
Wadud Miah, Nick Dingle, Jonathan Boyle, Sally Bridgwater
Numerical Algorithms Group
21 April 2017
1.背景
お客様:Fatima Chami博士 ダラム大学
アプリケーション:GBmolDD
言語:Fortran90
プログラミングモデル:MPI
使用入力データ:gbmoldd.inp(11章参照)
Compiler: Intel Fortran 13.0.1
MPI Library: Intel MPI 2017.0.098
CPU model: Intel Xeon E5-2670 2.60GHz
Interconnect: Infiniband FDR10
File/storage system: IBM GPFS
CPU model: Intel Xeon E5-2670 2.60GHz
Compute node: Two sockets with eight CPU cores per socket and 16 cores in total
Test case: 1024ダイマー分子 (11章参照)
2.アプリケーション構造
GBmolDD[1]は、等方性あるいは非等方性粒子からなる計の粗視化分子動力学シミュレーションコードです。ローレンツ-ベルテロ則で分子間力を近似する標準的なレナード-ジョーンズポテンシャルを用います。実行は3つの領域から構成されます:
- 1.分子系を規定する配位と分子データファイルの読込
- 2.分子間力に対するニュートンの第2運動法則を用いた時間積分
- 3.最終的な座標、エネルギー、温度の出力。GBmolDDはMPIプロセス毎に1ファイルを出力します。これらは別のFortranシリアルコードにより一つのファイルへマージされますが、本レポートはGBmolDDに焦点を当てます。
調査に用いたプロファイリングツールは、Paraver/Extrae、Intel Vectorization Advisor、およびDarshan I/O profilerです。
調査に用いたテストケースは、1024個のダイマー分子を含んだデータです。チェックポイント機能は使用しませんでした。調査は全て、ダイマー分子を1024個に固定してMPIプロセスを増やした場合の強スケール性に対して行いました。8プロセスで10ステップの実行タイムラインを図1に示します。全実行には2000ステップが必要です。

図1:1024ダイマー分子、8プロセス実行のGBmolDDの実行タイムライン
分子データ入力は暗緑(階段状に見える)、赤い背景はMPIプロセスの同期を表します。メインの時間積分は青色でグローバル同期がオレンジ、最後の暗緑は並列ファイルシステムへの出力です。
図1から、データファイル読み込みが完全にシリアル実行されていることが分かります。つまり、一つのプロセスが自身のデータ文を読込際には、その他のプロセスはそれが完了するまで待ち合わせをします。このシリアル実行は、分子データファイルが大きくなるとますます悪化します。このアプリケーションは、標準的なFortranI/Oサブルーチンを用いたPOSIX I/Oを利用しています。この問題には下記の対処が考えられます:
- 並列NetCDFや並列HDF5ファイル形式は並列I/O向けに設計されています。これを用いると各MPIプロセスは並列にその内容を読み込むことが可能です。これはPOSIX I/Oに比べて良好なスケール性を持つため推奨されます。
- POSIX I/Oでも、各プロセスはファイル内から自身が必要な部分をシークして並列に読み込むことが可能です。しかしながらPOSIX I/Oは並列ファイルI/O用に設計されておらず、スケール性もよくありません。
実行の最後に分子データは並列に出力されますが、ここでは各プロセスが別々のファイルへ書き込みます。
3.関心領域(ROI)
時間積分では、分子間力を計算して次の時間ステップへ座標を更新します。本作業では、ROIの分析のために4ステップだけを用います。ROIの8プロセス実行時のタイムラインを図2に示します。
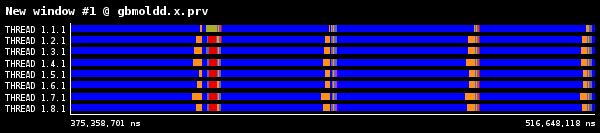
図2:1024ダイマー分子、8プロセス実行のROIの実行タイムライン
各時間ステップは琥珀色で示されたMPI_Allreduceで分離されます。MPI_Allreduce直後に、分子データを通信する大量のMPI_IsendとMPI_Irecvが呼び出され、小さな計算が散在しています。次に青色の分子間力計算を示すより大きな計算が続きます。赤色部分は、ノンブロッキング通信の完了を待つMPI_WaitとMPI_Waitallを示します。図2には、各時間ステップの最後にプロセス番号1のみで行われる小さなI/Oが示されています。これは負荷分散に寄与しますが、少量のため調査はしていません。。
一回の繰返しはMPI_Allreduceで区切られ、次の繰返しの開始では、図3に示すようにMPIプロセス間で分子座標が相互に交換されます。黄色の線がMPIプロセス間の通信を示します。
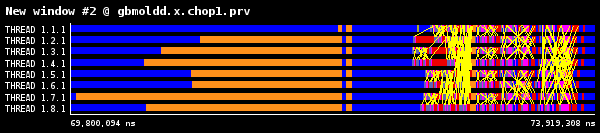
図3:1024ダイマー分子での繰返しの最初と最後
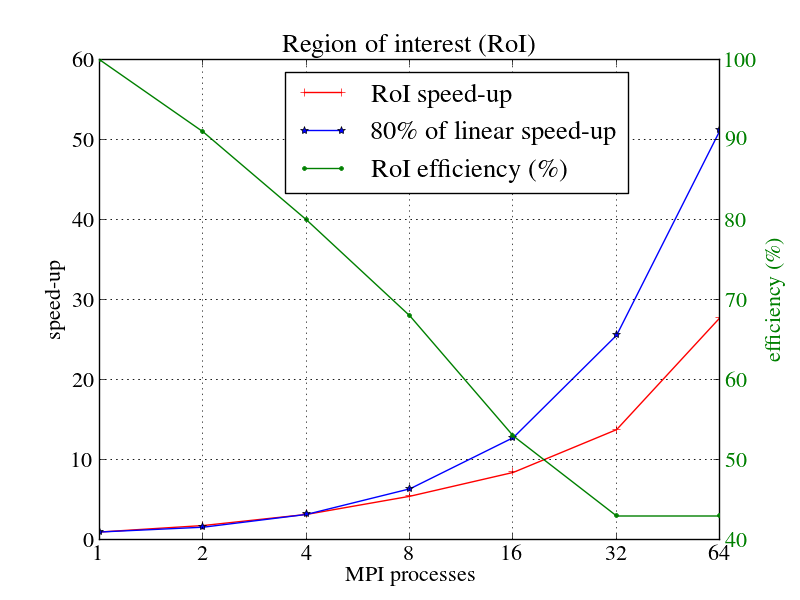
4.スケーラビリティ
並列スケーラビリティとスケーリング効率について、1024ダイマー分子のROIと全アプリケーションを図4a,bにそれぞれ示します。並列スケーラビリティ(1)とスケーリングスケーラビリティ(2)は以下の式を用います;
\begin{eqnarray} S_n=\frac{T_1}{T_n} \tag{1} \end{eqnarray}
\begin{eqnarray} E_n=\frac{S_n}{n} \tag{2} \end{eqnarray}
ここで、$T_n$はnプロセスの実行時間です。青色の線は80%の線形スケールを示し、赤色はアプリケーションのスケールを示します。緑の線は並列効率を%で示します。このセクションの性能結果はトレース結果ではなくコードから得た数値です。
 |
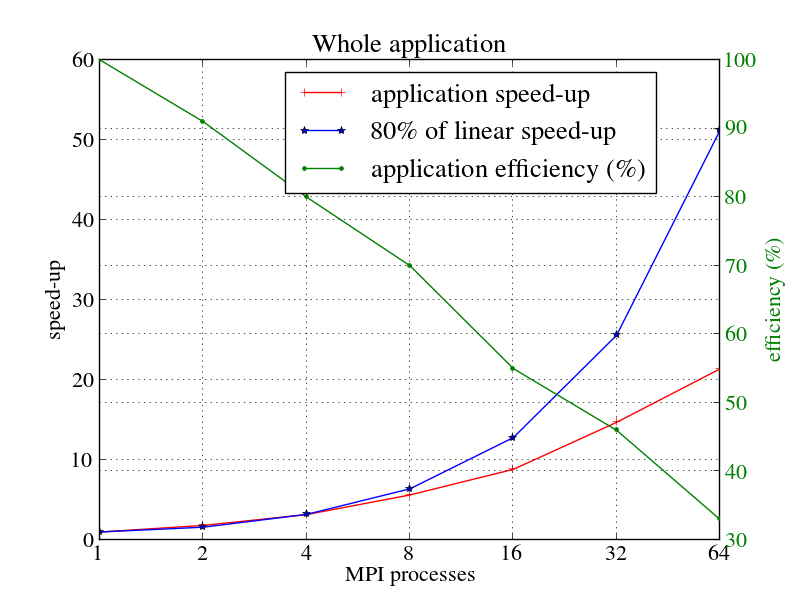 |
図からわかる通り、並列スケーラビリティはMPIプロセスの増加に伴い減少します。64プロセス時において、ROIと全アプリケーションの並列スケーラビリティはそれぞれ27.8と21.4です。同じく、並列効率はそれぞれ43%と33%です。スケーラビリティと効率は明らかにROIの方が高くなっています。これは、ROIがI/Oや初期化および終了処理が含まれないためです。
5.効率
表2に計算時間(computational time (CT))を示します。この図は、ユーザコードの時間がプロセス数の増加に伴い如何に良くスケールするかを示します。計算時間(CT)は、すべてのMPIプロセスにわたり集計された計算時間として定義されます。これ以降の性能数値は全てトレース実行結果によるものです。
| MPIプロセス数 | RoI | 全アプリケーション |
| 1 | 0.78 | 396.99 |
| 2 | 0.84 | 429.04 |
| 4 | 0.93 | 478.59 |
| 8 | 1.06 | 542.11 |
| 16 | 1.30 | 679.28 |
| 32 | 1.50 | 753.92 |
| 64 | 1.43 | 951.82 |
計算効率(computational efficiency (CE))は表2から以下の式を使って計算できます:
\begin{eqnarray} CE_n=\frac{time(CT_1)}{time(CT_n)}×100 \tag{3} \end{eqnarray}
ここで$CT_n$はnMPIプロセスの計算時間です。通信効率(communication efficiency)はプロセスの計算時間の最大値を実行時間で割った値です。並列効率(parallel efficiency)は負荷バランス(load balance:生産時間の平均値を最大値で割った値です)と通信効率の積です。シリアライゼーション効率(serialisation efficiency)は通信におけるアイドル時間による非効率性を示し、理想的なネットワークを用いた場合の最大計算時間を最大実行時間で割ったものです。転送効率(transfer efficiency)はデータ転送時間による非効率性を示すもので、理想ネットワーク上の計算時間の最大値を実行時間で割ったものです。グローバル効率(global efficiency)は並列効率と計算効率の積です。
表3にROIに対す得る様々な効率指標を示しました。これらは全て%で示されています。表3に含まれる通信効率はシリアライゼーション効率と転送効率の積です。これら指標の詳細な説明は[3]をご覧ください。
| MPIプロセス数 | 2 | 4 | 8 | 16 | 32 | 64 |
| グローバル効率 | 90.4 | 79.8 | 68.2 | 52.6 | 42.9 | 44.9 |
| 計算効率 | 92.1 | 83.6 | 73.5 | 59.7 | 51.7 | 54.1 |
| 並列効率 | 98.1 | 95.5 | 92.7 | 88.2 | 83.1 | 82.9 |
| 負荷バランス | 98.7 | 96.7 | 94.8 | 92.5 | 91.0 | 91.0 |
| 通信効率 | 99.3 | 98.7 | 97.7 | 95.3 | 91.3 | 87.7 |
| シリアライゼーション効率 | 99.9 | 99.9 | 99.9 | 98.9 | 96.6 | 98.5 |
| 転送効率 | 99.9 | 98.7 | 97.8 | 96.3 | 94.4 | 89.1 |
計算効率は急速に悪化します。以下の理由が、プロセス数の増加に伴う計算の増加の要因と考えられますが、おそらくこれらが今回の計算効率の劣化の要因であると考えられます:
- 周期境界条件により、領域境界にレプリカあるいはハロ(サブ)領域が存在します。このため、サブ領域が余分な分子を含むために追加の演算が発生します。
- MPIプロセス間の時間の掛かる通信を避けるため、分子はサブ領域にまたがって複製されます。よって分子間力計算も重複します。
GBmolDDには他にも計算効率の劣化要因が在るかもしれません。分子の複製を止めて計算効率が上昇する場合に、更に調査します。表3の負荷バランスは91%以上あり、作業は良く分散されていることを示しています。計算効率は、急速に劣化しており、8プロセス以上で80%以下に落ち込みます。結果的にこれは並列効率以上にグローバル効率の劣化を招きます。しかしながら、その計算の内のいくらかは重い通信を削減しており、この問題は計算と通信のトレードオフであると言えます。最も最適な分子複製のやり方は、実行時間をより少なくするように決定すべきです。
表4に命令数とIPCのスケール性を示します。IPCスケーリングは良好ですが、命令数スケーリングは劣化しています。この命令数の増加は、高価なMPIプロセス間の通信を避けるために領域を複製して分子間力を重複計算するためです。
| MPIプロセス数 | 命令数スケーリング | IPCスケーリング |
| 1 | 100% | 100% |
| 2 | 91.02% | 100.73% |
| 4 | 80.21% | 104.69% |
| 8 | 72.66% | 106.14% |
| 16 | 63.10% | 107.22% |
| 32 | 59.62% | 104.74% |
| 64 | 55.91% | 107.96% |
時間当たりのサイクル数(cycles per time)は、実際の計算に掛かったサイクル数を時間で割った値です。時間当たりのサイクル数は、計算ノードの温度やMPIプロセスがどのようにノードに割当てられているかによってCPUの周波数が変動するため測定されています。本レポートで用いた計算ノードは16コア/ノードで、コアに空きがあれば周波数は高くなります。
| MPIプロセス数 | Cycles per time (Hz) | Cycles per time効率 |
| 1 | 3247004764 | 100% |
| 2 | 3288414651 | 101.28% |
| 4 | 3242972787 | 99.88% |
| 8 | 3097985981 | 95.41% |
| 16 | 2879613384 | 88.69% |
| 32 | 2703652914 | 83.27% |
| 64 | 2933693608 | 90.35% |
図5から、プロセス数が8までは周波数は3GHz以上ですが、ノードが満たされる16,32,64プロセスでは減少しています。特に16プロセスにおいて、周波数減少は時間当たりのサイクル数の効率も減少させ、これは表3の計算効率減少に反映されています。64プロセスではどちらも増加しており、これが表3の計算効率も増加させています。
6.負荷バランス
負荷バランスは以下の点に依存します:
- 1.プロセス間に渡って均等に分子が分配されているか
- 2.高価なプロセス間通信を避けるために、プロセス間に渡って均等に分子が複製されているか
64プロセスでのROIに対する、計算の負荷バランスを図5示しました。赤点はプロセス毎の(通信以外の)命令数、緑点はIPCを示します。
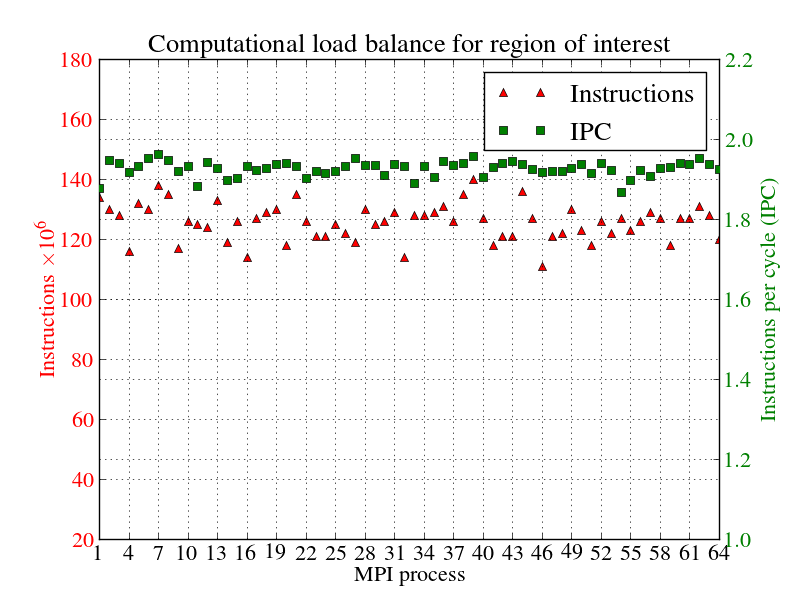
図5:1024ダイマー分子の、ROIの計算の負荷バランス
特にIPCは良好な負荷バランスを示しています。継続時間ヒストグラム(useful duration histogram)を図6に示します。これは64プロセス実行時のMPIルーチン呼出し間の継続時間が示されています。横軸は計算継続時間、縦軸はプロセス数です。薄い緑は希薄な部分、濃い青が高い密度を示します。
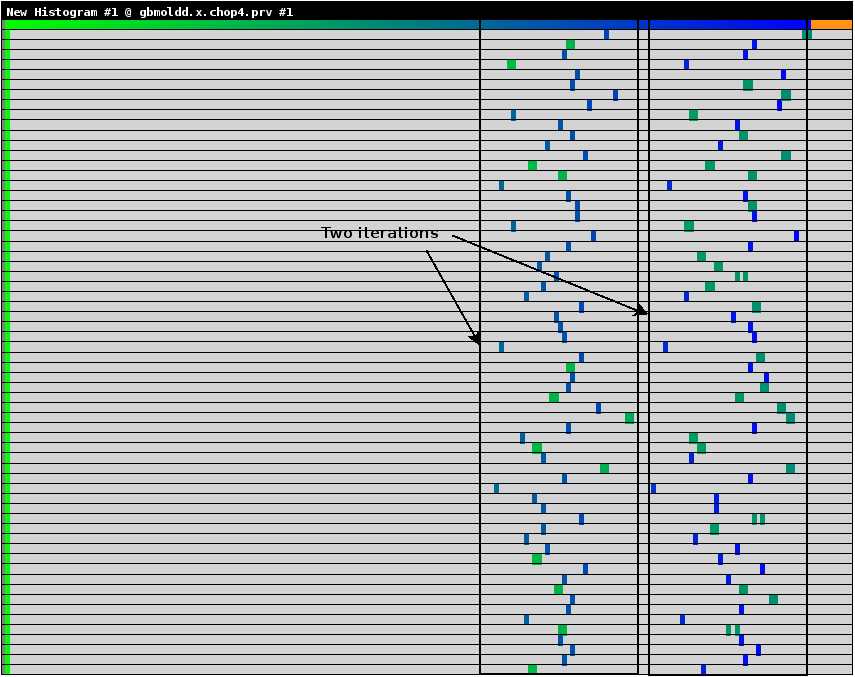
図6:1024ダイマー分子の、ROIの継続時間ヒストグラム
完全に負荷バランスする場合、ヒストグラムは横1線の同色のブロックとなります。ヒストグラムは3種の時間を表します:
- 1.一番左にある、MPI_IsendとMPI_Irecv間に分散されたグループ
- 2.1番目の2つの時間ステップを含むグループ
- 3.2番目の2つの時間ステップを含むグループ
1番目と3番目の繰返しを示す、3番目のグループのタイムラインを図7aに示しました。また、2番目と4番目の繰返しを示す、2番目のグループのタイムラインを図7bに示しました。ここで注目すべきは、各時間ステップで継続期間は様々であることです。これはサブ領域内で分子が如何に複製されたかによります。
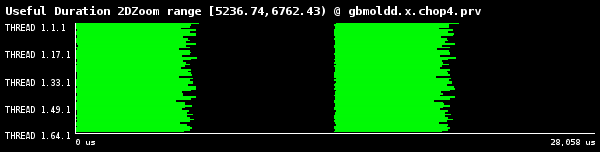
(a)第3グループの1,4ステップ
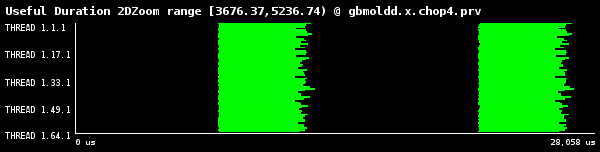
(b)第2グループの2,4ステップ
図7:1024ダイマー分子の、継続期間ヒストグラムの4つの繰返し
図6から、ブロックは2つの繰返しフェーズでそれほど離れておらず、良好な負荷バランスを示しています。表3から、計算負荷バランスはROIで91%で良好です。命令数ヒストグラムとIPCで色付けした継続期間ヒストグラムをそれぞれ図8と図9に示します。
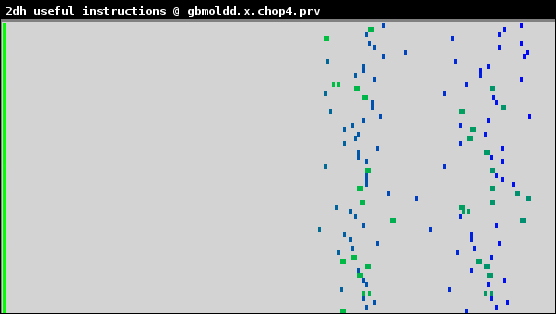
図8:1024ダイマー分子の、命令数ヒストグラム
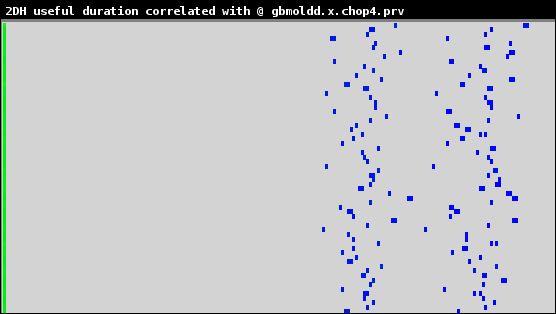
図9:1024ダイマー分子の、IPCで色付けした継続期間ヒストグラム
図8,9から、各プロセスの命令数はIPCとほぼ同じであるため、負荷バランス問題は作業の不均衡から生じることが分かります。しかしながら、64プロセスでの負荷バランスは91.0%で極めて良好です。
7.計算性能
ROIに対する表6の命令数とIPCは、計算時間と関連する命令数の増加を示しています。
| MPIプロセス数 | 命令数 | IPC |
| 1 | 4,519 × 106 | 1.7844 |
| 2 | 4,964 × 106 | 1.7974 |
| 4 | 5,634 × 106 | 1.8682 |
| 8 | 6,219 × 106 | 1.8941 |
| 16 | 7,162 × 106 | 1.9133 |
| 32 | 7,579 × 106 | 1.8690 |
| 64 | 8,082 × 106 | 1.9266 |
表6から、プロセス数の増加に伴いIPCは改善し、命令数は増加することが分かります。命令数の増加は、高価な通信の回避のために複写したサブ領域と分子間力計算のためです。最も最適な分子複製のやり方は、並列実行時間スケーラビリティを改善するように決定すべきです。
表7は、ベクトル化抑止を含めて様々なベクトル化フラグをコンパイラに与えた場合の、4プロセス実行時の性能です。"% time in vector code"欄は、CPU時間のベクトル演算に占める割合で、これ以外はスカラー演算です。この指標はIntel Vectorization Advisorツールから計測しました。
デフォルトのベクトル化はSSE2で、全ての最新のIntel CPUで実行可能です。もし用いるCPUがより大きなベクトルユニット、例えばAVXが使用できる場合、そのCPU上でフラグ-xHostを用いるべきです。SSE2ベクトルユニットは、1命令で2つの倍精度演算、AVXは4つの倍精度演算を行う能力を持ちます。本レポートのXeon CPUはAVXベクトルユニットを搭載しますが、GBmolDDは現在-O3フラグでコンパイルされており、AVXベクトルユニットを利用していません。
| コンパイルフラグ | -no-vec -O2 | -O3 | -no-vec -O3 | -xHost -O3 |
| Vector unit | None | SSE2 | None | AVX |
| Runtime (seconds) | 470.25 | 122.41 | 131.14 | 129.49 |
| % of time in vector code | 0.0% | 3.3% | 0.0% | 0.4% |
| IPC | 2.47 | 1.83 | 1.84 | 1.79 |
| Instructions×106 | 14,473,129 | 2,820,160 | 2,954,075 | 2,847,562 |
表7から、GBmolDDのベクトル実行時間の割合は極めて小さいです。AVXを利用すると割合がさらに小さくなり、より多くの時間をスカラーモードで消費します。ここではSSE2とAVX共に命令数はかなり少なく、これがIPCを押し下げています。さらに、-xHostフラグでは実行時間が伸びています。コードのベクトル化の不足を調査すべきです。
8.通信性能
表8に、ROIのMPIルーチンに掛かる時間の割合(%)を示します。これは全プロセスのMPIルーチン時間の総和を全プロセスの実行時間の総和で割ったものです。
| MPIプロセス数 | 2 | 4 | 8 | 16 | 32 | 64 |
| MPI_Allreduce | 0.87 | 2.45 | 3.74 | 4.20 | 7.14 | 10.74 |
| MPI_Wait | 0.59 | 1.31 | 2.24 | 5.34 | 6.66 | 3.58 |
| MPI_Isend | 0.20 | 0.44 | 0.77 | 1.40 | 1.69 | 3.06 |
| MPI_Irecv | 0.13 | 0.23 | 0.40 | 0.65 | 1.04 | 2.06 |
| MPI_Waitall | 0.04 | 0.07 | 0.12 | 0.21 | 0.33 | 0.66 |
MPI_Allreduceの平均時間はプロセス数の増加に伴って増えています。これは計算負荷不均衡の兆候であり、処理するデータの増加を示します。これは、MPI_IsendとMPI_Irecv、およびそれぞれに対応する同期ルーチンMPI_Wait、MPI_Waitallも同様です。
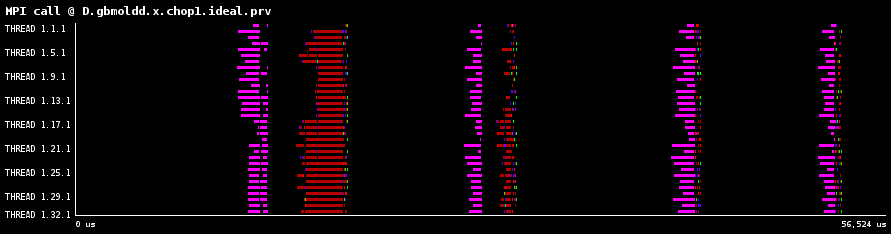
図10aは32プロセスのMPIルーチンのタイムラインを示し、図10bは理想ネットワーク(レイテンシーがゼロかつ無限に広いバンド幅)上でのMPIタイムラインを示したものです。この比較から、転送効率の殆どが膨大なMPI_IsendとMPI_Irecv呼出しに起因することが分かります。MPI_Allreduceも同様の傾向を示していました。
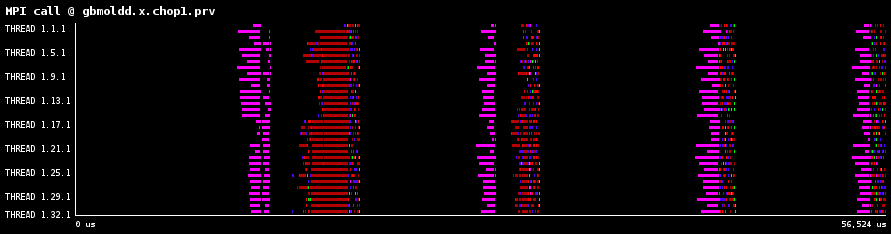  |
| (a) 32プロセス時の観測されたタイムライン |
 |
| (b) 32プロセス時の理想ネットワークのタイムライン |
図10:1024ダイマー分子での、観測あるいは理想ネットワークによるMPIタイムライン
本レポートの様にIntel MPIを用いる場合、MPI_Allreduceルーチンのリダクションアルゴリズムは、環境変数I_MPI_ADJUST_ALLREDUCEへ1から12の値を指定することでチューニング可能です。これらの詳細は[2]を参照してください。最適な選択は以下の点に依存します:
- データサイズ:MPI_Allreduceでは一定です。この場合アルゴリズム選択はシンプルになります。
- MPIコミュニケータ内のプロセス数
- ネットワークトポロジー
表9が示すのは、実行全体に対するMPIルーチンの実行時間の割合です。MPI_Barrierの割合が高いのは、図1aに示した分子データ読込がシリアル実行されるためです。
| MPIプロセス数 | 2 | 4 | 8 | 16 | 32 | 64 |
| MPI_Wait | 0.22 | 0.4 | 1.7 | 5.6 | 4.0 | 7.3 |
| MPI_Barrier | 0.02 | 0.1 | 0.4 | 1.4 | 4.4 | 11.5 |
| MPI_Allreduce | 1.42 | 4.4 | 4.9 | 9.6 | 14.2 | 17.9 |
表10に示したのは、ROIのデータ転送MPIルーチンです。これはルーチンの呼出し回数と各ルーチンの平均データバイト数です。
| MPIプロセス数 | MPI_Isend | MPI_Irecv | MPI_Allreduce |
| 2 | 288 calls 9197 bytes/call |
288 calls 9197 bytes/call |
46 calls 35 bytes/call |
| 4 | 576 calls 6798 bytes/call |
576 calls 6798 bytes/call |
92 calls 35 bytes/call |
| 8 | 1152 calls 4404 bytes/call |
1152 calls 4404 bytes/call |
184 calls 35 bytes/call |
| 16 | 2304 calls 3186 bytes/call |
2304 calls 3186 bytes/call |
368 calls 35 bytes/call |
| 32 | 4608 calls 2487 bytes/call |
4608 calls 2487 bytes/call |
736 calls 35 bytes/call |
| 64 | 9216 calls 1736 bytes/call |
9216 calls 1736 bytes/call |
1536 calls 35 bytes/call |
MPI_Allreduceの呼出し当たりのバイト数は、1バイトだけ多い64プロセスの場合を除きほぼ一定です。このバイト数は割と小さく、より大規模なデータセットでリダクションを適用するために、これら複数の呼出しを統合する事も可能です。また、データが小さいため、性能はレイテンシーで決められています。この他、MPI_IsendやMPI_Irecvは膨大な回数呼ばれています。特にプロセス数が大きい場合がそうです。可能であればデータを集約して少ない回数で送受信するようにすべきです。
表11は、最も時間が掛かったプロセスにおける最も時間の掛かったMPIルーチンを示しています。
| MPIプロセス数 | 最大時間消費MPIルーチン |
| 2 | MPI_Isend |
| 4 | MPI_Isend |
| 8 | MPI_Isend |
| 16 | MPI_Wait |
| 32 | MPI_Allreduce |
| 64 | MPI_Isend |
表11から、MPI_Isendがクリティカルパスであることが分かります。先述したように、データを集約して少ない呼出し回数で多くのデータを送信することで、MPI_Isendの呼出し回数を削減可能です。
9.入出力性能
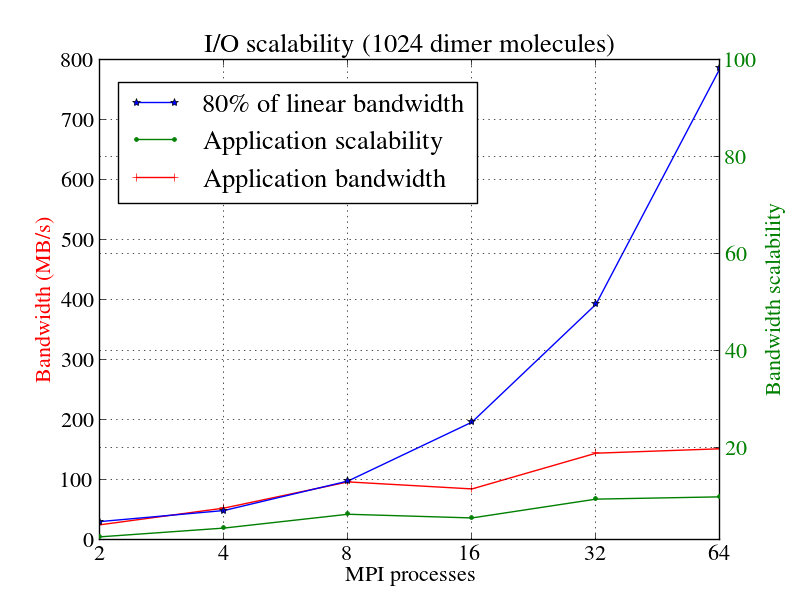
GBmolDDの並列I/Oスケーラビリティを図11aに示します。青線が全バンド幅の80%を示します。全バンド幅は、一つのMPIプロセスのバンド幅に沿うプロセス数を掛けたものです。赤線はアプリケーションのI/Oバンド幅です。緑線はI/Oスケーラビリティで、nプロセスのバンド幅を1プロセスのバンド幅で割ったものです。
 |
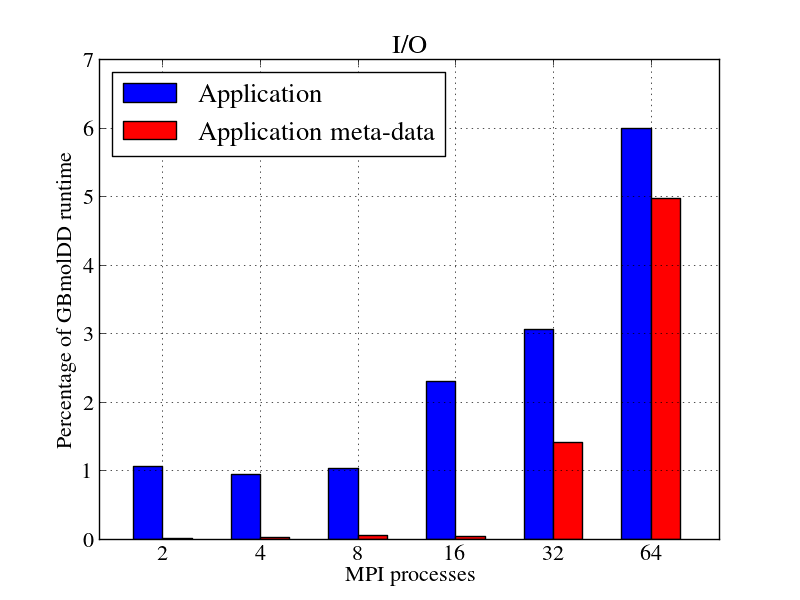 |
図11aでは、16MPIプロセスのバンド幅が減少しています。これは、単一ノード上にI/Oトラフィックが存在することが原因です。32プロセスでは、I/Oは2つのノードに分散しているためバンド幅が増加します。64プロセスでのI/Oバンド幅は、全バンド幅の80%にはほど遠い状況です。
GBmolDDコードはMPIプロセスごとに1つのファイルを書き込み、可視化と分析のために異なるファイルを1つのファイルに統合ために、全ファイルを別のシリアル実行Fortran90コードでポスト処理する必要があります。GBmolDDコードのI/Oの実行時間の割合を図11bに示します。I/O時間は、ファイルメタデータを作成する時間とファイルにデータを書き込む時間の合計です。
図11bは、メタデータフェーズで費やされた時間を実行時間の割合として示しています。あらゆるファイルシステムには、ファイル所有者、フルパス、ファイルサイズ、最終更新日時、およびファイルに関するその他の情報を含むファイルメタデータが含まれています。並列ファイルシステムは、どのストレージノードがファイルのどのブロックおよびストライプサイズを格納したかなどの拡張メタデータを格納します。MPIプロセスの数が増えると、アプリケーションのI/Oがメタデータフェーズ(赤いブロック)に多くの時間を費やしていることがわかります。これは、GBmolDDコードでは、各MPIプロセスが個々のファイルに書き込みを行うため、並列ファイルシステムが各ファイルに関連するメタデータを作成する必要があるためです。並列ファイルシステムは、通常、ストレージサーバより少ないメタデータサーバが存在するため、メタデータサーバの数に応じてメタデータフェーズをシリアル化します。
メタデータ量を減らすには、プロセス当たり1サイズの現状から、MPI-IO、並列NetCDF、並列HDF5等の並列I/Oファイルフォーマットへ置き換えるべきです。文献[1]では、512MPIプロセスでのソフト球面円柱粒子64000個の斥力シミュレーションに対して、I/Oフェーズに50%の実行時間が掛かっています。このうちどの程度がメタデータフェーズに費やされるかは不明ですが、大規模MPIプロセス数では大きな問題となることは明らかです。
| MPIプロセス数 | 負荷バランス(%) |
| 2 | 98.95 |
| 4 | 96.39 |
| 8 | 96.16 |
| 16 | 93.53 |
| 32 | 88.78 |
| 64 | 85.40 |
I/O負荷バランスを実行時間の割合として表現したものを表12に示します。負荷バランスは、プロセスが増加すると減少しています。負荷バランス効率を改善してアプリケーションの性能を最適化するには、各MPIプロセスに均等なデータ量を出力させるべきです。
10.観察結果のまとめ
検証作業で得られた観察結果を以下に纏めました:
- 計算効率は表3で示したように急激に劣化します。これはおそらく、周期境界条件によりレプリカされたサブ領域が追加の演算を発生させ、高価な通信の代わりに分子間力計算が複製されている事が要因と考えられます。この通信回避アルゴリズムの形式は、計算スケーラビリティを低下させますが通信量を減少させます。これは計算と通信のトレードオフ関係にあります。
- 表10から、1024ダイマー分子では多くのMPI_IsendとMPI_Irecvの呼出しが発生しています。表3で示されているように、64MPIプロセスまでは計算負荷バランスは91%と極めて優れています。
- I/Oスケーラビリティは、図11aを見ると線形スケーラビリティからは程遠いです。16プロセスでは、I/Oトラフィックが単一ノード上に在ることからバンド幅が減少します。32プロセスでバンド幅が上昇するのは、I/Oが2つのノードに分散するためです。64MPIプロセス(4ノード)でI/Oバンド幅は大きくは増加しませんでした。
- GBmolDDのI/O実行時間の比率は、図11b(青色バー)の様に増加していきます。これは、図11bに示された通り、そのI/Oの大部分がメタデータフェーズ(赤色バー)に費やされるためです。1024ダイマー分子の単純なケースではI/Oはボトルネックではありませんが、分子数が増えて大きな系なると、例えば文献[1]の様にボトルネックになるでしょう。
- GBmolDDは、入力ファイルgbmoldd.inpを読み込むサブルーチンread_inp_fileを全てのMPIプロセスが呼び出します。これは不要として、単独のプロセス(通常はプロセス番号0)がファイルをオープンしてパラメータを読込み、他の全てのMPIプロセスへブロードキャストする方が良いでしょう。図1aに見えるように、全プロセスの分子データ読込はシリアル実行されており、明らかに並列化が可能です。
- 表7で示したように、GBmolDDはAVXベクトルユニットを全く使っていませんが、ベクトルモード演算自体が少量しかありません。
10.1 推奨
検証作業で得られた推奨作業を以下に纏めました:
- 分子の複製がMPIプロセス間の高価な通信を回避するために用いられています。この結果、各プロセスにおいて分子間力計算が重複して行われます。しかしながらこうした重複により実行時間が大きくなるのは好ましくなく、並列スケーラビリティをより良くするためには分子複製レベルを更に最適化する必要があります。分子複製レベルをどのように構成するかについての情報が有りませんが、コード開発者と共にさらに調査することも可能です。分子複製を止めて計算効率がどの程度向上するかを見ることが可能です。
- 高価な通信回避のための分子複製は、計算効率の低下要因の一つとして特定されました。MPI+OpenMPハイブリッド並列の実装により、通信を削減してその結果分子複製を削減することが出来る可能性があります。ハイブリッド並列モデルにより、単一MPIプロセスがI/Oを行うようにしてI/O性能を向上させることも可能です。
- MPI_IsendとMPI_Irecvによるデータ転送は、より少ないMPIルーチンを用いて集約可能です。さらに、Intel MPI Linux環境変数"I_MPI_ADJUST_ALLREDUCE"を用いてMPI_Allreduceのリダクションアルゴリズムのチューニングも可能です。詳細は文献[2]を参照ください。
- 図1aに示したシリアル実行I/Oは、POSIX I/Oに比べて並列性能に優れたMPI-IO、並列NetCDF、並列HDF5ファイルフォーマットを用いて改善できます。
- I/Oは2つのフェーズで構成されています:各MPIプロセスが1ファイルを出力する処理、およびこれらの全ファイルを1ファイルへ統合するポスト処理です。多くの実行時間がメタデータフェーズに費やされています。これは膨大な量のファイルが生成され、書き込まれているためです。並列NetCDFや並列HDF5ファイルフォーマットを利用すれば、全てのプロセスが1ファイルへ書き込むことが可能になり、、ポスト処理を削除してメタデータフェーズの時間を削減することが可能です。図11bには、64プロセスまでの2000時間ステップに対するI/O時間が掲載されています。しかしながらより大きな系やより多数のプロセスを用いる場合は更に悪化するでしょう。
- I/O負荷バランスが表12に示されていますが、MPIプロセス数が増加するに伴い負荷バランスが悪化しているため、改善が必要です。全MPIプロセスが均等なデータ量を出力するようにすべきです。
- 表7に示したように、GBmolDDはAVXベクトルユニットを全く使っていませんが、ベクトルモード演算自体が少量しかありません。インテルのベクトル化アドバイザーツールを使用して、ベクトル化を妨げているものを判別することができます。このコードは、ベクトル化の理想的な候補であるFortran 90配列演算を多く含んでいます。
文献
| [1] | H. Slim and M. Wilson. Toward Large Scale Parallelization for Molecular Dynamics of Small Chemical Systems: A Combined Parallel Tempering and Domain Decomposition Approach. Journal of Chemical Theory and Computation, 4(10):1570-1575, 2008. |
| [2] | Intel Developer Zone. I_MPI_ADJUST Family. https://software.intel.com/en-us/node/528906, 2017. |
| [3] | Performance, Optimisation and Productivity. POP Standard Metrics for Parallel Performance Analysis. https://pop-coe.eu/node/69, 2017. |
補足事項:この作業はPOPプロジェクト(*)の任務として担当したnAGのスタッフが実施しました。
(*)EUのHPCプロジェクトPerformance Optimisation and Productivity (POP)は、科学技術研究に対するHPC技術の利用を促進を目的として欧州委員会によって推進されているHPC領域の8つのセンターオブエクセレンスの1つです。POPは2015年に開始され、バルセロナ・スーパーコンピューティングセンターに設置されました。POPプロジェクトには、nAG、ユリッヒおよびシュツットガルト・スーパーコンピューティングセンター、アーヘン大学、Teratecがパートナーとして選ばれました。
POPは、EU内の組織に無料でサービスを提供しており、並列ソフトウェアのパフォーマンスを分析かつ問題を特定してパフォーマンスの改善を提案するプロジェクトです。性能分析ツールとして、バルセロナ・スーパーコンピューティングセンターで開発されたExtraeとParaverが主に用いられています。