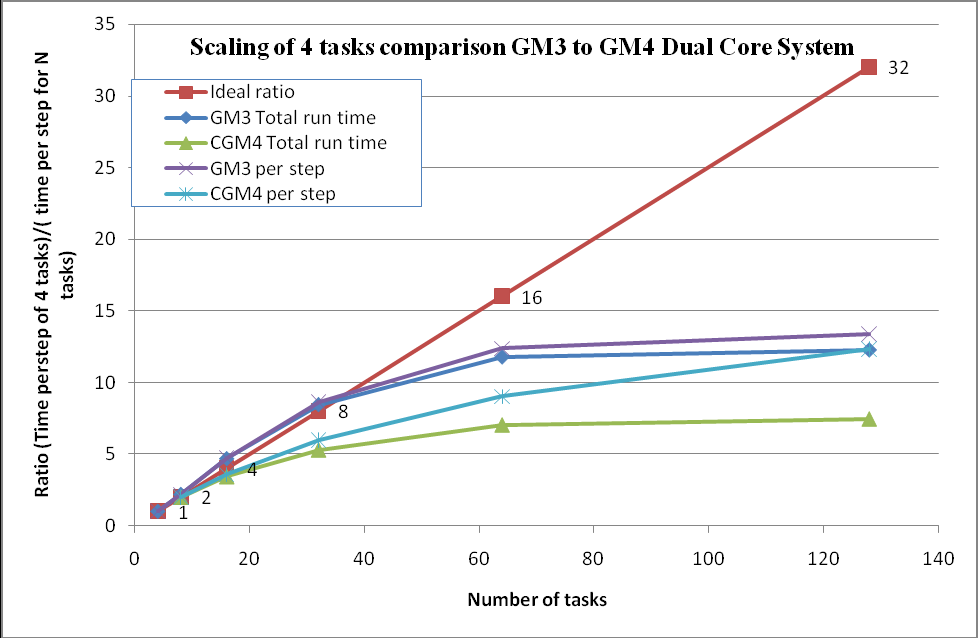
図9:4MPIタスク時の実行時間と、ステップ当りの時間の関係
図9で高速化状況を示します。シリアル実行セクションの影響により、性能は悪化します(既に64PEにおいてスケール性が劣化しています)。しかしながら、最初と最後のステップを無視した場合(紫とシアン色)、GM4のスケール性は回復し、タスク数が大きいところではGM3の値に近づいていきます。
PE数が大きくなると性能が劣化するのは、先述したような各分割領域の緯度当たりの計算量が固定な部分が存在することと関連しています。
化学サブステップを処理するコードは、効率的な書き方になっています。多次元ループは、平面内のボックス数の一次元ループへアンローリングされています。この状況がコンパイラにさせるのは、単純な最適化です。インライン展開やベクトル化(-O3から-fastへ変更すること)では、このセクションに対して大きな影響を与えません。キャッシュブロッキングが性能を改善するかもしれませんが、その調査は行っていません。
性能劣化の他の原因として通信が有ります。CrayPATサンプリング測定では負荷分散が示されており、他のタスクとの同期のためにアイドリングするタスクが存在します。しかしながら、原子種により異なる計算が要求されるため、このバージョンをバランスさせるのは困難です。性能改善は、通信に必要な作業が通信サブシステム(MPIレイヤ)で可能な場合に、通信をオーバーラップさせることです。例としては、送信と受信によるやり取りがある場合です。良くあるやり方はMPI_SENDRECVを用いる簡単な方法です。しかしながら、ノンブロッキング受信は、送信を行う前に隣接PEからデータを受信するバッファを用意するために利用されます。この検証は行っていませんが、付録Bの解析により、通信ポイントを置き換える設計をすべきです。
図10はGM4のサンプリング測定結果で、明らかにCHIMIEの負荷が減少していることが見て取れます。
8PE(XT4デュアルコア)上でのGM4のCrayPATサンプリング測定レポート
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp% | Function
| | | | PE='HIDE'
100.0% | 73918 | -- | -- |Total
|---------------------------------------------
| 69.5% | 51363 | -- | -- |USER
||--------------------------------------------
|| 10.9% | 8077 | 73.50 | 1.0% |advy2_
|| 10.3% | 7580 | 202.38 | 3.0% |ukca_coagwithnucl_
|| 6.6% | 4882 | 35.88 | 0.8% |consom_
|| 6.4% | 4713 | 11.88 | 0.3% |advz2_
|| 5.4% | 4012 | 66.00 | 1.8% |advx2_
|| 2.9% | 2131 | 53.50 | 2.8% |ukca_water_content_v_
|| 2.5% | 1811 | 97.25 | 5.8% |chimie_
|| 2.4% | 1779 | 56.62 | 3.5% |ukca_conden_
|| 2.2% | 1611 | 52.88 | 3.6% |ukca_calc_coag_kernel_
|| 1.9% | 1418 | 30.38 | 2.4% |ukca_aero_step_
|| 1.7% | 1273 | 21.00 | 1.9% |emptin2_
|| 1.7% | 1254 | 219.25 | 17.0% |initer_
|| 1.5% | 1143 | 17.75 | 1.7% |radabs_
|| 1.3% | 939 | 43.00 | 5.0% |ukca_ddepaer_incl_sedi_
|| 1.2% | 917 | 170.75 | 17.9% |fillin2_
|| 1.2% | 875 | 67.75 | 8.2% |update_1dvars_by_cstep_
||============================================
| 26.5% | 19590 | -- | -- |ETC
||--------------------------------------------
|| 11.1% | 8236 | 166.75 | 2.3% |__c_mzero8
|| 3.6% | 2666 | 45.88 | 1.9% |__c_mcopy8
|| 1.5% | 1093 | 421.00 | 31.8% |PtlEQPeek
|| 1.3% | 937 | 44.50 | 5.2% |__fmth_i_dexp
|| 1.0% | 729 | 41.38 | 6.1% |__fvdlog_long
|| 1.0% | 715 | 61.25 | 9.0% |munmap
||============================================
| 4.0% | 2965 | -- | -- |MPI
||--------------------------------------------
|| 1.7% | 1223 | 573.88 | 36.5% |mpi_recv_
|| 1.6% | 1165 | 246.50 | 20.0% |mpi_sendrecv_
|=============================================
図10: 8PEを用いたGM4のCrayPATレポート。図5aの27.3%から2.5%へと、CHIMIEの順位が下がった。
Kループは、3次元配列の2番目のインデックスであり、もしデータ構造を緯度平面で組み替えられれば、更なる性能改善が可能になります。例えば、2番目と3番目のインデックスを交換し、下記の左図のコードから右図のコードへ変更します:
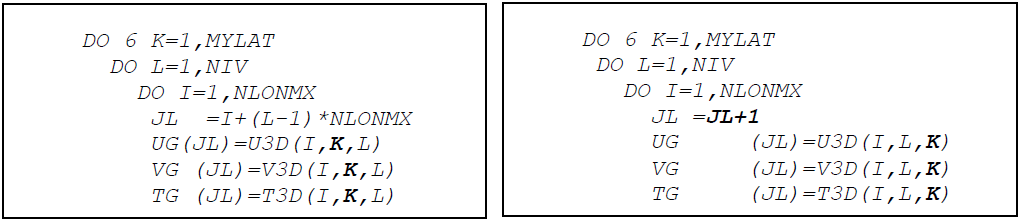
TOMCATにはこうしたループが非常に多く存在しますが、この最適化は行っていません。
4.5 Task2.1の結論
コード内の高負荷箇所を特定するために、性能解析ツールが用いられました。この中で、2つのサブルーチン(UKCA_COAGWITHNUCLおよびCHIMIE)を特定し、調査と改良が検証されました。エアロゾル・サブシステムに対しては異なる手法が適用され、シミュレーション全体の性能を改善しました。この性能改善はGM4に対して行われ、CHIMIEがデータ容積でなくデータ平面を扱うことからループ長が大きく減少しました。
最適化対象の幾つかは改善されませんでした。特に、UKCA_COAGWITHNUCL関数が化学計算時間ステップ毎に最初に配列を初期化する部分です。これは、3,4,5次元配列の、たとえそのサイズがグリッドボックスの総数と比べて小さくても、その形状によるものと考えられます。このサブプログラムの主要な処理は、初期化処理であると言えます。
5 Task2.2:並列演算の最適化
5.1 現状の並列実装
コンピュータプログラムの並列演算には様々な課題がありますが、そのうちの一つが並列タスク間通信です。一般的な方法論では、ローカルデータをローカルバッファへパッキングし、それを通信レイヤーを通して他のタスクへ渡します。同時に(ほぼ同期して)他のタスクから受信した情報を更なるローカルバッファへ保存して、必要に応じて作業領域へ転送されます。転送データはハロデータとして参照され、この処理はハロ交換(halo exchange)と呼ばれます。
このコード内に在る共通の実装では、(ループによって)トポロジーの同列上のMPIタスクIDを全て繰り返し、通信が必要かどうかをテストする仕組みです。
例えば、CALFLUでは以下のようにしています:
C Loop over PEs in row DO 91 J=0,NPROCI-1 C C Only calculate for PEs in this column IF (J.EQ.ICOL) THEN C C b. initialisation C IF (ICOL.EQ.0) THEN
通信を必要とする相手は限られたPEのサブセット(隣接PE)であるというデータの局所性から、これは通常は無駄が多いです。基本的な最適化は、通信を必要とするタスクを再計算し、通信相手のソートされたリストを作成することです。このリストは、バッファーへの負荷を調節し、到着した情報のアンパッキングを加速するのに用いることが可能です。その他の最適化は、必要となる場面よりも早期に受信バッファーを準備して、情報受信を他のタスクでも可能にすることです。
このアプリケーションで用いられている領域分割の強固な構造と不変性は、構造とリストを事前に決定するのに都合の良い性質です。実際に、あるセクションでは既に隣接PEが計算されるコードが存在し、これらはEXCHUVおよびDOCOMM2での主なデータ交換の通信に用いられています。
その他のGLOMAPで現れる通信はグローバルなブロードキャストで、あるタスクのデータは他の全てのタスクで必要になります。典型的には総和やリダクションといったもので、それらをサポートする専用の演算とMPIの関数は有ります。しかしながら、GLOMAPのある部分では、データ送受信の組合せによるこれらのカスタムバージョンが存在します。
FFTを使って方程式を解くコードセクションは、TOMCATコードの残りの部分とは異なる領域分割を持っています。緯度の全ラインはPE間で共有され、SPEGRD1から呼ばれるサブルーチンはFFT解析用のデータ構造を用います。一つのデータ形式から別の形式への変換は時間の掛かる作業であり、また、新たな作業領域に要するメモリーもペナルティーとなります。
CrayPAT解析は選択した関数グループについての情報を提供します。有用な関数グループの一つがMPI関数です。そのサンプルレポートにはMPI関数に関する情報が示されています。MPI通信負荷はMPIタスク数と共に増加します。これは一般的に予想されることです。解くべく問題がMPIタスクで分解される際には、タスク数が増えると問題はより小さくなります。よって、より多くのインターフェイスやハロ交換を要する境界を生じ、個々のタスク計算に対する通信の割合が増加します。
5.2 ソースコードレビュー概要
ソースコード内の全てのMPI通信を検索し、同時にCrayPATで高負荷だったサブルーチンを特定しました。この他のサブルーチンもありましたが、これらは計算負荷が多くを占めるものであったため調査は行いませんでした。
各サブルーチン解析の詳細は付録Bに在ります。以下では、並列効率改善の対象エリアと、影響を受けるルーチンおよび全実行時間の改善のための方法を説明します。
実行環境の変更
SETMPP:PEのグルーピングに新たな構造を導入し、新しいグループのMPIコミュニケータを生成し、プロセッサートポロジー生成はメインプログラムからこのルーチンへ移動されました。このルーチンはINIEXPからメインプログラムへ移されました。
FFTSETUP:このルーチンはSPEGRDからメインプログラムへ移されました。実行中に不変なのでこれを繰返す必要はありません。開発者との相談の後にこのルーチンはCALPHYへ移されました。
通信パターンの変更
CALFLU,CALSUB:これらルーチンは、通信上のカスケード効果を生じる送信と受信のペアリングを含んでいます。これは、より効率的な(送受信の待ち時間の短い)別の周期的な手法で置き換えました。
方向特定のバッファパッキング・アンパッキングによるFILLIN2とEMPTIN2の置換え
DOCOMM2:これは単方向移流スウィープ間の通信パターンを制御します。以下のルーチンを2回繰り返す短いループを持ちます:
FILLIN2:これは異なる変数に対し複数回呼ばれ、ローカルデータ配列から通信バッファへのデータコピーのやり方を決定する条件分を含んでいます。
LISTCOMM:これはトポロジー内のどのプロセッサーがデータを受信して交換を開始するかを決定します。
EMPTIN2:これはFILLIN2サブルーチンの呼出しに対応して多数回呼び出されます。これも、どのようにデータが通信バッファからローカルデータ領域へコピーされるかを決定する条件文を持ちます。
この条件テストは深いレベルに在るため、不必要に繰り返されて非効率性を生じます。ループはアンローリングされ、FILLIN2サブルーチンはテストが不要なLOAD_NSやLOAD_WEの呼出しに置き換えられました。同様にEMPTIN2はLOAD_NSやLOAD_WEの呼出しに置き換えられました。
EXCHUV:これはDOCOMM2と似ていますが、より多くの速度場計算を行います。ループ・アンローリングとFILLLIN2とEMPTIN2の置き換えといったDOCOMM2と同様の修正を施しました。
バッファのローディング/アンローディングの効率化
GATHERROW,SCATTERROW:これらは、PBLスキームのFFT領域分割での通信バッファーをロードおよびアンロードします。コードレビュー中に非効率なループ順序が見つかり、ループIとJを交換しました。
集団リダクション演算の変更
SPETRU1,POLCOMM:これはグローバルなリダクション演算をエミュレートする送信、受信関数を含んでいます。これらを適切なMPIリダクション関数に置き換えました。
5.3 通信セクションの変更の結果
ベースラインと改良版のGM4のクアッドコアシステムでの比較しました。全体の結果は表12に示します。改良版GM4は元のGM4に比べて、16PEで2.56%、32PEで9.44%、64PEで7.61%高速化しました。
表7,8は通信パターン修正後の当初の測定結果です。
| NCPU | 8 | 16 | 32 | 64 |
| Tinit | 33.74 | 31.2 | 36.98 | 47.81 |
| T143 | 1231.499 | 710.2 | 424.32 | 294.99 |
| T144 | 1244.23 | 720.6 | 435.24 | 309.52 |
| Ttotal | 1251.98 | 730.6 | 449.5 | 332.91 |
| Ttot-T143 | 20.481 | 20.4 | 25.18 | 37.92 |
| T143-Tinit | 1197.759 | 679 | 387.34 | 247.18 |
| (T143-Tinit)/142 | 8.43 | 4.78 | 2.72 | 1.74 |
| NCPU | 8 | 16 | 32 | 64 | 128 |
| Tinit | 32.74 | 30.62 | 33 | 42.28 | 66.17 |
| T143 | 1180.93 | 656.1 | 372.6 | 264.3 | 261.8 |
| T144 | 1192.79 | 665.5 | 382.3 | 277.8 | 284.4 |
| Ttotal | 1199.47 | 674.4 | 395.4 | 299.1 | 321.9 |
| T143-Tinit | 1148.19 | 625.48 | 372.6 | 222.02 | 195.63 |
| (T143-Tini)/142 | 8.08 | 4.40 | 2.62 | 1.56 | 1.37 |
| Percentage change from table 7 | -4.1% | -7.9% | -3.6% | -10.3% | NA |
ベースラインと改良版GM4に対するサンプリング測定は、64PEで行いました。2つのサブルーチンEMPTIN2とFILLIN2はもはやランク外で、それらを置き換えたルーチンについても現れていません。MPI呼出しに掛かる時間の削減については、MPI_CART_CREATEを用いるSETMPPからの新たな寄与が予想された通りに、それほど大きな変化は有りませんでした。USERサブルーチン全体のプロファイルは大きくは変化しておらず、CONSOMの負荷分散が小さくなっています。このサブルーチンからdoループ内の条件文が削除されたためです。
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
100.0% | 23849 | -- | -- |Total
|----------------------------------------------
| 36.8% | 8781 | -- | -- |MPI
||---------------------------------------------
|| 18.2% | 4334 | 2548.84 | 37.6% |mpi_recv_
|| 14.0% | 3347 | 2818.92 | 46.4% |mpi_sendrecv_
|| 3.9% | 941 | 831.44 | 47.7% |mpi_ssend_
||=============================================
| 33.8% | 8065 | -- | -- |USER
||---------------------------------------------
|| 5.7% | 1365 | 142.03 | 9.6% |advy2_
|| 3.2% | 756 | 204.92 | 21.7% |consom_
|| 3.1% | 737 | 95.91 | 11.7% |ukca_coagwithnucl_
|| 2.7% | 637 | 23.19 | 3.6% |advz2_
|| 2.2% | 522 | 268.17 | 34.5% |advx2_
|| 1.7% | 416 | 288.33 | 41.6% |emptin2_
|| 1.4% | 343 | 262.20 | 44.0% |fillin2_
|| 1.2% | 283 | 69.45 | 20.0% |chimie_
|| 1.0% | 237 | 17.14 | 6.9% |calflu_
|| 1.0% | 229 | 51.72 | 18.7% |ukca_coag_coff_v_
||=============================================
| 29.4% | 7003 | -- | -- |ETC
||---------------------------------------------
|| 5.6% | 1347 | 235.38 | 15.1% |__c_mzero8
|| 5.5% | 1309 | 337.02 | 20.8% |PtlEQPeek
|| 2.9% | 684 | 204.52 | 23.4% |fast_nal_poll
|| 2.2% | 527 | 200.42 | 28.0% |PtlEQGet
|| 1.6% | 390 | 104.27 | 21.4% |PtlEQGet_internal
|| 1.5% | 362 | 188.81 | 34.8% |MPIDI_CRAY_smpdev_progress
|| 1.4% | 344 | 65.81 | 16.3% |__c_mcopy8
|| 1.1% | 273 | 32.80 | 10.9% |__fmth_i_dexp_gh
|| 1.1% | 256 | 85.16 | 25.4% |ptl_hndl2nal
|==============================================
図11a:通信の修正前のGM4の、64PEでのCrayPATレポート
図11aに通信に掛かる時間の上位3つをハイライトしました。ETCセクションは大きな割合を示しています。これは、MPIの基盤となる通信層レイヤー"portal"を含むシステムの作業を表しています。
Samp % | Samp | Imb. | Imb. |Group
| | Samp | Samp % | Function
| | | | PE='HIDE'
100.0% | 26158 | -- | -- |Total
|----------------------------------------------
| 34.3% | 8971 | -- | -- |MPI
||---------------------------------------------
|| 15.0% | 3927 | 2316.62 | 37.7% |mpi_recv_
|| 11.7% | 3069 | 2339.02 | 43.9% |mpi_sendrecv_
|| 3.5% | 910 | 767.52 | 46.5% |mpi_ssend_
|| 3.1% | 812 | 773.25 | 49.6% |mpi_cart_create_
||=============================================
| 33.5% | 8754 | -- | -- |ETC
||---------------------------------------------
|| 7.1% | 1855 | 333.95 | 15.5% |PtlEQPeek
|| 5.5% | 1440 | 204.62 | 12.6% |__c_mzero8
|| 3.8% | 984 | 212.80 | 18.1% |fast_nal_poll
|| 3.0% | 772 | 181.59 | 19.3% |PtlEQGet
|| 2.2% | 571 | 149.44 | 21.1% |PtlEQGet_internal
|| 2.0% | 515 | 139.47 | 21.7% |MPIDI_CRAY_smpdev_progress
|| 1.4% | 367 | 43.12 | 10.7% |__c_mcopy8
|| 1.4% | 365 | 106.11 | 22.9% |ptl_hndl2nal
||=============================================
| 32.2% | 8433 | -- | -- |USER
||---------------------------------------------
|| 5.0% | 1298 | 193.70 | 13.2% |advy2_
|| 4.9% | 1290 | 19.72 | 1.5% |consom_
|| 2.7% | 708 | 105.41 | 13.2% |ukca_coagwithnucl_
|| 2.5% | 660 | 162.69 | 20.1% |advx2_
|| 2.4% | 620 | 23.67 | 3.7% |advz2_
|| 1.2% | 314 | 36.11 | 10.5% |chimie_
|==============================================
図11b:改良版GM4の、64PEでのCrayPATレポート。通信の改良はETCセクションの割合を増加させた。CONSOMはバランスしており、EMPTIN2とFILLIN2は削除されている。
MPIの実行時間の割合は減少したが、ETCの割合は増加しました。これはシステムレイヤーの仕事の増加によるものと考えられます。USERセクションはバッファローディングの合理化により減少しました。バッファサイズは変えていないため、繰返し毎のETCとMPIによる仕事量の変化はありません。
図12を作成した目的は、通信の修正がもたらした改善を示すためです。このセクションの後方で詳細に論じる、ノード当たり1コアを利用した場合の影響も見ることが出来ます。この図は、性能のスケール効果を強調するために、軸のスケールをlog2で表示しました。
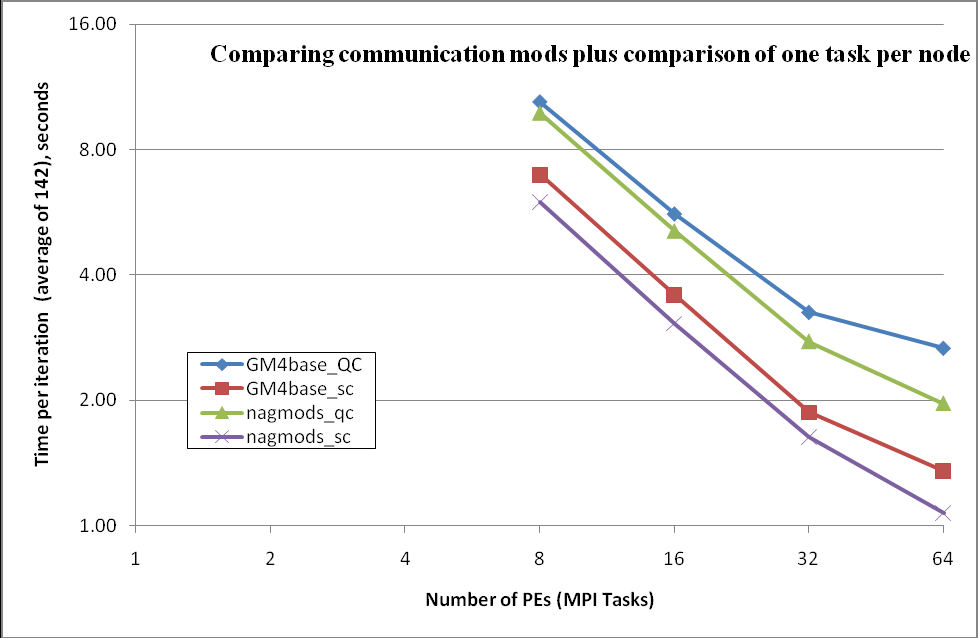
図12:通信パターンの修正によるGM4の性能評価。三角とダイヤの線はクアッドコア演算のものです(ノードは飽和している)。クロスと四角形の線はノード当たり1コアのみを使用したものです。
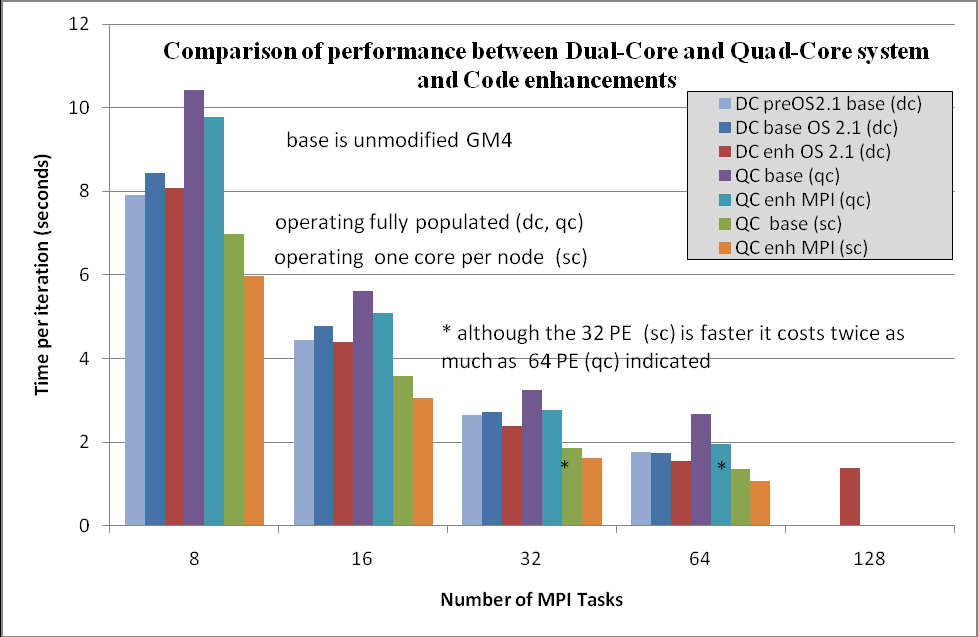
図13:GM4の修正版の性能改善比較
GM4の性能に影響する幾つかのパラメータを図13で比較しました。時系列の比較では以下の変化があります:
- ベースライン比較でOS2.0からOS2.1へ変更された
- ベースラインと通信パターン修正版間の性能改善
- 飽和デュアルコアからクアッドコア間の性能差
- クアッドコアシステム上での4コアと1コア間の性能差
各グループの最初の2つのバーの差はタスク数が多い場合は小さくなっています。これはクアッドコアへの更新前の、古いOS(2.0.56)から新しいOS (2.1)への変化です。この原因については調査はしていません。
2番目と3番目のバーの差は、クアッドコアへの更新前の通信性能の改善によるものです。この結果により付録Bの調査へ作業を進めました。
2番目から4番目のバーへ時間が伸びたのは、クアッドコアへの移行によるものです。これは、デュアルコアに対してクアッドコアが、クロックが落ちたこととコア当たりのメモリーの減少により引き起こされています。デュアルコアとクアッドコア間の主要な違いを表9に示します。
| Platform | Dual core | Quad core |
| L2 cache | 1 MB/core | 512 KB/core |
| L3 cache | None | 2 MB (shared) |
| Main RAM | 6 GB (~3GB/core) | 8 GB (~2GB/core) |
| Clock speed | 2.8 GHz | 2.3 GHz |
ノード当たり一つのMPIタスクを用いた場合(6番目と7番目のバー)に、メモリーの課題が明らかになります。この場合は飽和ノード上での実行に比べて4倍高コスト(ノード課金)になりますが、ステップ当りの実行時間は半分となっているため、飽和ノードでの実行コストの約2倍となります。
これは、アプリケーションはより多くのメモリーが必要で、L3キャッシュをフルに用いたほうが有利であることを示しています。別の見方をすれば、メモリーの有効利用を行い、ノード上の全てのコアを用いて演算する際にキャッシュをより有効に利用するチューニングを行えば、大きな改善が出来ます。
通信については、1/4のリソースしか利用していないにも関わらず2倍に収まっており、改善されています。この結果は、次期プロジェクトで予定されるハイブリッド並列化が有効であることを示しています。クアッドコアノード当たり1MPIタスクで、各コアに4つのOpenMPスレッドを割当てる構成を予定しています。
64MPIタスクまでスケールさせるために、やるべきことはまだ有ります。対処できることは、通信と計算のオーバーラップと、メモリー削減、OpenMP化です。
図13の別の表現として、図14に高速化率を示します。データは連続的には有りませんが、通常これらは曲線として表現されます。図14は8PEに対するスケール性を示します。ガイダンスとして理想曲線(直線)を追記しています。例えば64PEでは、8PEの場合よりも8倍高速になることが、理想的には期待されます。
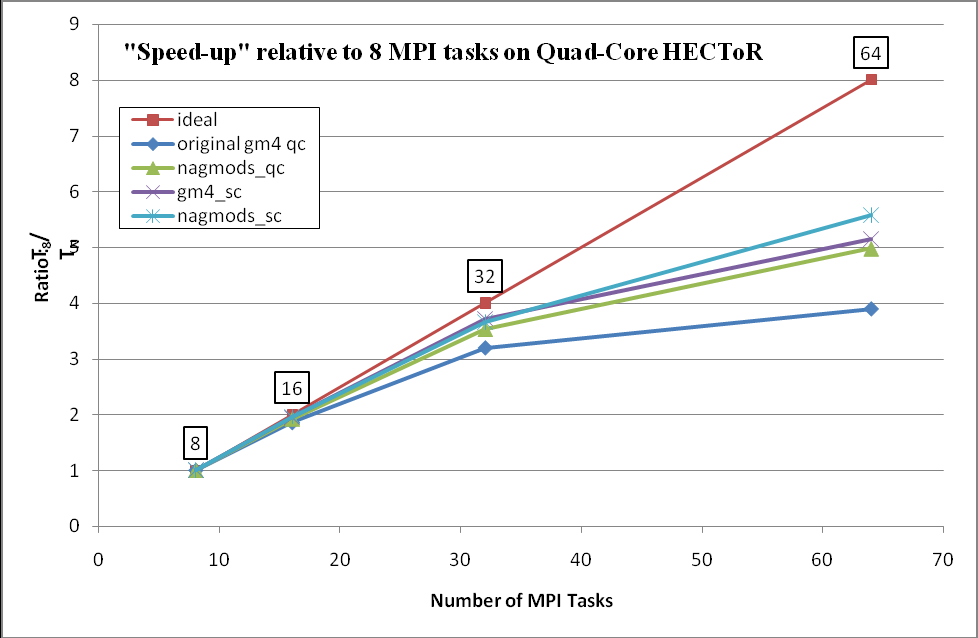
図14:クアッドコア(_qc)およびノード当たり1コア(_sc)上での性能。改良版GM4はnagmodsとして在ります。
6 Task2.3:ファイルの入出力改善のため並列ファイル操作
6.1 概要
並列マシン利用をする際のファイルシステムとの関係が、このソフトウェアに対する次の課題です。これは、シミュレーションの各ステージの、何処で如何にしてデータを保存し取り出すかという問題です。一般に多くの場合、コードは以前の実行で生成されたデータから開始され(リスタート)るか、シミュレーション進行を制御するデータを必要とします。プログラム実行中は、後のデータ解析のために、あるいは実行状況のレポーティングのためにデータを書出します。より強力な並列システムが将来研究者に利用されていきますが、これは研究作業の複雑さを増加させ、処理されるデータ量の増加を招きます。
プログラミングでは伝統的に、以下のモデルがファイルアクセスに用いてられてきました:
a)各MPIタスクは自身のデータを個別のファイルに対して読み書きする
これは、プロセッサーグループに個別のディスクシステムを持つ分散並列システムに適しています(SMPクラスターシステム)。シリアル実行に比べて、短いファイル書込み時間を持ちます。これは極めてスケーラブルですが、ファイルシステムに依存します。
欠点は、データファイルをMPIタスク数分に分割し、ポスト処理でこれらをつじつまの合った単独のファイルへ結合する、補助的なアプリケーションが必要なことです。多数のファイル管理は問題が生じやすいことです。
b)I/Oマスタータスクが一括して行う(通常はMPIランク0)
他のズべてのMPIタスクがマスタータスクへデータを転送して書出されます。(逆に、マスタータスクは単一ファイルを読み込み、それを他の全てのタスクに分配します)
これは多くの場合最も管理しやすい形式で、データファイルはシリアル実行と同等な扱いのままです。PEの種類に依らず可能で、事前のデータ処理も、ポスト処理も不要です。これはポータブルで如何なる並列マシン上での可能です。
欠点は、I/Oマスターが、出力前と入力後にグローバルデータを保持しなければならないことです。この他に(より重要かもしれません)、他のプロセッサは、マスターの入出力完了を待たねばならず、作業前にデータを通信しなくてはならないことです。これは、プログラムが煩雑にI/Oをする場合にはスケール性に有害となります。
c)GLOMAPではI/Oマスターを用いています
全タスクは、MPI専用データ構造を用いて、共有ファイルに対して入出力します。
この方法は分割と統合のためのアプリケーションを必要としません。これは(a)と同程度に速くなる可能性がありますが、並列計算環境向けのファイルシステムが必要です。単一ファイルにアクセス可能なタスク数には制限があり、(a)が到達可能なスケールに対しても制限されます。並列ファイルシステムへアクセス可能な新たなデータ構造の設計と実装の拡張は多大な労力が必要です。データ構造はファイル内のデータパターンを記述する適切なデータ型を持たねばなりません。
d)I/Oサブグループ:タスクのサブグループが、MPIデータ構造を用いてMPI-IOによるファイル操作を行う
これはファイルシステムの制限を回避できますが実装は複雑です。これは(c)と(b)の妥協で、並列データ構造の定義と、ファイル操作のタスク選定という余分な作業が必要になります。これらのタスクは、データ操作をしている時には計算は行えず、他のタスクはファイル操作が完了するまでアイドル待ちになります。並列トポロジーの定義の際は、1回限りのセットアップのペナルティーが有ります。グループサイズの選択は(c)の改善に大きな影響を及ぼします。I/Oグループと他のタスク間の通信に必要なことが一つあります。負荷分散を回避するようにシステムを設計することですが、それはGLOMAPモデル内ではありません。
6.2 既存バージョンにおけるケーススタディーでのファイルアクセス解析
ジョブ前処理中に86ファイルがケースディレクトリにコピーされます。実行中には1つのファイルが生成されます(fort.9,fort.31)。初期に、他のディレクトリへの9つのシンポリックリンクが生成され、これらの幾つかはファイルをローカルディレクトリーへコピーするのに用いられます。通常のシミュレーションでは、幾つのファイルがアクセスされるかを見極めるのは容易ではありません。データの幾つかはTOMCATの場データ(風、表面値など)の更新に用いられ、他のデータはGLOMAPの排出、濃度計算で用いられます。
ファイルを入出力すべき場所は複数あります。これは設定した間隔で生じ、マスターMPIタスクテストで保護されます。初期化中にこれらは、マスターI/Oタスクからのみアクセスされ、データの全てが保存されます。全並列コードの演算モードは静的配列に対するSPMDで、全てのタスクはグローバルデータの保存に十分な領域を持ちます。最後にギャザー演算が、fort.9やfort.25またはシーケンシャルプログラムと他の場所で処理されたファイルを出力するために必要となります。
GLOMAPに実装された並列演算の分散メモリーモデルは、マスタープロセッサ(task id 0)がファイルから全てのデータを入力して各タスクに分配した後に要求されます。幾つかのデータは不変で、その通信は大規模配列のブロードキャスト形式を取り、その配列はマスタープロセス上の情報を格納したグローバル配列のコピーそのものです。次に各タスクは、自身の処理に必要な情報部分を展開します。これは不必要な処理で、2つの望ましくない効果を生じます:プロセス当たりの要求メモリーは必要以上に大きく(マスタータスクメモリー要求が削減されても)、相互通信(all-to-all)量が膨大で通信ネットワークを飽和させます。これらは、MPI-IOあるいはROW-MASTER I/Oモデルのスキャッタ演算のどちらかに置き換えることが可能です。場合によっては、マスターI/Oタスクは全データを他の全てのタスクへブロードキャストし、これらタスクは自身に必要なものを展開します。これは、マスターI/Oが個々のタスク分へ展開せずに、個別に送信するという場合にのみ効率的です。しかしながら、これは通信レイヤーを飽和させ、ボトルネックを生じる可能性があります。
ファイルアクセスの別のモードとして、PPWRITあるいはPPREADのどちらかを利用する方法があります。PPREADは、選択したデータをファイルから読み込みます。次にMPE_SSENDを呼出して、そのデータを他のPEへ分配します。このデータは追加の複雑性を持ちます。それはこのデータがハロ情報(Sxxモーメント配列など)を持ったり持たなかったりすることです。そこで、他のPEへスキャッタ中にどのように情報を参照するかを決める、低レベルの条件テストを行うようにします。
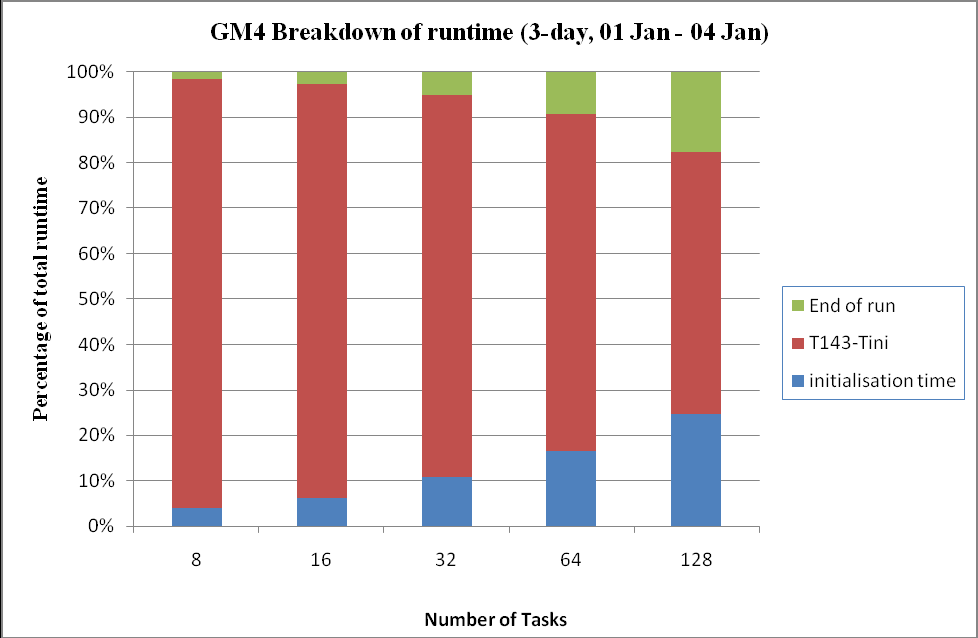
図15:最初と最後のステップ実行時間を、3日の全シミュレーションに対する割合として示す。
図15から、最初と最後の時間ステップにおけるマスターI/Oによる仕事量が多いことが解ります。また、MPIタスク数が大きくなるほど状況が悪化することが示されています。図15は、これら3つのセクションの実行時間を、全シミュレーション時間の割合で示しています。このシミュレーションは、3日間分であることを考慮すべきでしょう。通常行われるシミュレーションは30日分であり、そこではI/Oに必要な時間の割合はより小さくなります。メインの繰返しにはI/Oも含まれていますが、今回はそこまでの詳細な調査は行いませんでした。当初の観察結果では、6時間毎の濃度入力は時間ステップでの時間を倍にします。これは内部的な計算時間の1/13になるまで加算します。
6.3 ファイルアクセス性能改善のための推奨
HECToRのファイルシステムLUSTREの能力を活用するには、データファイル入力を並列ジョブにした方が得です。望ましいやり方は、MPI-IOを用い、F90のデータ構造を用いて、各MPIタスクに主に読込専用の入力ファイルから自身のセクションを読み込ませることを可能にすることです。もしMPI-IOが動作しない場合(データ構造が複雑すぎるか編集不可の場合)には、ファイル読み込みにMPIタスクのサブセットを用いたrow方向手法を用い、同じ緯度を共有する他のMPIタスクへそれをスキャッタするというやり方へ立ち戻ります。追加のファイルハンドラ、PEグループ、コミュニケータの宣言をするSETMPPを追加しました。
6.4 ファイルデータ構造の実装
MPI-IO利用サポートのため、新しいデータ構造を宣言しなくてはなりません。これらはデータと、それらがハードディスクに保存される方法の記述です。例えば、ファイルハンドリングのための追加の構造はMPIデータ型です:
- ハロを持たないデータ:data2d_nh_t,data3d_nh_t
- ハロ情報を持つデータ:data2d_wh_t,data3d_wh_t
- コミュニケータと配列:COMM_PIOは並列I/Oに含まれるプロセスグループを特定する。(当初の実装では、これはMPI_COMM_WORLDと同じになりました)
ファイルフォーマットは明確に定義されます。ファイルをカテゴライズして、各カテゴリ専用の実装を可能にしました。最も簡単な例は、標高毎の緯度毎の経度により組織化された体積情報です。通信専用の情報を追加して、グローバルデータの重複除去を可能にしました。起動タイミングのトレンドはプロセッサ当たりのデータが少なくなるように修正されます。
ファイルカテゴリーはそのデータ内容を基にしています:高解像度データ(1x1)、T42解像度データ(ハロデータ無)、T42解像度データ(ハロデータ付)、任意のFFT係数データ。データの幾つかは、特定の標高での緯度毎の経度平面や、特定の緯度(通常は北極から南極)での標高毎の経度平面として構成されます。こうしたカテゴリは各々、並列アクセスを可能にする定義されたデータ型を必要とします。
残念ながら、実装は完成しておらずテストは出来ていません。
7 全体の要約
GLOMAP/TOMCATコードは、GLOMAP Mode MPIのケースに対して解析され、シリアル実行性能を改善する修正が実装されました。並列演算のアルゴリズム解析から、通信パターンを改善したところ小さいながら利得を得ました。この修正はEverest等の多プラットフォームにも施されました。結果として以前よりも効率的に64PEを利用することが可能になりました。
| Number of MPI Tasks | 8 | 16 | 32 | 64 |
| GM4 (QC -O3) | 1485 | 783 | 449 | 334 |
| GM4 (QC -fast) | 1387 | 742 | 434 | 302 |
| Improvement % | 6.60 | 5.24 | 3.34 | 9.58 |
表10は飽和クアッドコア上の実行時間で、全ての分割に関して改善が示されています。32PEが最も改善が小さくなっています。この結果は、メモリー効率が最適であることを示しています。
| Number of MPI Tasks | 8 | 16 | 32 | 64 |
| GM3 (DC -O3) | 1952 | 872 | 451 | 276 |
| GM4 (DC -O3) | 1122 | 631 | 377 | 251 |
| Improvement % | 42.48 | 27.62 | 16.26 | 9.08 |
表11は飽和デュアルコアを用いた結果です。この差は最も小さなMPUタスク数で最大になっています。これは、配列が如何にローカルキャッシュメモリー効率に良くマッチしているかを示しています。
| Number of MPI Tasks | 8 | 16 | 32 | 64 |
| GM4 (QC -fast) | 1387 | 742 | 434 | 302 |
| GM4 (QC -fast) with MPI enhancement | 1389 | 723 | 393 | 279 |
| Improvement over GM4 baseline % | -0.14 | 2.56 | 9.44 | 7.61 |
表12は、最適化レベル-fastを用いたクアッドコア上の値を示しています。MPIタスク数が低いと改善が小さいのは、通信回数が少ないためです。
| Number of MPI Tasks | 8 | 16 | 32 | 64 |
| GM4 (QC -O3) | 1485 | 783 | 449 | 334 |
| GM4 (QC -fast) MPI enhancement | 1389 | 723 | 393 | 279 |
| Improvement over GM4 baseline % | 6.46 | 7.66 | 12.47 | 16.47 |
全体の改善は単純な加算でなく、構造的な修正の各々が最適化により影響を受けた結果です。
8 全体の結論
コンパイラ最適化オプションとコードの構造の修正により、シリアル実行部分の性能が改善されました。全実行時間は削減しましたが、スケール性能は悪化しています
PE間の通信コード部分を更新により、全てのPE数に対して実行時間は減少しました。これにより全実行時間の削減と64MPIタスクのスケール性能は改善しました。
デュアルコアからクアッドコアへシステムが変更になったため、更なる最適化が必要となりました。ノード当たり4コアの場合と1コアの場合の比較から、メモリー効率の改善のための更なる修正が必要であることが解りました。
CrayPATにより高コスト計算部分を解析しました。コード開発者によるこれらのセクションの解析により、その負荷を低減するために、新たな手法で置き換える可能性が見出されました。
9 今後の作業計画
当プロジェクトは改良版コードの利点を明らかにし、ファイル操作の改良手法を示しました。また、もしOpenMPを利用可能ならばマルチコアプロセッサで性能向上が見込まれることも明らかになりました。コードはOpenMPのみで実行されており、OMP指示行はTOMCATのMPIバージョンにも存在するので、直截的に実装すれば、クアッドコアのHECToR上で性能向上が見込まれます。OpenMPを利用したコード量に比例して性能は改善されるでしょう。
例えば、ノード当たり1MPIタスクの場合は、4タスクの場合よりも8GBメモリーを共有することで性能は向上するでしょう。そこでは追加で3つのOpenMPスレッドを生成することが出来ます。この状況は、本質的にシリアル実行であるコード部分が在るため、並列実行可能な割合で改善は制約される事になります。ノード当たり1MPIタスクの改善は、全体の実行時間の改善につながります。これとOpenMP実装を組み合わせれば、飽和コア上のMPIのみの実行の場合よりも性能は向上すると見込めます。
また、通信ボトルネックは32PEで明確になります。本プロジェクトで行われた様々な修正により、このボトルネックによる影響は64PEへシフトしました。ハイブリッド実装によりこの状況は改善し、ノード内マルチスレッド化により、以前には不可能だった128コアまで全実行時間を削減するでしょう。64PEとシングルコア演算の修正を基にすれば、ハイブリッド並列コードは256Pまで性能を向上させる可能性があります。
こうしたTOMCAT/GLOMAPへのハイブリッド並列実装は、第2のプロジェクトの一部として行う予定です。
10 将来的な方向性について
計画されたプロジェクト外の改善として、下記に記したユーザビリティとスケーラビリティの改善を行うべきでしょう:
- 実行方法をHECToRの管理形式に合わせて、シリアル実行プロセスを並列ジョブから分離すべきです。
- 参照ファイル入力方法をMPI-IOへ変更すべきです。初期化と終了処理は実行時間が短くなるにつれて無視できなくなり、現状において1時間の実行では、これらの割合は全体時間の1/30(約3%)になります。
- グローバルデータのブロードキャスト数の削減。このためにはMPE_BCASTを用いる全てのサブルーチンの検証が必要です。プロファイルからは、ブロードキャスト・ルーチンはそれほど多くの時間が掛かって居ませんが、"待ち時間"による負荷分散が存在する事が示されています。
- メモリーの削減:これは主にファイル操作のマスターI/Oモデルが要因です。これは適切な並列I/O手法を用いれば可能です。
- MPIデータ構造と、計算領域の離散化のより良い活用。本プロジェクトの半分は、並列効率向上のためのMPIデータ構造の解析に費やしました。全セクションの解析は完了していないため、性能改善余地があります。
- 新たなコンパイラが利用可能になったら、コンパイルオプションとコンパイラーバージョンの見直しをすべきです。一般的にコンパイラーがバージョンアップされれば性能は向上するのが常です。
- Cray X2の64CPUの再調査は、XT4へもよい影響を与えます。異なるコンパイラとマシンを用いる調査は、コードの不整合性の解析に役立つ手法です。
- 改善の対象となるシリアル実行部分が多く存在します。特に、インライン展開が多くの箇所で有効です。