
Ian Bush,
Numerical Algorithms Group Ltd.
Ilian Todorov and William Smith,
STFC Daresbury Laboratory, Daresbury Science & Innovation Campus
概要
HPC規模が増大するにつれて、アプリケーションの利用拡大を阻害するのは並列効率のみでなく、I/Oがボトルネックとなることが多くあります。これは分散データアルゴリズムにおいては特に当てはまります。本レポートでは、分子動力学アプリケーションDL_POLY3における分散データのI/O最適化方法について報告します。特に、通信の大きな増大を招くことなくより多くのプロセッサーへスケールする、I/Oサブシステムを最も効率よく利用可能な分散データ再配置を示します。
キーワード:分子動力学、領域分割、性能、並列I/O、DL_POLY_3、netCDF
1.イントロダクション
DL_POLY_3[1]はSTFC Daresbury LaboratoryのI.T.TodorovおよびW.Smithにより開発された、一般用途向け古典分子動力学(MD)シミュレーションパッケージです。このソフトウェアの主たる目標は、マルチプロセッサー・システムで大規模MDシミュレーションを可能にすることです。これはFortran95標準に従う(nAGWare95[2]およびFORCHECK95[3]でチェックされています)厳格かつ保守的なスタイルを持ち、優れたポータビリティーが保証されています。その並列化は均等な空間領域分割をベースにしており、優れた負荷分散が保証され、系の粒子密度である全メモリーの分散は空間全域で均一になっています[1]。この並列手法は、そのほとんどが1対1通信で、グローバルなものは少数のみとなっており、優れたスケーラビリティーを示します。
しかしながら実際のMD実行において、コードにおけるCPU依存の優れたスケーリングは全体の一部分にすぎず、計算結果の保存や初期状態設定の入力も必要です。MDが時間ステップを踏むに合わせて決まった周期で出力処理をしなくてはならず、典型的な計算においては100‾1000時間ステップ毎に実行されます。[4]や[5]で議論されているように、特にプロセッサー数が増加した大規模問題サイズの場合に、こうした入力処理や特にデータの出力処理がボトルネックになって来ました。
本レポートに記載された作業はIan Bushによって実施され、2010年5月24-27日にエジンバラで開催されたCrayユーザーグループ会においても発表されています。本レポートの内容は以下のように構成されています:次のセクションでは、解くべき問題と、DL_POLY_3で以前に使用されていた手法およびその概要をより詳細に示します。セクション3では、バージョン3.10でリリースされる出力の新しい方法を説明し、以前の実装と性能を比較します。セクション4では次のコードリリース版に搭載される新しい並列入力法を説明して、元の方法論との性能比較を示します。セクション5では、netCDF[7]を基にした最新の開発状況を述べ、I/Oの改善がどのように全体のスケーリング性能に効いているかを議論します。
2.領域分割MDのI/O
DL_POLY_3の主な入出力は、多くの伝統的なMDと同様に、モデル系の構造の時間発展の入力と出力です。これらは簡単に言えば系の粒子の座標と、場合によりその粒子の速度と粒子に働く力を含むリストです。DL_POLY_3では伝統的に、そのポータビリティーのためにフォーマットI/Oを用いてきました。MDそれ自身はHPC環境や通常のクラスター上で実行されますが、結果の解析にはユーザー自身の環境のワークステーションが用いられることが多いためです。出力は次のような行で、
Na+ 1 -184.5476802 -167.5198486 -185.5358832 -2.881253622 -4.727721670 2.235042811 -10840.17697 -5695.571326 -2740.726482
これが多数繰り返されます。ここで、上述の4行の意味は、原子種、座標、速度、原子に働く力です。一見単純に見えますが、領域分割においては複雑化の主たる要因になります:並列MD実行においては、元々の原子の並び順序が入れ替わり、さらに原子は領域を跨って移動します。よって、2番目に入力された原子がプロセッサー0にある場合、実行が進むにつれて、他のプロセッサーに割当てられた空間領域を動いていくことになります。結果として計算開始時にn番目に入力された粒子は、計算終了時にはもはや出力ファイル内の入力と同じ位置に書き込まれることはないでしょう。これはグリッド上で微分方程式を解く方法と比較すると対照的です。これらの手法は共に空間を領域分割しますが、格子法では実行中に空間グリッドは固定されているためこのような混乱は生じません。
勿論MDではこれが問題になることはなく、入力や出力における原子の番号がシミュレーション中に変化することはありません。しかしながら多くの後処理ソフトウェアツールはその操作に出力ファイル内の原子の順序を用います。その一例しては、実行中の原子位置の時間発展を表示するソフトウェアがあります。このようなソフトウェアはフレームを跨り原子を追跡せねばならず、通常は出力ファイル内の原子の位置が固定されていることが仮定されています。
つまりユーザーにとって、原子の位置が決まっていることは極めて都合が良いものです。他方、並列に動作するアプリケーションにとってはこのことは極めて都合が悪いです。つまり座標を出力する度にデータの並べ替えが発生することを意味し、こうした動作は分散データにとっては高価なものになります。やり方としては以下の2つの方法の内の一つ、あるいはその組合せがあります:
- CPUが互いに通信し合ってデータの順序を記憶するようにする。
- ローカルデータを用いて、各CPUはファイルのどこに原子が記録されるべきかを特定する。
これまでDL_POLY_3では上述の2番目を採用してきました。これは出力ファイルが正則なフォーマットであれば、FortranのダイレクトアクセスI/O機能で比較的簡単に実装可能です。これは[6]においてより詳しく報告されています。これら2つの手法が実装されて試験されています。
- SWRITE:各プロセッサーはデータをプロセッサー0へ送信し、プロセッサー0はダイレクトアクセスファイルで全てのI/O処理を行う。
- PWRITE:各プロセッサーはローカルデータをダイレクトアクセスファイルへ適切に記録する。
[7]で記述されているように、これらは共に欠点を持ちます。SWRITEの場合、明らかにスケールしないのみならず、単一プロセッサーでは最新のファイルシステムのバンド幅を飽和させることは困難です。他方、PWRITEはプロセッサー数に対してスケールするでしょうが、特に大規模なプロセッサーシステムの場合にはディスクのバンド幅に競合を引き起こすでしょう。PWRITEでの欠点はこれだけではありません。Fortran標準はシリアルコードの振る舞いを記述するものです。よって複数プロセスが一つのダイレクトアクセスファイルにアクセスしたときの振る舞いはきちんと定義されていません。実際にPWRITEを用いた場合に、Cray XT3/4上でのLustreファイルシステムでは、ファイルに疑似的なヌルキャラクターを導入しなくてはなりませんでした。この問題はディスクとキャッシュのコヒーレンス性が主たる要因です。
ポータビリティーに加えてPWRITE法の性能はコード全体のスケール性能を向上させるには、[8]に記述されている通り十分なものではありません。[7]以降、ポータブルでスケール性の可能性を持つ2つの手法MWRITEおよびMWRITE_SORTEDが開発されており、これらが本レポートの主な焦点となります。
しかしながら大規模系においては更に2つの問題が生じます。読み込みは1回ですが出力は実行中に周期的に実行されるため、入力より出力が重要となりますが、大規模な問題サイズや大規模プロセッサー数の場合は初期座標入力のコストが増加してきます。さらに大規模系ではフォーマット付き入出力ファイルが極めて大きなものになります。これらの点についても、開発した並列入力方式を説明します。メインのI/OルーチンのnetCDF[9]バージョンの実装は極最近に完了しました。
3.構造情報の出力
PWRITEのポータビリティー問題の解決策の一つがMPI-IOを使うことです。もしFortranダイレクトアクセスのフォーマットを保ちたいのであれば、ここで述べるケースが後方互換かつ特に簡単な方法です。この場合は各レコードは同じ長さを持ちます。1レコードは適切なサイズのキャラクター配列で構成されるMPI型に当てはめることが出来ます。この時、基本のデータ型を設定するMPI_FILE_SET_VIEWを用いて、ファイルに対してこのデータ型を用いるようにします。結果的にファイル中の全てのオフセットはこの型のサイズを単位に計算されます。下記事項に注意すれば、Fortranダイレクトアクセス書き込みとしてMPI_FILE_WRITE_ATを正確に用いることが出来ます。
- プログラムはデータをそのキャラクター表現へ変換しなくてはなりません。例えば浮動小数点数値はフォーマット付き出力をした時と同じ数値表現のストリングへ変換される必要があります。Fortranではこれは内部出力を使えば極めて簡単です。
- レコード番号が1からでなく、0から始まる。
著者らはこのアイデアを教えてくれたCrayのDavid Tanquerayに感謝します。彼は親切にも、我々がMWRITEと呼ぶ実装を提供し、DL_POLY_3バージョン3.09までこれはデフォルトの出力方式となりました。
MWRITEはポータブルな方法です。しかしながら[8]と[10]で記述されたように、その性能は全コードの性能が良好にスケールするほどには十分ではありませんでした。その理由は2つあります:
- 各I/Oトランザクションはたった1つの原子データのみであり、大変小さい(292バイト)
- 全プロセッサーを用いた場合、ディスクで書込みの競合が発生し、性能は劣化する、
これらの問題に対処するためにMWRITE_SORTEDを開発しました。初期のプロトタイプでは多くの機能が欠けていることが[11]で議論されました。ここではリリースされた全実装を議論します。背景にあるアイデアは2つに分けられます:
- ディスク競合を避けるためにデータは実行時にプロセッサーのサブセットに集められます。その時これらのI/O用プロセッサーは待ち合わせをします。
- 出力の前にこれらプロセッサー間でデータはソートされ、元々の順序へ並び替えさせられます。データが正しい順序になったら、データは直ちに出力されます。つまりここで大規模なトランザクションを実行してより良好なI/O性能を引き出します。
この2つのステージの後にMPI_I/Oにより出力が実行されます。
大きなメモリーオーバーヘッドを避けるためにデータ収集はバッチで処理します。例えば$P_{I/O}$個のプロセッサーを使ったN粒子径シミュレーションを考えましょう。I/Oプロセッサーへ全てのデータを集めることは困難ですが、そうではなく最初に、最初の$P_{I/O}*N_B$個の原子に相当するデータをI/Oプロセッサーへ集め、原子が満遍なく分散された時点で書出します。ここで$N_B$は選択パラメータとしてのバッチサイズです。そして次の$P_{I/O}*N_B$個の原子が集められて出力され、これを全てのデータが書出されるまで続けます。これは単純な作業で、与えられたコア上でバッチ内のメンバーを特定して、元々の昇順に原子をソートすることで可能です。$N_B$は2つの競争的条件下で選択されます:
- 収集時のメッセージ通信とデータ書き込みが効率的となるように、十分に大きくとるべきである。
- I/Oプロセッサー上のメモリーオーバーヘッドが許容できる程度に小さくするべきである。
コード内でのI/OプロセッサーのランクはMPI_COMM_WORLD全体に均等に拡散します。多くのシステムでは、最初のn個のランクのコアは最初のn-wayマルチコアプロセッサー上に配置され、次のn個は次のプロセッサーへと順番に配置されています。もしコア単位でなくノード単位でメモリーオーバーヘッドが発生するなら、より大きなメモリーが利用可能であるとして大きめのバッチサイズを選ぶことが出来ます。しかしながら、MPIではコアが同一プロセッサー内かそうでないかを見分けるポータブルな方法が存在しないため、この方法はそうした配置であることを保証できません。この方法は十分なメモリーの存在を仮定しますが、ディスクへのデータ書き込みをうまくやり遂げます。MWRITE_SORTEDは現状は実装が完了し、DL_POLY_3バージョン3.10のデフォルト出力方式としてリリースされました。
図1は、HECToRフェーズ2aの、Cray XT4、2.3GHzクアッドコアAMD OpteronプロセッサーおよびLustreファイルシステム[12,13]上でのDL_POLY_3バージョン3.09と3.10の性能を比較したものです。各ケースは5回の実行の内の最高性能を選びました。
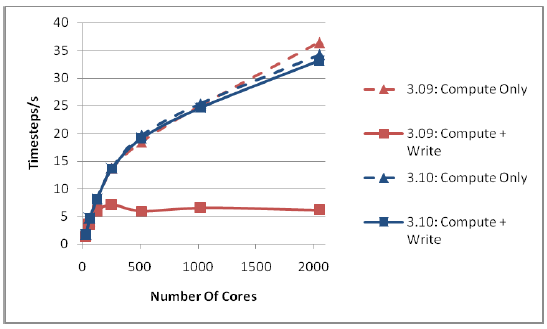
図1 : 216,000イオン系での出力性能
実行対象は216,000個の塩化ナトリウム(NaCl)です。1000時間ステップ実行し、座標はジョブの最後に一度出力されます。これは多くの研究グループが実施した系のサイズの代表として選ばれました。
compute onlyの曲線からはバージョン間で微小な差はありますが良くスケールしていることが見て取れます。計算部は2つのバージョン間で小さな変更が施されましたが、その差は想定内でした。しかしながら、最後の構造出力を含めて見てみると、2つのバージョン間でスケール性能は極めて異なります。バージョン3.09は128コアまではスケールしていますが、それ以降は計算部がスケールするのに対し、I/Oが性能を劣化させています。I/Oを含めた3.10の性能は、今回用いたプロセッサー数においては性能劣化は認められず、新しいMWRITE_SORTEDが性能を高く向上させていることが解ります。
上記においては、Lustreファイルシステムに影響する環境変数は、両方のコードで共にデフォルトに設定したままにしています。I/O性能のチューニング方法を気にせず、デフォルトで実行できることは、ユーザーにとって重要な利点です。
コードに対する設定は、それがHECToRや初期のHPCxシステム[14]上での性能に如何に影響を与えるかについて試験した後に、デフォルトが設定されました。出力の設定は経験的に以下のものが妥当と判断しました
- 8$P^{1/2}$個のI/Oプロセッサー、ここで$P$はコア総数
- 1バッチは50,000原子
- I/Oトランザクション当り5,000原子データ出力
最後の設定は数値データのキャラクター表現への変換に必要なものです。繰り返しますが、数が大きいほうがI/O性能は良好ですが、その程度はメモリーオーバーヘッドで制限されます。無論、種々のバッファを用いて自動的に最適化されるのが一番良いですが、現状本レポート作成時のCray XT4では実装されているアロケーション機構ではこれは難しく、未使用メモリーがどのくらいあるかに検討をつけるのが困難です。
より一般的なテストとして、[15]の34 DL_POLY_3テストケースで試したところ、HECToRの256コアで、3.10の出力は3.09より平均で50倍高速であることが示されました。
表1はDL_POLY_3の2つのバージョンの実行的I/O性能を示しています。性能評価に用いた時間は、全てのメッセージ通信とこの方法に関する計算を含みます。このため実効的という言葉を使いました。これを選んだのはディスクアクセス時間だけでなく、MDを利用するユーザーや開発者が興味を持つものだからです。
| 3.09 | 3.10 | 3.09 | 3.10 | ||
| Cores | I/O Procs | Time/s | Time/s | Mbyte/s | Mbyte/s |
| 32 | 32 | 143.30 | 1.27 | 0.44 | 49.78 |
| 64 | 64 | 48.99 | 0.49 | 1.29 | 128.46 |
| 128 | 128 | 39.59 | 0.53 | 1.59 | 118.11 |
| 256 | 128 | 68.08 | 0.43 | 0.93 | 147.71 |
| 512 | 256 | 113.97 | 1.33 | 0.55 | 47.60 |
| 1024 | 256 | 112.79 | 1.20 | 0.56 | 52.47 |
| 2048 | 512 | 135.97 | 0.95 | 0.46 | 66.39 |
これらの値は、各ケースについて複数実行した結果の最高性能を記しており、データには多少の揺れはあります。この表の結果から多くのことが解ります。最も重要なことは、バージョン3.10のMWRITE_SORTEDがMWRITEと比較して極めて高い性能を持つことです。コードのデフォルト設定も256コアにおいて最高性能となっています。これがこのケースにおける図1で示されたように計算部がほとんど線形にスケールする点であり、ユーザに計算予算内で最も効率的な利用が勧められるコア数となっています。より大きなコア数における性能劣化は、図1で示された通りコード上の影響が極僅かなため、問題ではありません。
さらにMWRITE_SORTEDが、大規模プロセッサーシステムにおける大規模物理系が許容できるシステムサイズで、十分にスケールするかどうかもテストしました。これを図2に示しました。再びNaClを例にして、サイズは1,728,000イオンとしました。同様にデフォルト設定で、1000時間ステップ実行して構造を一回出力しました。I/Oを含む実行は1000コア以上に対して良好なスケール性能を示しています。出力のピーク性能も810MB/sとなり、小規模ケースの場合よりも優れていることが解ります。バージョン3.09では実行時間が非現実的であるため、この系では実行はしていません。
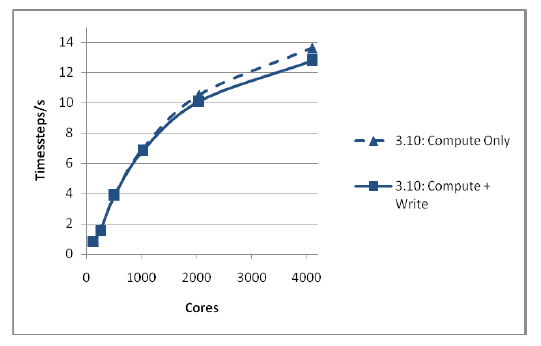
図2 : 1,728,000イオン系での出力性能
この大規模系はDL_POLY_3のnfoldオプションを用いて生成されました。これはシステムを各格子ベクトルに平行方向にスケールするもので、この場合はx,y,z方向の各々に対して2倍されています。これは行うには新たな構造を出力しなくてはなりません。MWRITE_SORTEDによるバージョン3.10はこの操作を256コアを用いて1.5秒で完了しました。MWRITEを使用するバージョン3.09では約1時間必要でした。
4.構造入力処理
DL_POLY_3の現行バージョン3.10は構造情報を並列で入力しません。その方法は以下の通りです:
- MPI_COMM_WORLDのランク0のコア(コア0)が原子データをバッチで読み込む
- その後コア0は該当バッチの全データを他の全プロセッサーへブロードキャストする
- プロセッサーはその領域に含まれる原子を展開する
- コア0は次のバッチを読み込み、全てのデータがファイルから読み込まれるまで、上記が繰り返される
並列入力処理は出力の場合に比べて簡単でありかつ難しいです。ソートしない場合は上述のように直截的です。しかしながらプログラマーは自身の望むフォーマットで作成する際に、DL_POLY_3のマニュアル[16]に記載された基準に従わなくてはいけません。他方読み込みに際して、ファイルはユーザーが提供するのであるから、プログラムはユーザーの都合に出来る限り柔軟に対応可能であるべきです。実際に2つの重要なケースがあります:
- DL_POLY_3が生成した入力データ。この場合フォーマットは正確にコードが決めている。
- 他の方法により作成された場合
最初のケースのほうが重要かつ取り扱いが簡便です。よって新しいコードでは、提供された入力ファイルがどちらのケースであるかを自動認識し、最初のケースであれば最適化された手法を実行し、2番目のケースであればより一般的な方法を用いるようにします。2つの方法は以下の共通のアイデアを用います:
- プロセッサーのサブセット、以前と同様にI/Oプロセッサーと呼びますが、その各々が原子データバッチを読み込む
- 各I/Oプロセッサーはバッチ内のどの原子をコアに配置するかを決定する
- I/Oプロセッサーはそのバッチを他のプロセッサーへスキャッターし、各原子は適切なコアに配置される
- I/Oプロセッサーは次のバッチを読み込み、ファイルから全てのデータが読み込まれるまで上記プロセスが繰り返される
そのフォーマットが予めわかっている場合(上記の最初のケース)に可能な最適化は、入力ファイル内の各レコード長です。これは以下のようにします。
- 各バッチをファイルのどこから始めるかを予め決める。これが解らない場合はFortranでは、各バッチが開始する場所を探すのにファイルの走査が必要となり、これはオーバーヘッドが生じることになる。
- レコード長が解っているので読み込みの最適化を行う
並列入力方式へのこうした適用により、入力が並列に処理され、元々のI/Oトランザクション長は維持されます。
表2はバージョン3.10および新しいコードの性能を示したものです。この例は上述のNaClの小さなケースで、ファイルフォーマットは用いられる最適化手法に応じたものです。
| 3.10 | New | 3.10 | New | ||
| Cores | I/O Procs | Time/s | Time/s | Mbyte/s | Mbyte/s |
| 32 | 16 | 3.71 | 0.29 | 17.01 | 219.76 |
| 64 | 16 | 3.65 | 0.30 | 17.28 | 211.65 |
| 128 | 32 | 3.56 | 0.22 | 17.74 | 290.65 |
| 256 | 32 | 3.71 | 0.30 | 16.98 | 213.08 |
| 512 | 64 | 3.60 | 0.48 | 17.53 | 130.31 |
| 1024 | 64 | 3.64 | 0.71 | 17.32 | 88.96 |
| 2048 | 128 | 3.75 | 1.28 | 16.84 | 49.31 |
以前と同様に両コードは、バッチサイズとI/Oプロセッサー数は全てデフォルトで、Lustreファイルシステムを用いました。入力処理は並列に処理されたことで大きな改善が示されていますが、出力ほどではありません。これは少なくとも大規模なI/Oトランザクションが発生するまでは並列に動作しないDL_POLY_3.10ではあり得ることです。バージョン3.10のシリアル入力処理時間は、バッチのブロードキャストでなくディスクアクセスがほとんどを占めている事が明らかです。入力処理性能はまた、プロセッサー数が増えた場合に、出力処理に比べより劇的に性能劣化を示しています。これについては更に調査が必要ですが、おそらくI/Oに用いているデフォルト設定の最適化は可能です。現状これらは以下のように設定されています
- $2P^{1/2}$個のI/Oプロセッサーを用いる。ここで$P$は全コア数です。
- 50,000原子のバッチを用いる。
- 各I/Oトランザクション毎に5,000原子のデータを出力する。
表3は大規模ケースのI/Oのスケール性能を示しています。
| Time/s | Mbyte/s | ||
| 128 | 32 | 1.15 | 437.24 |
| 256 | 32 | 1.02 | 494.68 |
| 512 | 64 | 1.22 | 414.61 |
| 1024 | 64 | 1.56 | 323.24 |
| 2048 | 128 | 3.64 | 138.73 |
| 4096 | 128 | 5.64 | 89.48 |
ここでは新しい手法のみ掲載しています。この大規模ケースに対しては、より良好なピークI/O性能が示されましたが、依然として性能の急激な落ち込みが残っています。
5.NetCDF
現状までのDL_POLYのリリースバージョンの入出力ファイルは、標準的なFortranのフォーマット文を用いた入力文で読み込むことが可能なものでした。このようなファイルの入力や生成は、大規模系においては以下の2つの理由により好ましくないでしょう:
- 数の内部的なバイナリー表現のキャラクターから/への変換は、I/O性能にオーバーヘッドを生じさせます。
- フォーマット・ファイルは通常、同じ内容のバイナリー・ファイルよりもかなり大きくなります。
入出力ファイルのポータビリティを温存したままこれらの問題を解決する試みとして、DL_POLY_3のI/Oサブシステムはごく最近に、netCDF[17]の並列入出力を可能にするように拡張されました。そこで選ばれた形式はAmberの用例に極めて似たものであり、主な違いは以下の点です
- ファイルはnetCDFファイルとしてオープンされ、HDF5[19]によるnetCDFバージョン4[9]の並列I/Oを用います。
- 原子の座標と速度は単精度ではなく倍精度として保存されます。
- 力はDL_POLY_3のフォーマット付きファイルに保存されます。
ファイルサイズは結果として、フォーマット付きの場合と比べてほぼ3分の1になります。トラジェクトリー履歴は結果として、数百ギガバイトの長さになりますが、実質的にかなり小さくなります。
現状の実装は前述の並列I/O手法を基礎に置いています。ソートとバッチは同様に実行され、ファイルの初期化とクローズおよび実際のI/O文のみを変更します。netCDFでの種々のI/Oパラメーターの最適化は不要で、MPI-I/Oベースの手法と同じものを用います。
表4は小規模NaClテストケースでの出力性能の結果を示しています。明らかに性能はMPI-I/Oと比較して残念な結果でした。入力に関しても同様な結果でした。ファイルサイズ削減による性能利得に関して、さらに調査を進めることが必要です。
| 3.10 | 3.10 | NetCDF | NetCDF | ||
| Cores | I/O Procs | Time/s | Mbyte/s | Time/s | Mbyte/s |
| 32 | 32 | 1.27 | 49.78 | 4.77 | 13.22 |
| 64 | 64 | 0.49 | 128.46 | 8.63 | 7.31 |
| 128 | 128 | 0.53 | 118.11 | 13.81 | 4.57 |
| 256 | 128 | 0.43 | 147.71 | 27.24 | 2.32 |
| 512 | 256 | 1.33 | 47.60 | 40.57 | 1.55 |
| 1024 | 256 | 1.20 | 52.47 | 67.55 | 0.93 |
| 2048 | 512 | 0.95 | 66.39 | 147.47 | 0.43 |
6.結論
図3は小規模NaClケースでの、全てのI/O最適化を含めた最新バージョンのスケール性能を示しています。同時にバージョン3.09のスケール性能も示しました。I/Oがコア数が多い時にスケール性能を阻害するという問題は、このサイズの系に関しては解決されています。

図3 : 216,000イオン系での全性能
図4は大規模系での性能を示します。ここでは新しいコードのみを載せています。I/Oが含まれていますが良好な結果を示しています。
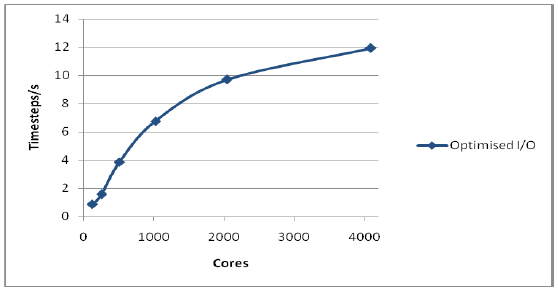
図4 : 1,728,000イオン系での全性能
構造の書き出しにおいて元のコードよりも多くの出力を行うにもかかわらず、新しいコードは極めて良好なスケーリング性能を示しています。この要因はディスク効率の良さと、ネットワークはCPUに比べれば遅いですが、ディスクよりは断然早い事実によるものです。この低速なI/Oの克服のために、出来る限りI/O性能を引き出すようにデータ全体を再構成することが重要です。問題の最も低速な部分を出来る限り高性能にするために最適化することが、このような実質的な最適化作業の基本となります。ですが、常に本ケースのように劇的に改善するとは限りません。
以上のように、適切なパラメータを与えれば、DL_POLY_3はI/Oを含めても数千のプロセッサーに対してスケールします。このことは極めて重要なことです。I/Oが無ければ、科学計算は成し得ず、シミュレーションは具体的なアプリケーションとなり得ない仮想的なベンチマークでしかありません。しかしながら今や、DL_POLY_3は数千のプロセッサー上で具体的な科学計算を実行することが可能となりました。
謝辞
著者らはMWRITEの方法へ導く洞察とその実装に関してDavid Tanquerayに感謝します。最終版ではないですが、これなしには残りの仕事は成し得ませんでした。また、本作業の多くを実施した、HPCxサービスおよびHECToR:英国リサーチカウンシル・ハイエンド・コンピューティング・サービスにも感謝します。Ian Bushは本作業の多くに関し、EPSRCよりdCSEアワードを授与されました。
注記
| [1] | "DL_POLY_3: New Dimensions in Molecular Dynamics Simulations via Massive Parallelism",Ilian T. Todorov, William Smith, Kostya Trachenko and Martin T. Dove, J. Mater. Chem., 16, 1611-1618 (2006). |
| [2] | https://www.nag.com/nagware/np.asp |
| [3] | http://www.forcheck.nl/ |
| [4] | "DL POLY 3 I/O: Analysis, Alternatives and Future Strategies", I.T. Todorov, I.J. Bush, A.R. Porter, Proceedings of Performance Scientific Computing (International Networking for Young Scientists) (February 2008, Lithuania), R. Čiegis, D. Henty, B. Kågström, J. Žilinskas (Eds.)(2009) Parallel Scientific Computing and Optimization. Springer Optimization and Its Applications, ISSN 1931-6828, Vol. 27, Springer, ISBN 978-0-387-09706-0, doi:10.1007/978-0-387-09707-7. |
| [5] | "The Need for Parallel I/O in Classical Molecular Dynamics", CUG Meeting proceedings, 5-9 May 2008 (Helsinki, Finland). |
| [6] | "DL_POLY_3 I/O Analysis, Alternatives and Future Strategies", I.T. Todorov, I.J. Bush, HPCx TR (July 2007), HPCxTR0707. |
| [7] | "DL_POLY_3 I/O: problems, solutions and future strategies", Capability Computing (HPCx News), Issue 11, SPRING 2008, p. 4. |
| [8] | "DL_POLY_3 Parallel I/O Alternatives at Large Processor Counts", I.T. Todorov, I.J. Bush, HPCx TR (July 2007), HPCxTR0806. |
| [9] | http://www.unidata.ucar.edu/software/netcdf/ |
| [10] | "I/O for High Performance Molecular Dynamics Simulations", I.T. Todorov, W. Smith, I.J. Bush, CSE Department Frontiers 2009 (www.stfc.ac.uk), STFC. |
| [11] | "Challenges in Molecular Dynamics on a Grand Scale", I.T. Todorov, W. Smith, I.J. Bush, L. Ellison, Proceedings of the First International Conference on Parallel, Distributed and Grid Computing for Engineering, 6-8 April 2009, Civil-Comp Press in P?cs, Hungary, B.H.V. Topping, P. Iv?nyi, (Editors), Civil-Comp Press, Stirlingshire, United Kingdom, paper 3, 2009, ISBN 978-1-905088-28-7. |
| [12] | http://www.hector.ac.uk/ |
| [13] | http://wiki.lustre.org/index.php/Main_Page |
| [14] | http://www.hpcx.ac.uk/ |
| [15] | ftp://ftp.dl.ac.uk/ccp5/DL_POLY/DL_POLY_3.0/DATA/ |
| [16] | http://www.ccp5.ac.uk/DL_POLY/ |
| [17] | http://www.unidata.ucar.edu/software/netcdf/docs/netcdf-tutorial/Parallel.html |
| [18] | http://ambermd.org/netcdf/nctraj.html |
| [19] | http://www.hdfgroup.org/HDF5/ |