
Wadud Miah, Jonathan Boyle, Sally Bridgwater, Nick Dingle
Numerical Algorithms Group
10 Nov 2016
1.背景
お客様:Hans Fangohr博士 サザンプトン大学
アプリケーション:FIDIMAG
言語:Python、C
プログラミングモデル:OpenMP
使用入力データ:micromagnetic/std4. Problem size of nx = 200, ny = 50 and nz = 1
検証条件:Compiler: GNU C 4.9.2
Interpreter: Python 2.7.8
CPU model: Intel Xeon E5-2670 2.60GHz
2.アプリケーション構造
FIDIMAG (FInite DIfference atomistic and microMAGnetic solver)は、ユーザ指定の磁気系定義から、有限温度の原子レベルシミュレーションあるいは微視的磁気連続体ソルバーのどちらかを選択可能なPython言語のソフトウェアパッケージです。有限差分法を用い、立方格子と六法格子を定義可能です。計算負荷が高い部分はC言語で実装され、Sundial代数系ソルバーとFFTWを用います。Pythonコードは性能面からCythonでコンパイルされています。C言語部分はOpenMPで並列化されています。FFTWもOpenMP並列化されています。
このアプリケーションは3つのフェーズから成ります:
- 1.領域を有限差分セルへ離散化するプリプロセス
- 2.時間発展を解くメイン処理
- 3.Matplotlibを用いてデータを可視化するポスト処理
この2番目のフェーズが最も高コストです。また、コードの一部がPythonで記述されているため、Intel VTuneで全てをプロファイリングすることは困難ですが、ハードウェアカウンタを採取可能なコードの実行時間を示すことが出来ました。
3.関心領域(ROI)
議論の対象となる関心領域は、SundialライブラリのIDAを用いた陽的時間積分です。本レポートでは1章で述べたテストケースに焦点を当てます。
4.スケーラビリティ
FIDIMAGはGNUコンパイラでビルドされています。問題サイズ:nx = 200, ny = 50, nz = 1でのmicromagnetic/std4テストケースでは、その並列スケーラビリティと効率は図1に示されています。
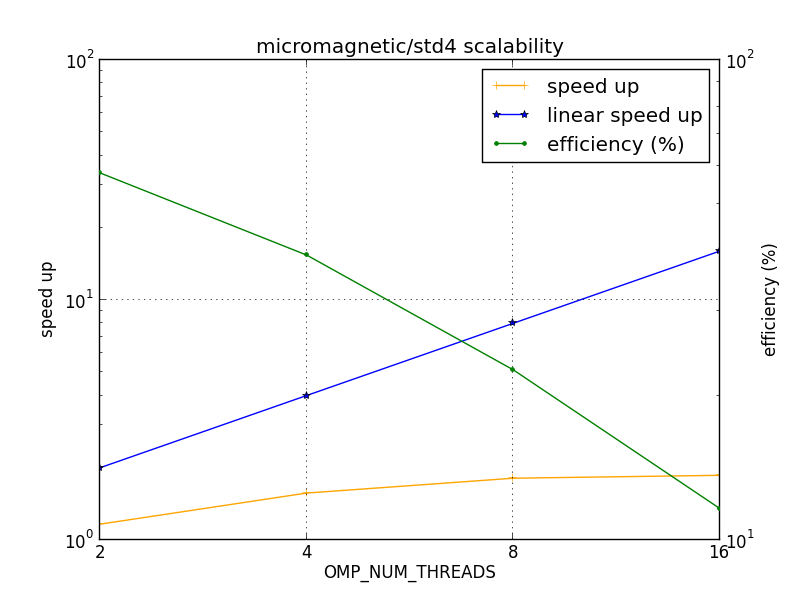
図1:micromagnetic/std4テストケースでのFIDIMAGのスケーラビリティ
図1から見て取れるのは、スレッド数の増加に伴うスケーラビリティの減少で、線形スケーラビリティには程遠い結果です。
このテストケースの実行時間を表1に示します。
| OMP_NUM_THREADS | Run time |
| 1 | 271.130 |
| 2 | 233.003 |
| 4 | 172.784 |
| 8 | 149.854 |
| 16 | 145.785 |
FIDIMAGはPython/CythonおよびC言語の混合コードです。Pythonやコンパイルされたコードでどの程度時間が掛かっているかを調べました。図2には、各ルーチンのインクルーシブとセルフ(自身のみに掛かった)時間の割合が示されています。このプロファイルはPythonのプロファイラcProfileが生成したものです。注目すべきフィールドはインクルーシブ時間ではなく「self」です。このプロファイルは16スレッドのものです。

図2:16スレッドでのmicromagnetic/std4テストケースのcProfile結果
図2から、実行時間の91%強がコンパイルコードで費やされています。これはモジュール名の最後が「.pyx」で示されるもので、以降コンパイルコードと呼ぶCythonコードです。そこで、以降はこのコンパイルコードのプロファイルに焦点を当てます。
5.効率
表2に計算時間(computational time(CT))を示します。これは、スレッド数の増加に伴うユーザコード実行時間のスケール性を示しています。
| OMP_NUM_THREADS | ユーザコード実行時間[秒] |
| 1 | 279.469 |
| 2 | 317.876 |
| 4 | 301.631 |
| 8 | 318.522 |
| 16 | 370.408 |
表2から計算スケーラビリティ(computational scalability(CS))を下記の式で計算できます:
\begin{eqnarray} CS_n=\frac{time(CT_1)}{time(CT_n)} \tag{1} \end{eqnarray}
ここで、nはスレッドの数です。スレッド効率(threading efficiency (TE))は最大のスレッド時間を経過時間で割ったもの、並列効率(parallel efficiency (PE))は負荷バランス(load balance (LB))(平均スレッド時間/最大スレッド時間として計算)とスレッド効率の積として計算されます。グローバル効率(global efficiency (GE))は並列効率と計算スケーラビリティの積です。これらの数値を表3に示します。
| OMP_NUM_THREADS | 2 | 4 | 8 | 16 |
| グローバル効率 | 58.42% | 41.36% | 23.01% | 11.91% |
| 計算スケーラビリティ | 87.92% | 92.65% | 87.74% | 75.45% |
| 並列効率 | 66.45% | 44.64% | 26.23% | 15.79% |
| 負荷バランス | 71.12% | 48.22% | 28.62% | 16.98% |
| スレッド効率 | 93.43% | 92.57% | 91.66% | 92.99% |
表3から、並列効率とグローバル効率がスレッドの増加に伴い減少するのが見て取れます。これはスレッド効率が比較的一定なのに対し、負荷バランスが急速に落ち込むことによるものです。計算スケーラビリティも同様に減少する傾向です。
6.負荷バランス
計算負荷バランス(computational load balance)
図3に計算負荷バランスを示しました。これはどのスレッドが(リタイアした)命令を実行したか、および計算領域コードのみのサイクル当たりの命令数IPCを示します。OpenMPマスタースレッドは764,220×106命令を行い、スレッド2から14まではほぼ100,000×106命令を、そしてそれ以降は減少しています。スレッド16が最小値です。OpenMP並列領域の外側ではマスタースレッドは実行を継続します。よって、図3から、コードはOpenMP並列領域に十分に実行時間を割り振っていないことが分かります。
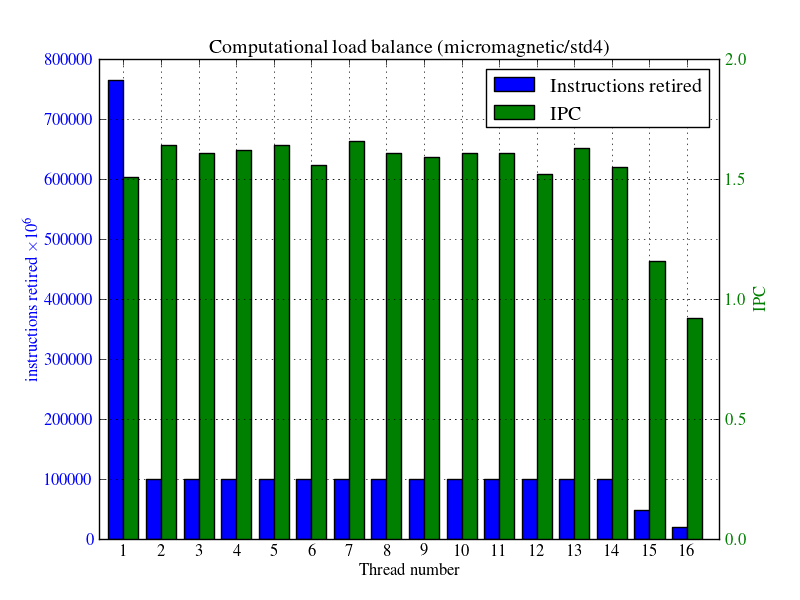
図3:micromagnetic/std4テストケースの計算負荷バランス
7.計算性能
命令スケーラビリティ(instruction scalability)は、単一スレッドで実行された命令数と比較したスレッドの増加に伴う実行命令(リタイアした命令)数として定義されます。これを表4に示します。問題視サイズを固定した場合、命令数は一定であるべきですがスレッド数により増加する場合があります。表4では、命令数は「ほぼ」一定で、良好な計算スケーラビリティを示しています。言い換えれば、スレッド数を増加しても余分な計算は発生していません。
| OMP_NUM_THREADS | 命令数[106] | IPC | 命令スケーリング[%] | IPCスケーリング[%] |
| 1 | 2091484.2 | 2.45 | - | - |
| 2 | 2088036.6 | 2.07 | 100.16 | 84.49 |
| 4 | 2088928.4 | 2.12 | 100.12 | 86.53 |
| 8 | 2091481.6 | 1.96 | 100.00 | 80.00 |
| 16 | 2132514.8 | 1.55 | 98.08 | 63.27 |
計算のみに対するIPCは高い方が良いですが、表4からはスレッドが増えると漸次悪化することが示されています。
最もCPU時間の掛かるモジュールが図4に示されていますが、GNU OpenMPライブラリがトップです。これは、スレッド2から16までが殆どがスピンしているためであり、OpenMPライブラリで多くの時間が消費されていることが原因です。

図4:micromagnetic/std4テストケースの高CPU時間モジュール
2番目のモジュールはFFTWライブラリです。これは最も計算負荷の高いカーネルです。FIDIMAGはSundialsライブラリのシリアル版libsundials_nvecserial.soを用いていることも着目すべきです。
外部ライブラリでなく、ユーザコードで最も計算負荷の高いループはソースdemag.cに存在します(これは図4内に示された共有オブジェクトdipolar.soに含まれています)。これは以下のループです:
for (i = 0; i < plan->total_length; i++) {
Hx[i] = Nxx[i] * Mx[i] + Nxy[i] * My[i] + Nxz[i] * Mz[i];
Hy[i] = Nxy[i] * Mx[i] + Nyy[i] * My[i] + Nyz[i] * Mz[i];
Hz[i] = Nxz[i] * Mx[i] + Nyz[i] * My[i] + Nzz[i] * Mz[i];
}
このループはユーザコードのCPU時間の5.46%を占めています。
8.スレッド性能
OpenMP領域は3箇所存在します。表5に16スレッド実行での指標を示しました。サブルーチン毎に1つのOpenMP領域のみ存在しています。
| サブルーチン | 時間[s] | 実行回数 | 平均時間 | 平均ループ回数 |
| fftw_spawn_loop | 56.528 | 479,616 | 1.17861×10-4 | 15 |
| compute_exch_field_micro | 1.163 | 39,255 | 2.9649×10-5 | 10,000 |
| llg_rhs | 1.045 | 37,314 | 2.8006×10-5 | 10,000 |
表5から、OpenMP領域は大きな回数繰り返され、各実行における平均の実行時間は極めて小さくなっています。これはOpenMPを有効に活用していないと言えます。一つのOpenMP領域に大きな実行時間を持たせて、OpenMPのランタイムシステムのオーバーヘッドを抑えるのが理想的です。さらにFFTWはループ長が15となっており、16スレッド実行時には各スレッドはループ1を実行して一つは何も実行しない状況です。これも全く効率的ではありません。他の2つのループも各スレッドのループ長は625であり、更にこれを大きくしてOpenMPのオーバーヘッドを抑えるべきです。
Intel VTuneを用いてOpenMP領域とシリアル領域の実行時間の割合を計測出来ます。

図5:16スレッド/micromagnetic/std4テストケースのVTuneプロファイル
図5からシリアル領域は75.2%、OpenMP領域は24.8%であることが分かります。最大のOpenMP領域はFFTWで、残りの2つはユーザコードです。
9.検証のまとめ
以下に検証結果を纏めます:
- FIDIMAGは16スレッドでの実行時間の内91%強をコンパイルコード(C言語)が占め、残りはPythonコードが占める(図2)。このことは、Pythonコードが計算負荷の高いコンパイルコードを呼び出す役割として有効に利用されていることを示している。
- 図1から、線形スケーラビリティをかなり下回る。
- 表3から、スレッド数の増加に伴い負荷バランスは急速に悪化し、並列効率とグローバル効率は減少する。
- 図3から、スレッド1(OpenMPマスタ)の実行命令数は、他のスレッドに比べ非常に大きい。つまりスレッド2から16までは多くの時間スピンしている。
- 表5から、OpenMP並列ループは大きな回数呼ばれており、各OpenMP領域は非常に小さな実行時間を有している。ループ長を大きくして十分な仕事量を各スレッドに与えるべきである。
- 図5から、16スレッド実行時には75.2%の実行時間がシリアル実行している。
- 表4から、IPCスケーリングの減少が示されている。
9.1 推奨
以下に推奨される作業を記します:
- 8章で示した通りコードの75%がシリアル実行しており、より多くのコード部分をOpenMP化するのが良いでしょう。7章で特定された高負荷ループはOpenMP並列化とベクトル化の候補です。
- 8章で記しましたが、ループ長を大きくしてOpenMPの仕事量を増加させ、オーバーヘッドを少なくすべきです。
- FIDIMAGはシリアル版のSundialsライブラリ(libsundials_nvecserial.so)を用いていますが、OpenMP並列版(libsundials_nvecparallel.so)も存在するのでこれを利用すべきです。コードの変更は不要で、リンクを変更するのみで可能です。
- 図4によれば、最も負荷の高いカーネルはFFTで、FIDIAMGはそのオープンソースバージョンを用いています。これをIntel MKL実装版へ変更することでよりオープンソース版のFFTWより良い性能を得ることが可能です。コードの変更は不要で、リンクを変更するのみで可能です。
- 以上の変更後に、再度表4に示したIPCの減少の原因を調査すると良いでしょう。
補足事項:この作業はPOPプロジェクト(*)の任務として担当したnAGのスタッフが実施しました。
(*)EUのHPCプロジェクトPerformance Optimisation and Productivity (POP)は、科学技術研究に対するHPC技術の利用を促進を目的として欧州委員会によって推進されているHPC領域の8つのセンターオブエクセレンスの1つです。POPは2015年に開始され、バルセロナ・スーパーコンピューティングセンターに設置されました。POPプロジェクトには、nAG、ユリッヒおよびシュツットガルト・スーパーコンピューティングセンター、アーヘン大学、Teratecがパートナーとして選ばれました。
POPは、EU内の組織に無料でサービスを提供しており、並列ソフトウェアのパフォーマンスを分析かつ問題を特定してパフォーマンスの改善を提案するプロジェクトです。性能分析ツールとして、バルセロナ・スーパーコンピューティングセンターで開発されたExtraeとParaverが主に用いられています。