
Lucian Anton, Numerical Algorithms Group Ltd
September 14, 2011
概要
DSTARは、、渦ダイナミクス、エントレインメント、ミキシング、乱流、蒸発液滴の間に存在する複雑な相互作用を持つ多相反応流をシミュレートします。巨視的な乱流の振る舞いや熱力学的特性は、その支配方程式の直接数値シミュレーションで得ることができます。本プロジェクトの作業は、並列スケーラビリティ、シリアル実行性能の向上および大規模データの効率的な入出力により、DSTARがより大きな領域とより長時間の物理現象をシミュレートできるようにすることです。
目次
1. イントロダクション
1.1 プロジェクト概要
DSTARのスケーラビリティとユーザビリティ改善のために以下の作業項目と目標を、6人月のプロジェクトとして設定されました:
WP1: 2D領域分割アルゴリズムの実装
目標: 並列効率80%で少なくとも10,000コアまでスケールさせること。
(a) 新しい領域分割のために元のデータ構造を変換する。
(b) コアの流体ソルバーを更新し、基本的な検証データを実行する。
(c) 残りのマルチフィジクスモジュールを更新する。
(d) 新しいDSTARのベンチマークを実施する。
WP2: 許容サイズのデータに対するI/O改善
目標: 少なくとも500サイズの立方体グリッドを効率的に取り扱えること。
(a) 大規模データデットのチェックポイント処理と統計処理をリファクタリングする。
(b) 並列I/OとしてMPI-IOを用いて改善する。
(c) ログファイル処理の改善。
(d) 2DECOMP&FFT共通IOルーチンの移植。ただし有用と判断された場合に限る。
WP3: コードのリファクタリング。この多くはWP1で更新されたコードで行う。残りのルーチン、特に”ユーザルーチン”は、DSTAR利用者がFortran95に変更する。いくつかの旧式のライブラリルーチンは、大きな性能問題がない限りそのままF77に据え置く。
目標: 全てのユーザルーチンが現代的なコードへ変換されること。
WP4: 普及
目標: 全てのユーザルーチンが現代的なコードへ変換され、そのドキュメントが作成されること。
1.2 作業概要
DSTARによる新たな物理領域のシミュレーションという観点から、本プロジェクトの主要な作業は文献[2]の2DECOMP&FFTライブラリにより2次元領域分割を実装することとしました。この作業の多くは、ローカルなグリッド配列を保存するのにローカル配列を確保し、様々なサブルーチンを2D領域分割へ適用することでした。詳細はセクション3,5で示します。
新しいコードは18,432までのMPIタスクを用いてテストされ、約50%の並列効率を示しましたが、WP1の80%には達しませんでした。元の目標は他の流体物理コードのスケーラビリティから用意した値です。しかしながら、この目標が設定された時点では、DSTARが多成分性を持つことが見落とされていました。多成分であることから、2次元領域分割間で極めて多量のデータ通信が発生し、他の流体モデルに比較して効率が減少します。
大きなMPIタスク数において実行時間中の50%が通信に消費されるため、我々はさらにこの問題を追及しました。そこでわかったことは、混合(ハイブリッド並列)モードで計算と通信をオーバーラップさせるアルゴリズム(セクション3および文献[3])のほうが極めて良いスケーラビリティを達成できることです。ですがこれはソースコードの複雑性が増しコストがかかります。
入出力処理はマルチファイルアクセスから単一ファイルアクセスパターンへ変更されました。これは、元の出力処理がHECToRの並列ファイルシステム上に膨大な数の小さなファイルを用いて、きわめて非効率的だったものを置き換えます。この新しいバージョンでは、リスタートファイル(バイナリーデータ)はMPI-IOで処理されますが、セクション4で見るように、FortranのバイナリーファイルIOも十分効率的であることも判明しました。リスタートファイルに加えて、物理量に関するモニタリングポイントに対する別のIOも存在します。このデータは現在一つのアスキーファイルへ集められ、専用のMPIプロセスで処理されます。可視化のためのモニタリングポイントから個別のファイルへのデータのソート用に補助プログラムを作成しました。ログ処理は同じIOモデルへ修正されました。詳細はセクション4,5に示します。
コードの現代化は二種のやり方で行われました: i)静的配列のallocatable配列化、これはより大きなグリッドサイズを可能にし、任意のグリッドサイズに対して一つの実行形式を用いることができます;ii) Fortran77サブルーチンをその目的に従ってモジュール化する。この変換はコード構造を明確にします。これはエラーの位置把握にも役立ち、トップレベルのサブルーチンをより簡潔に書くことに役立ちます。データ構造のより良い制御のために、暗黙のデータ型をソースファイルのほとんどにおいて明確に宣言するようにしました。流体ソルバーのいくつかのサブルーチンに対する最適化も行い、コアのソルバーは約20%性能向上しました。詳細はセクション5に示します。
2. コードの概要
DSTARは、Kai Luo教授の乱流と燃焼の直接数値シミュレーション研究チームにより開発され、20年に渡り利用されています。メンバーには、Neil Sandham教授およびZhiwei Hu博士 (University of Southampton)、Xi Jiang教授(University of Lancaster)、Eldad Avital博士(Queen Mary, University of London)、Yongman Chung博士(University of Warwick)およびJun Xia博士(Brunel University)が含まれています。
DSTARの数学的フレームである偏微分方程式系とその解法の数値アルゴリズムは、文献[1]で詳細に記述されています。要約すれば、内部、境界近傍、境界に対してそれぞれ、6次、4次、3次の空間離散化を用いた陰的コンパクト有限差分スキームです。液滴位置での気体特性を得るのに、4次のラグランジュ補間スキームを用います。流れ変数の進行には3次のルンゲ-クッタスキームを用い、液滴のマーチングには数値的な正確性、安定性、効率性を考慮した半解析的スキームを用います。
プロジェクト開始前のDSTARは、y軸に沿って一様にMPIランクで分割されたカルテシアン・グリッド(1D領域分割)を用いた並列計算を用いていました。空間微分は陰的に計算されるため、各MPIランクはy軸上の全領域に渡るグリッドが必要となり、z軸に沿った追加の領域分割も必要でした。2つのパーティション間で、すべてのMPIランクを用いた転置操作によるデータ交換が生じます(図1aを参照してください)。
DSTARの数値計算負荷は、典型的な実行において実行時間の90%以上を占めます。これは微分方程式系の右辺(RHS)の計算を行うサブルーチン内に集中しています。この方程式系は連続の方程式の空間離散化後の流れ変数の時間発展を記述します。これらサブルーチンでのRHS計算は、流れ変数と、領域内と境界における微分値の更新のためのメインループを持ちます。さらに、空間微分計算のサブルーチン呼び出しと、先述の転置操作のための通信サブルーチンの呼び出しも含まれます。
このセクションのコードは、更新ルールの局所性と離散化された流れ変数の多成分性により大きな並列化の自由度を持ち合わせています。一方、次元Nx、Ny、Nzを持つ全体のグリッドに対して、1D領域分割で用いることができるプロセッサ数はmin(Ny,Nz)に制限されます。これは現代的なスーパーコンピュータで利用可能なプロセッサ・エレメント数に比べ遥かに小さな値です。
モニタリングとチェックポイント用のデータファイルの入出力にはFortran IOが用いられ、モニタリングデータは観測点に1つのASCIIテキストファイルとして集約され、リスタートデータはMPIタスクのサブグループに対応するバイナリーファイルへ集約されていました。
ソースコードファイルにはFortran77のファイルが大量に含まれ、その多くは暗黙の型宣言が用いられていました。グリッド次元数とMPIランク数はインクルードファイルで直接記述されており、こうしたパラメータを変更する場合には再度コンパイルが必要でした。
3. 2D領域分割
図1は全体グリッドの1次元および2次元領域分割の違いを示しています。
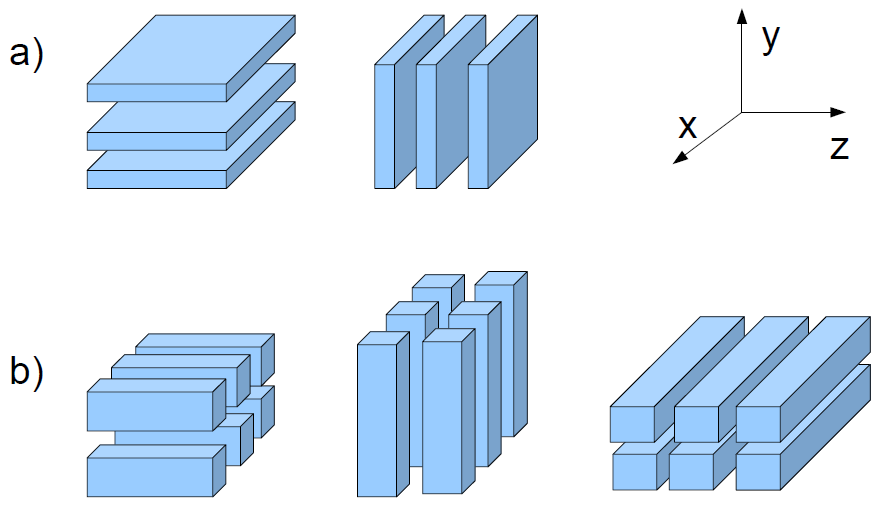
図1: DSTARの領域分割の概要:a)z、y方向の3MPIタスクを用いた1D分割、b)z、y、x方向の3×2MPIタスクを用いた2D分割。このケースではx軸に沿った転置が必要。領域間のデータ交換にはall-to-all型の通信が必要。
2D領域分割は追加列数分MPIタスク数を増やしますが、空間微分は陰的に計算されるため、x軸に沿った追加の転置操作が必要です。それでも大規模グリッドを用い、かつ高速通信ネットワークがあるならば、この手法はスケーラブルです。
2D領域分割の実装は、2DECOMPライブラリ[2]を用いれば直截的です。元のコードにおけるy⇔z転置に用いられるサブルーチン呼び出しを、対応する2DECOMPライブラリのtranspose_y_zサブルーチンへ置き換えます。xに関する微分には、y⇔x転置が必要で、微分値計算サブルーチンは必要に応じて転置操作を実行するように拡張されます(ローカルなグリッド次元から決定されます)。1D分割を用いる可能性も残します。この場合は初期バージョンの性能を確認するためにy⇔x転置をスキップします。
2D分割アルゴリズムのスケーラビリティは、18423MPIタスクまでを用いた768と1536サイズの立方体グリッドで確認しました。プロセッサグリッド内のプロセッサ列数は、y⇔x転置のデータ移動をノード内か2ノード間に制限するために24か48に設定しました。
図2は、典型的な実行において計算時間の90%以上を占めるコアソルバー・サブルーチン(RHS)のグリッド点あたりの計算時間(7633サイズに規格化しています)を示しています。
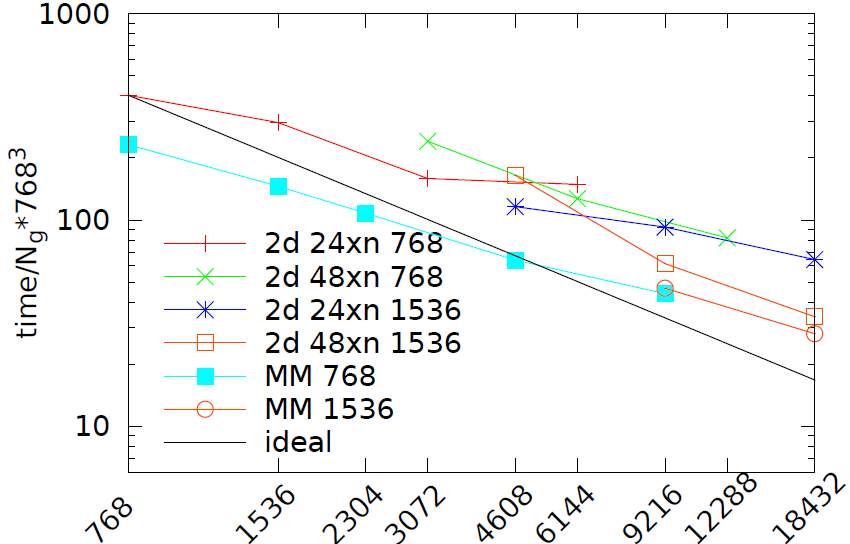
図2:2D領域分割でのMPIランク総数に対するコアソルバーサブルーチン(RHS)の性能。ここで768と1536サイズの立方体グリッドに24と48プロセッサ列を用いた。MPIランクの増加に従い両方のグリッドでの性能は交差している。1D領域分割の混合モード(MM)コードによる各グリッドで768と1536MPIタスクによる性能も示した。ここではOpenMPスレッド数を増やしている。
そのプロット線は、48プロセッサ列を用いた1563グリッドサイズで、2D分割が18432MPIタスクまで約50%の効率でスケールしていることを示しています。ここで性能が交差するという興味深い現象が生じています。24プロセッサ列の2D分割は小さなコア数(7633グリッドの3072MPIタスク、および15363グリッドの4608MPIタスク)ではより良好ですが、48プロセッサ列を用いた分割は両方のグリッドサイズにおいて大きなMPIタスク数でより良好です(この他にプロセッサ列数を変えてみましたが極めて低い性能になりました)。
これは大規模マルチコアノードを持つ並列計算機では逃れられない現象で、別のアルゴリズムでスケーラビリティを向上させることができます:それは元の1D分割を用いて、各ローカルグリッドでOpenMPスレッドを用いて計算速度を向上させる方法です。
スケーラビリティの確認をしつつ、このアルゴリズムのプロトタイプ実装を行いました。本作業の内容はCrayユーザグループコンファレンス2011[3]で発表されています。結論として、1D分割の混合モードはより複雑な2D分割よりも少なくとも20%高速で、図2で示されるようにOpenMPを用いて計算と通信のオーバーラップを行えば良好な結果を得ることが可能です(これが必要なのは、現状のMPIがノンブロッキング送受信のための計算・通信オーバーラップをサポートしていないからです)。
4. 入出力操作の最適化
DSTARは2つの主要なIOを持ちます。それはi)シミュレーション領域内の選択された様々なモニタリングポイントから物理量を収集する、およびii)計算リスタートに必要なチェックポイントデータです。
元のコードでは、モニタリングデータは各観測点に一つのASCIIテキストファイルに収集されます。れは並列ファイルシステム上で数百から数千の個別ファイルにアクセスすることになります。
リスタートデータはMPIタスクのサブグループによりバイナリー形式で書き込まれます。そのサブグループでは関連するMPIタスクからデータを集め、それらは順番にディスクに書き込まれます。つまりデータがファイルに書き込まれたらすぐに、関連するランクからデータを受け取って続けて書き込まれます。このやり方はバッファメモリーを節約しますが、他の関連するランクをブロックしています。データのレイアウトは計算で用いられるランクに依存するため、計算の構成を変更する柔軟性が乏しいやり方です。
このようなIO操作は特にASCIIテキストファイルに対しては、MPIランク数が1,000から10,000になる場合にはスケーラビリティを悪化させます。1,000MPIランク以上を用いる場合にスケーラブルなIOを保つために、元のIOを以下のように変更しました:
- モニタリングポイントのデータを、指定されたランクで収集して一つのテキストファイルへ出力する。このファイルを可視化アプリケーションのフォーマットで個別のファイルへ分割するポスト処理ユーティリティプログラムを作成した。ポータビリティのために(ポスト処理がローカルマシンでも実行可能なように)、ASCIIテキストファイルとして保存する。この出力時間は実行時間に比べて大きくはないが、もし削減したいのであればバイナリーファイルへ切り替えることが可能。
- リスタートファイルのIOは、MPI-IOで1つのファイルに出力するようにした。この方法の長所は、データが全体グリッドの順序で保存されることで、同じリスタートファイルを用いて異なるグリッド分割の実行が可能になることである。
IOに関連して、ログ処理も複数ファイルアクセスを止めるように変更しました。新しいバージョンでは、MPI-IOの共有ファイルポインタを用いて全MPIタスクが1つのファイルへログメッセージを書き込みます。デバッグ目的のために、ポスト処理プログラムに付随してグローバル配列内容のダンプを取るサブルーチンも提供されています。
| grid size | MPI tasks | code sections | |||||
| RHS | monitor | restart | |||||
| old | new | old | new | old | new | ||
| 232×384×768 | 192 | 13.3 | 10.8 | 0.22 | 0.12 | 4.3 | 23.1 |
| 7683 | 768 | 31.1 | 25.0 | 0.51 | 0.01 | 21.1 | 34.7 |
| 15363 | 18432 | - | 31.1 | - | 0.14 | 71.1 | 226.6 |
IOのベンチマークを3種のグリッドサイズで評価しました。表1の4-8列を参照してください。単一ファイルによるモニタリングデータ出力時間は明らかに改善し、リスタートファイルIOは意外にも、18,432 MPIランクを用いた約217GBのチェックポイントデータの場合でも、ノードあたり1出力のFortran IOが最も高速でした。この結果から示唆されるリスタートファイルIOのベストの戦略としては、実行パラメータ(例えば、最も効率的な2D MPIランク分割をした場合)を詳細にチューニングした場合はMPI-IOが良く、それ以外は(もしそれがより速い場合は)Fortran IOへスイッチすることです。
5. ソースコードの改善
古いFortran77ソースコードのFortran95への現代化を、文献[4]で記述されているような以下の標準的なステップを踏んで行いました。そこに含まれる作業には、すべてのcommonブロックをmodule変数へ置き換え、include文をuse文へ置き換え、implicitを削除し、静的配列をallocatable属性へ変更することなどを含みます。
Fortran77サブルーチンは機能に従ってファイルあたり一つ、Fortran95モジュール内にラップされました。新しいモジュールの詳細は以下の通りです:
- constant_and_kinds.f90: FortranとMPIに対する基本的な数学的およびコード定数、データ種別定義を含む。
- global_data.f90: ソースコード全体で用いるグローバルデータ、特定のエンティティを用いる場合は、use, global data, only : ...とする。
- commonvdrop.f90: 初期摂動データを保存する。
- basic_functions.f90: 他のモジュール間で物理特性計算に用いる数学的関数。
- plume.f90: シミュレーションのドライバルーチンを含む。つまりメインの時間ステップループと関連する手続きを制御する。
- pade_data.f90: 空間微分計算で用いるパラメータを含む。
- deriv3d_v601.f90: 流れ変数に対するx、y、z方向の微分を計算するサブルーチンを含む。
- main.f90: MPIの初期化、入力ファイルの読み込み、初期化ルーチンのモジュールからの呼び出し:これはデータのアロケーションと初期化に用いる。ドライバルーチンの呼び出し、および終結処理
- rhs3d.f90: 各グリッドポイントでの流れ変数とその微分を計算するルーチン、境界条件および時間積分で必要な熱力学関数を含む。
- record3d.f90: 計算中に観測データを収集するサブルーチンを含む。
- restart.f90: リスタートサブルーチン内で用いられるcommonブロック、MPIインターフェイス、FortranIOリスタートプログラムを含む。
- debug_tools.f90: Warningやエラーメッセージを特定のファイルにMPI-IOの共有ファイルポインタを用いて記録するのに用いられるサブルーチンを含む。
ベンチマークとプロファイリング中に、コアソルバーの幾つかのルーチンのキャッシュ効率が極端に悪いことが見つかりました。この問題はネストしたループの順序変更と、ループ内のIF文のループ外への移動により解決しました。結果としてRHSセクションの性能は約20%向上しました。表1をご覧ください。
その他のソースコードの更新や再構築を以下にまとめます:
- 幾つかの似た微分計算サブルーチンを、引数追加を行い1つのモジュールサブルーチンにまとめた。
- ソースコードを含むディレクトリを、src:ソースコード、utils:ポスト処理プログラム、decomp_2d:2DECOMPライブラリソース、の3つのディレクトリに分割した。
- 異なるコンパイラ、最適化に応じたMakefileを作成し、依存性リストを作成した。
- 変更に関するドキュメントをREADMEファイルに記載した。
新しいコードはデバッグおよび最適化フラグを用いて、PGI,GNU,Crayコンパイラでコンパイルされ、異なるMPIプロセス配置とグリッドを用いてテストされました。
6. 結論と今後
DSTARのアップグレード版は、以前のバージョンに比べて50倍のMPIタスクとグリッドサイズを用いることが可能になりました。シリアル実行性能は約20%向上し、2D領域分割の並列効率は約50%に改善されました。
大規模並列性とシリアル実行性能の両面は、DSTARによる新しい物理領域の探索に極めて重要です。なぜなら時間ステップが化学的なミクロな時間スケールで決まり、流れの特性がマクロな形状とより長い時間スケールで決定されるためです。
モニタリングデータとデバッグやログメッセージは単一ファイルに書き出されます。リスタートファイル入出力のMPI-IOバージョンは柔軟性の高いものですが、より高性能なFortranバイナリーバージョンも可能です。
ソースコードはFortran90モジュールに置き換えられ、コード全体が明瞭な構造になりました。この結果、プログラミングエラーはより早く解決可能になり、トップレベルからよりシンプルなコードを記述できます。ユーザビリティ改善例としては、データ配列の動的メモリーアロケーションの導入により、異なるグリッドサイズに対して同じ実行形式を用いることが可能になりました。
DSTARチューニング作業の中で、さらに性能とユーザビリティの改善が可能であることがわかりました。以前に述べたように、2D領域分割内の通信は実行時間の約50%を占めています。簡単な作業から、これは混合モードプログラミングによる計算と通信のオーバーラップを用いれば大きく改善できることが示されました。このコンセプトはIOにも応用でき、IOを実行するノードのサブセットを用い、同時に他のノードは計算を実行することで改善が可能でした。
ユーザビリティの観点からは、以下の点が今後考えられます:i)物理パラメータ、計算パラメータ、データ収集パラメータの3つのブロック情報から成る入力データの構造化、ii)入力パラメータとポスト処理に関するより解り易いドキュメント化、iii)新たなコードの検証のためのMakefileのタスクとしてアクセス可能な拡張テストモジュール、iv)2DECOMPライブラリのIO関数によるデータ収集の改善。
謝辞
このプロジェクトは、nAG Ltd.が運営するHECToRの分散計算科学および工学(CSE)サービスの基に実行されました。英国の国立スーパーコンピューティング・サービスである、HECToR:英国リサーチ・カウンシル・ハイエンド計算サービスは、リサーチ・カウンシルを代行するEPSRCが管理しています。そのミッションは英国学術界の科学および工学の研究支援です。HECToRスーパーコンピューターは、UoE HPCx Ltd.およびnAG Ltd.のCSEサポートサービスにより管理運営されています。
文献
| [1] | J. Xia and K. H. Luo, Conditional statistics of inert droplet effects on turbulent combustion in reacting mixing layers, Combustion Theory and Modelling, 13:5, 901?920 (2009), and the references therein. |
| [2] | http://www.2decomp.org/, see also N. Li and S. Laizet, 2DECOMP&FFT ? A highly scalable 2D decomposition library and FFT interface, Cray User Group 2010 conference, Edinburgh, UK; http://www.hector.ac.uk/cse/distributedcse/reports/incompact3d/incompact3d/index.html. |
| [3] | L. Anton, N. Li and K. .H. Luo, A study of scalability performance for hybrid mode computation and asynchronous MPI transpose operation in DSTAR Cray User Group 2011 conference, Fairbanks, USA. |
| [4] | D. Rouson, J. Xia and X. Xu, Scientific Software Design: The Object Oriented Way, Cambridge University Press, 2011. |