
Nick Dingle, Jonathan Boyle, Sally Bridgwater
Numerical Algorithms Group
25 August 2016
背景
お客様:Stan van Gisbergen博士、Software for Chemistry and Materials (SCM)
アプリケーション:DFTB
言語:Fortran
プログラミングモデル:MPI
使用入力データ:Water_2700_Pur.run
ADFバージョン2016.101に含まるDFTBを使用しました。このコードは、Intel®MPIライブラリーを含むIntel®コンパイラー・スイート・バージョン16.0.3でコンパイルされています。我々は、132GB RAMを搭載した12コアIntel Xeon E2670 2.3GHz CPUを2基搭載した24コアマシンでテストしました。入力データの強スケーリング性能を、Extraeを用いて記録しました。トレースファイルを分析可能なサイズに保つために、SCC反復数を最初の入力値12から6に減らしました。これは、第2関心領域の収束許容値を抑えることで行いました。
アプリケーション実行時間の構造
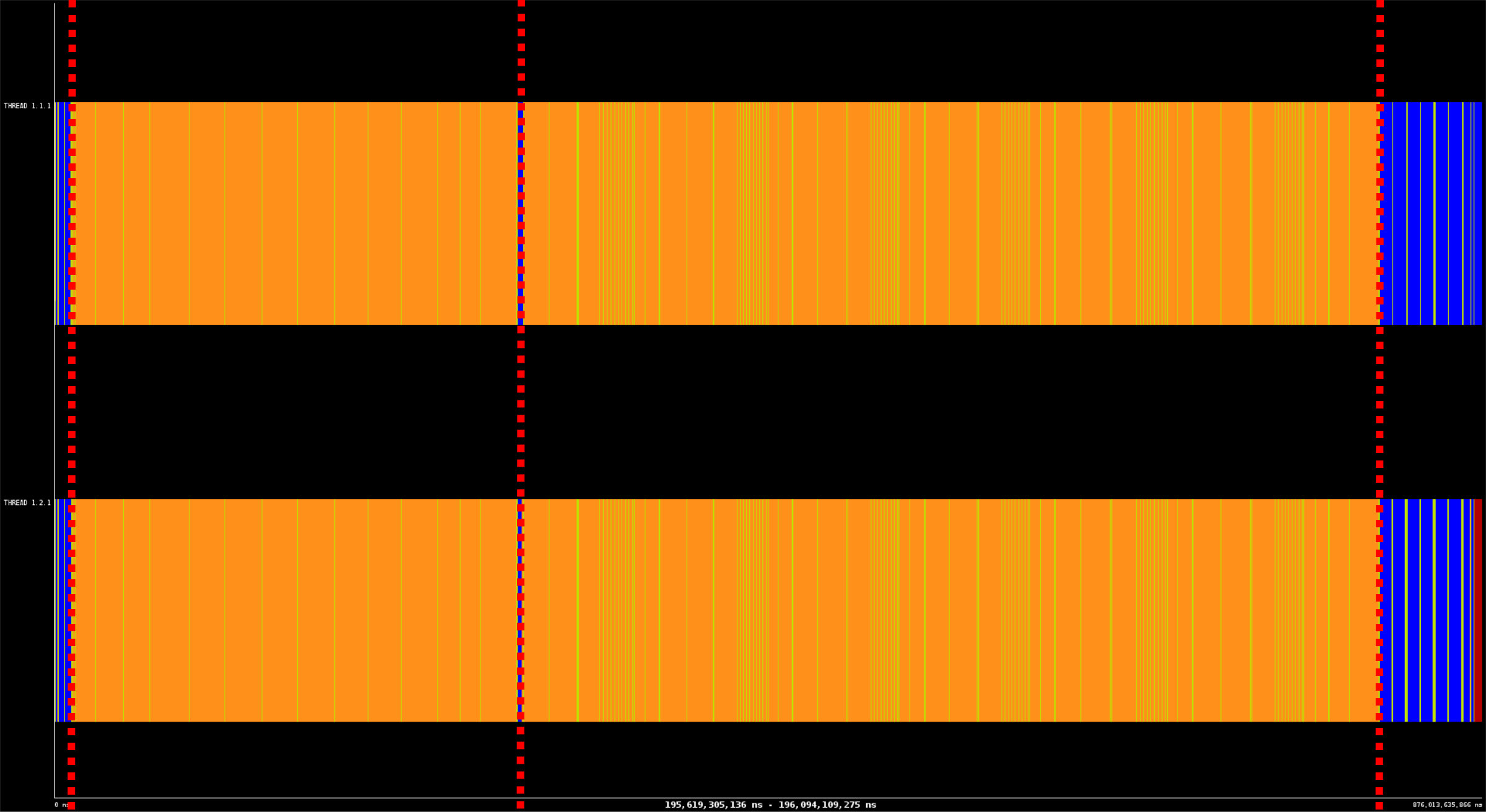
図1:DFTBの実行タイムライン。赤破線で4つの領域に分けた。
図1は、2つのMPIプロセスを用いた場合のDFTBの実行タイムラインを示しています。アプリケーションには、主に4つのフェーズが存在します:
- 初期化:アプリケーションは、入力ファイルから問題の設定を、データベースから指定の物性パラメータを読み込む。
- 関心領域1:軌道関数重なり積分行列の平方根に対する繰返し計算
- 関心領域2:セルフコンシステントチャージ(SCC)繰返し計算
- 終結処理:結果を画面とディスクに書き込む
MPIランク数の増加に伴う同様の構造を観察しました。
各関心領域(ROI)

図2:16プロセスでのROI1の計算時間タイムライン。暗い部分はより長時間の計算を示す。
図2は、16プロセスでのROI1の計算時間タイムラインを示します。図3は、これに相当するMPI呼出しタイムラインです。このテストで用いられている入力パラメータでは、ROI1には6つの繰返しが存在し、各々は3種の分散スパース行列-行列積の計算が必要です。これらのタイムラインは、プロセッサ間に渡る正常な構造を示しています。この構造は、全てMPI_BcastとMPI_Allreduceのみから成る集団通信であることから生じます。
図3で使用されたスケールでは、MPI呼出しは非常に長い持続時間を持つように見えますが、より拡大してみると、データのブロードキャスト間に短い計算部分が存在することが解ります。図4にROI1を65ミリ秒に拡大した図を示します。

図3:16プロセスのROI1のMPI呼出しタイムライン。黄色はMPI_Bcast、ピンクはMPI_Allreduceを示す。

図4:65ミリ秒に拡大したMPI呼出しタイムライン。
図5と6は、これに相当するROI2のタイムラインを示しています。ここにも6つの繰返しとMPI_BcastとMPI_Allreduceによる構造が示されています。ROI1と同じく、MPI通信部分は多くの小さな集団通信から構成されています。

図5:16プロセスでのROI2の計算時間タイムライン。暗い部分はより長時間の計算を示す。

図6:16プロセスのROI2のMPI呼出しタイムライン。黄色はMPI_Bcast、ピンクはMPI_Allreduceを示す。
スケーラビリティ
図7は、DFTBが小規模プロセス数を超えるとスケールしなくなり、8プロセスで理論値の80%以下に劣化することを示しています。図8は、各ROIの2プロセスに対する相対高速化率を示します。共に、高速化は線形で16プロセスまで理論値の80%以上に見えますが、24プロセスで急落します。DFTB全体のスケーラビリティ(図7)はROI個別の性能(図8)より悪化しています。これは初期処理と終結処理フェーズが、プロセス数が増えるとその割合が増加するためです。
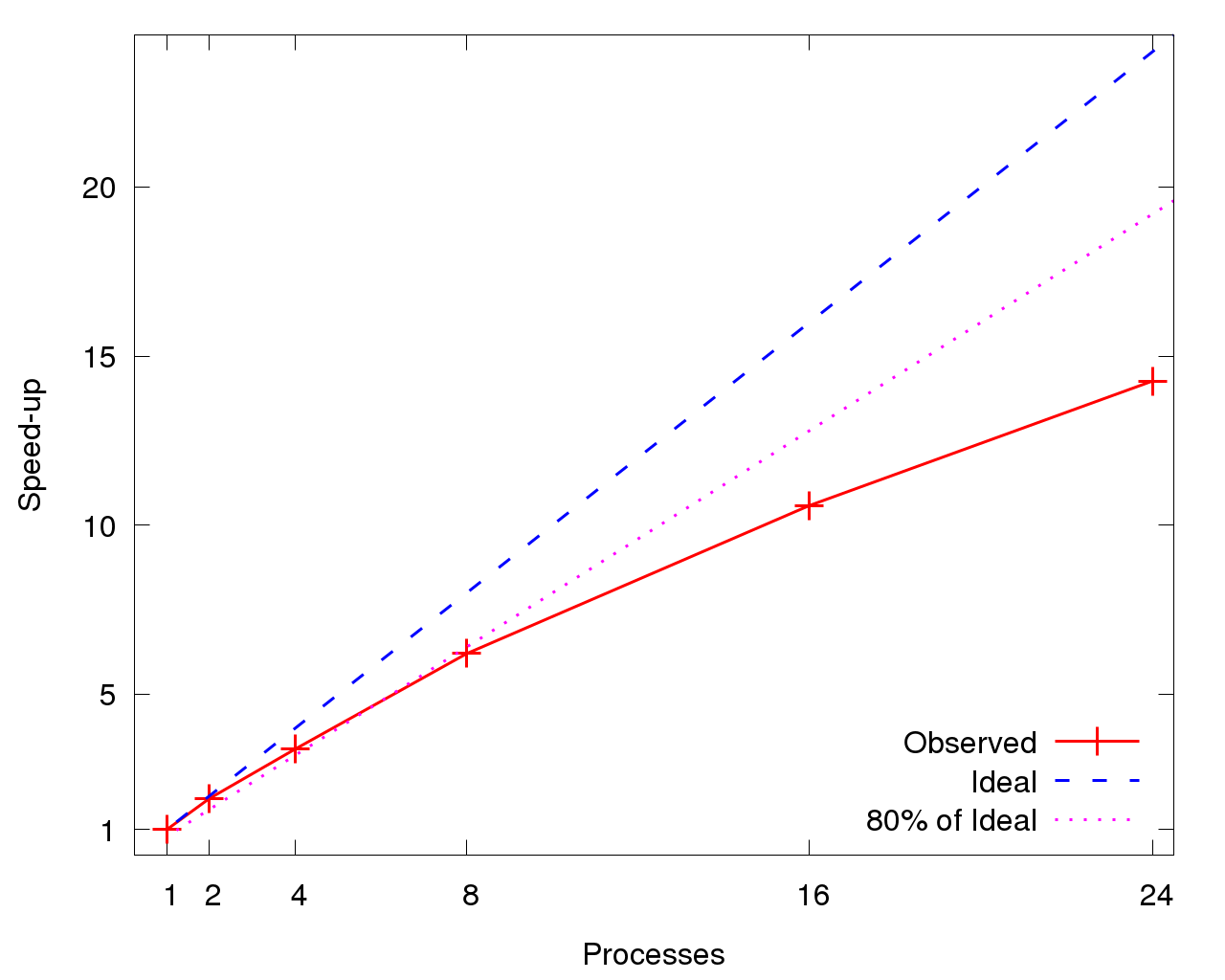
図7:DFTBの高速化率。基準の1プロセスの時間は1355.3秒。
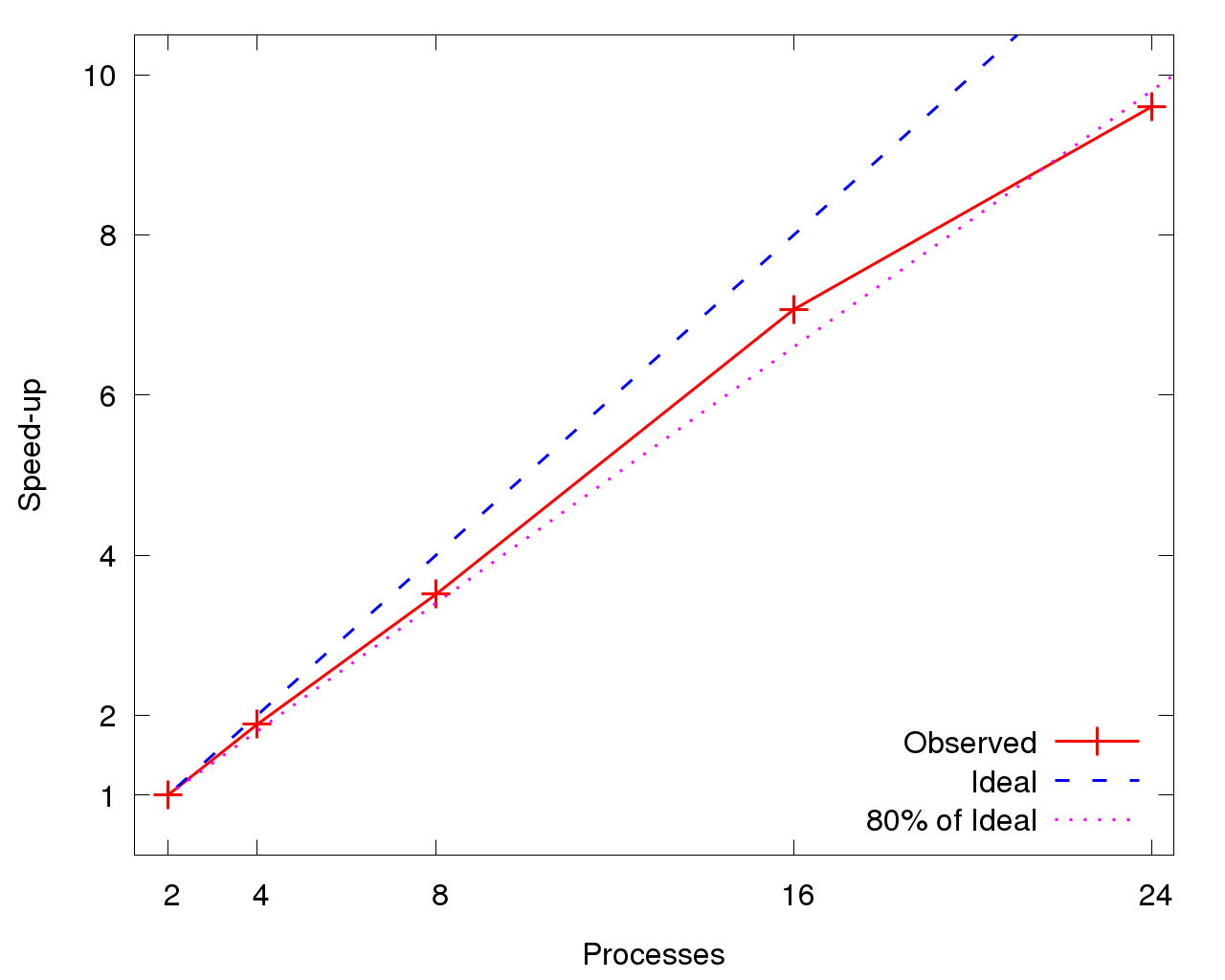 |
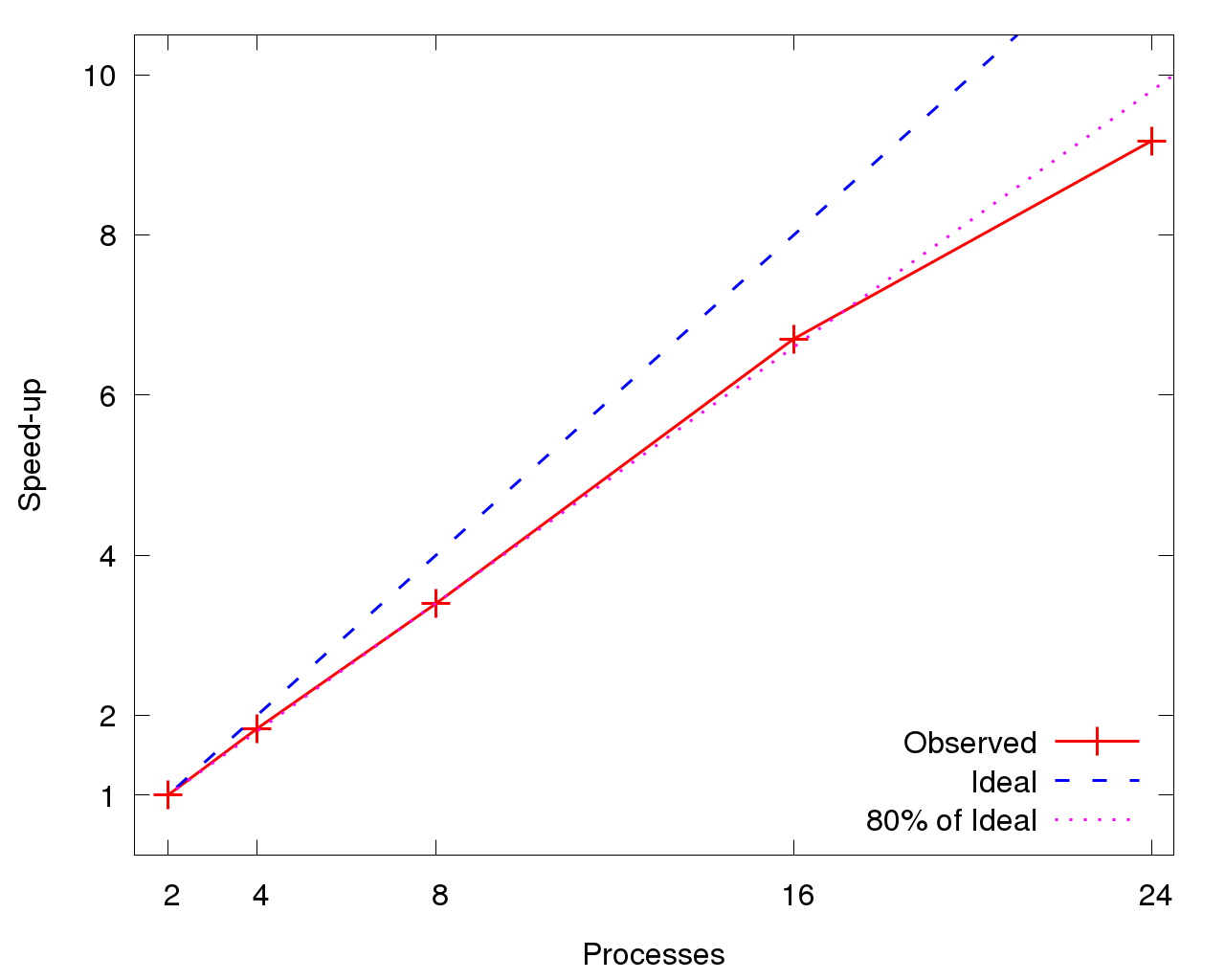 |
効率
各ROIの性能を表2と3に定量化しました。この値は、1を理論値として0から1までで効率を表しています。最初の表は全効率(Global Efficiency)です。これは、並列効率(Parallel Efficiency)と計算効率(Computation Efficiency)の積です。並列効率は負荷バランス効率(Load Balance:1プロセスの最大計算時間に対する平均計算時間の比)と、転送効率(Transfer Efficiency:データ転送による時間ロス)およびシリアル実行効率(Serialisation Efficiency:MPI操作の完了待ちのための時間ロス)の積です。これらメトリクスの詳細な記述は、https://sharepoint.ecampus.rwth-aachen.de/units/rz/HPC/public/Shared%20Documents/Metrics.pdfを参照してください。
| Procs. | RoI1 | RoI2 |
| 2 | 34.1% | 60.7% |
| 4 | 32.3% | 59.0% |
| 8 | 28.4% | 52.2% |
| 16 | 26.2% | 49.2% |
| 24 | 22.6% | 42.1% |
| Procs. | Communication | Computation | Global Efficiency | |||||
| Load Balance | Transfer Efficiency | Serialization Efficiency | Parallel Efficiency | IPC Efficiency | Instruction Efficiency | Computation Efficiency | ||
| 2 | 0.99 | 0.99 | 0.99 | 0.96 | 1.00 | 1.00 | 1.00 | 0.96 |
| 4 | 0.98 | 0.98 | 0.97 | 0.93 | 1.00 | 1.00 | 1.00 | 0.94 |
| 8 | 0.97 | 0.97 | 0.95 | 0.90 | 0.99 | 1.00 | 0.99 | 0.89 |
| 16 | 0.99 | 0.96 | 0.92 | 0.87 | 0.99 | 1.00 | 0.99 | 0.86 |
| 24 | 0.98 | 0.96 | 0.90 | 0.84 | 0.94 | 1.00 | 0.94 | 0.79 |
| Procs. | Communication | Computation | Global Efficiency | |||||
| Load Balance | Transfer Efficiency | Serialization Efficiency | Parallel Efficiency | IPC Efficiency | Instruction Efficiency | Computation Efficiency | ||
| 2 | 0.99 | 0.98 | 0.98 | 0.95 | 1.00 | 1.00 | 1.00 | 0.95 |
| 4 | 0.97 | 0.97 | 0.95 | 0.89 | 0.99 | 1.00 | 0.99 | 0.88 |
| 8 | 0.97 | 0.90 | 0.88 | 0.77 | 0.97 | 1.00 | 0.97 | 0.75 |
| 16 | 0.97 | 0.94 | 0.86 | 0.79 | 0.96 | 1.00 | 0.96 | 0.76 |
| 24 | 0.98 | 0.94 | 0.82 | 0.75 | 0.91 | 0.99 | 0.90 | 0.68 |
ROI1では、プロセス数が増えるにつれてGlobal Efficiencyは低下します。これは、Parallel EfficiencyとComputational Efficiencyの低下によるものです。ROI2でも同様の減少が見られますが、Serialisation EfficiencyはROI1よりも低くなっています。これにより、Parallel Efficiency はROI1よりもROI2のほうが低くなっています。
Load Balance
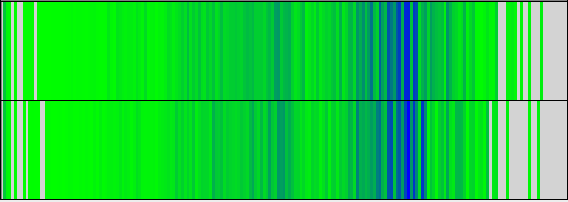
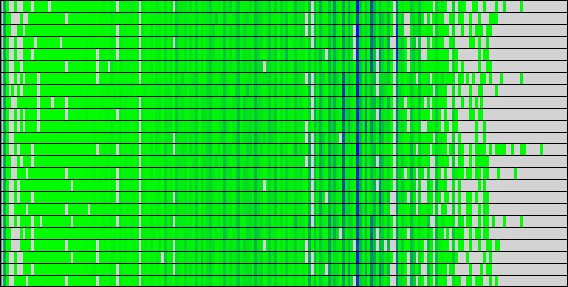
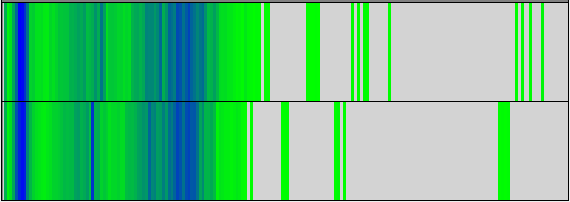
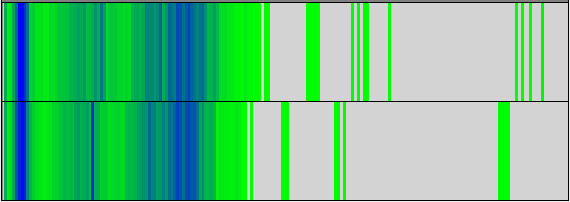
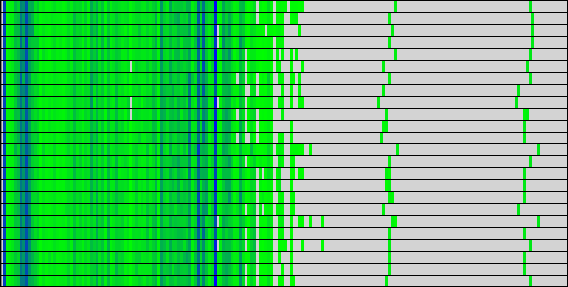
前節で示したようにDFTBのLoad Balanceに大きな問題は有りません。図9,10の計算時間と命令数からもわかる通り、これらは全てのプロセス間で非常によく似た分布を示しています。これらの図には、2つの指標のビニングされた値が表示され、特定のビンにさらに多くのアイテムがあることを示す暗い色が表示されています。y軸はプロセスで、x軸はbin値です。
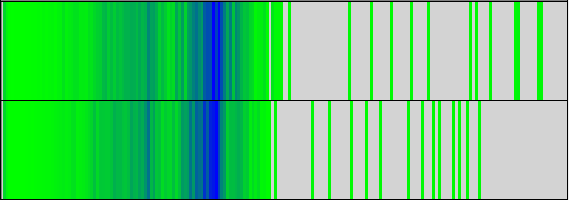 |
 |
|
| (a) Useful duration, 2 processes | (b) Instructions, 2 processes |
 |
 |
|
| (a) Useful duration, 24 processes | (b) Instructions, 24 processes |
 |
 |
|
| (a) Useful duration, 2 processes | (b) Instructions, 2 processes |
 |
 |
|
| (a) Useful duration, 24 processes | (b) Instructions, 24 processes |
計算性能
表2,3では、DFTBの計算部分のスケール性を示す、IPC efficiencyとinstructions efficiencyが示されています。理想的には、今は強スケーリング問題を対象にしているので、プロセス数の増加に伴い一定値(効率=1)を維持すべきです。ここでは、コア数を増やしていく際に命令数は増加せず、IPCは24プロセスで大きく減少しています。命令数が増えていないことから、並列化による大きなオーバーヘッドが生じていないことが示唆されます。
単一プロセスのシリアル実行においては、約90%の実行時間がMKL BLAS DGEMMルーチンで費やされています。このルーチンは、十分にキャッシュ効率やベクトル化が最適化されているため、DFTBのシリアル実行の最適化をしてもあまり多くの利得は得られないと見て良いでしょう。表4は実際のIPC値を示しますが、これらの状況をよく説明しています。値はほぼ2.7を示し、良好な数値とみることが出来ます。
| Procs. | RoI1 | RoI2 |
| 2 | 2.75 | 2.73 |
| 4 | 2.77 | 2.71 |
| 8 | 2.72 | 2.66 |
| 16 | 2.72 | 2.62 |
| 24 | 2.59 | 2.50 |
通信
| Procs. | ROI 1 | ROI 2 | ||
| MPI Bcast | MPI Allreduce | MPI Bcast | MPI Allreduce | |
| 2 | 3.52% | 0.05% | 4.97% | 0.18% |
| 4 | 6.83% | 0.04% | 9.59% | 0.18% |
| 8 | 9.55% | 0.09% | 22.07% | 0.96% |
| 16 | 13.16% | 0.04% | 20.18% | 0.30% |
| 22 | 15.56% | 0.03% | 24.16% | 0.37% |
表5に示すように、どちらのROIでも最も時間が掛かっているMPI関数は、MPI_BcastとMPI_Allreduceです。DFTBの計算カーネル(分散スパース行列-行列積)は、プロセス間のデータ通信の殆どにMPI_Bcastを用います。MPI集団通信の多用は並列効率の劣化を生じます。これは、プロセス数の増加に伴い同期オーバーヘッドが増加するためです。
分析結果のまとめ
DFTBの並列効率は、プロセス数の増加に伴い緩やかに劣化します。これは、MPI集団通信の広範な使用によるものと、推察されます。また、最大コア数においてIPCの劣化も観察しました。
今後推奨される作業は以下の通りです:
- 更なる詳細な調査:
- Serialisation Efficiencyの劣化が他の指標の落ち込みよりも大きい理由と、ROI1よりもROI2の場合の方がより劣化している原因の特定
- IPCの劣化の原因の特定
- 集団通信を用いない分散スパース行列-行列積の手法の調査
- DFTBはDGEMMを多用しているため、MKLのマシン専用バージョンにリンクして最も性能の高くなるような実装をすべきです。PLASMAやlibflame等のライブラリの利用を調査することを考えても良いでしょう。
補足事項:この作業はPOPプロジェクト(*)の任務として担当したnAGのスタッフが実施しました。
(*)EUのHPCプロジェクトPerformance Optimisation and Productivity (POP)は、科学技術研究に対するHPC技術の利用を促進を目的として欧州委員会によって推進されているHPC領域の8つのセンターオブエクセレンスの1つです。POPは2015年に開始され、バルセロナ・スーパーコンピューティングセンターに設置されました。POPプロジェクトには、nAG、ユリッヒおよびシュツットガルト・スーパーコンピューティングセンター、アーヘン大学、Teratecがパートナーとして選ばれました。
POPは、EU内の組織に無料でサービスを提供しており、並列ソフトウェアのパフォーマンスを分析かつ問題を特定してパフォーマンスの改善を提案するプロジェクトです。性能分析ツールとして、バルセロナ・スーパーコンピューティングセンターで開発されたExtraeとParaverが主に用いられています。