
Jonathan Boyle, Sally Bridgwater, Nick Dingle
Numerical Algorithms Group
2 Nov 2016
背景
お客様:Stan van Gisbergen博士、Software for Chemistry and Materials (SCM)
アプリケーション:BAND
言語:Fortran
プログラミングモデル:MPI
使用入力データ:tube_small_mos2 with DZ basis
BANDは、周期系の原子軌道を用いる密度汎関数理論(DFT)コードです。
このレポートでは、強スケール性の調査のために性能データを採取しました。ソースコードは、ADF 2016.101を用い、インテルコンパイラ16.0.3およびMPI5.1.3を用いてコンパイルされました。性能データは、Extrae3.3を用いて収集し、Paraver等を用いて分析を行いまいした。
また、Score-P3.0、Scalasca2.3.1およびCubeを用いたデータ採取と分析も行いました。MPI呼び出し経路に現れない小さなユーザ関数の除去にScore-Pフィルタリングを用いました。
最初の性能データは、24コアのマシン(Oban)上で採取しました。これは2個のインテルXeon E2670 V2(Haswell)プロセッサを搭載した共有メモリーマシンです。特に記載のないデータはObanのデータを示すこととします。
2番目の性能データは、インターコネクト性能を見るためにバルセロナ・スーパーコンピュータセンターのマレノストルムⅢ(MN)で採取しました。MNは、インフィニバンドFDR-10で結合された2個のインテルE5-2670(Sandy Bridge)プロセッサを持つノードで構成され、各ノードは16コアを持ちます。
アプリケーション構造
Paraverのタイムラインには大規模な構造がみられますが、コア数には独立に見受けられます。図1に8MPIプロセスのデータを示します。このレベルの解像度では、計算と通信の全ての複雑さが可視化されていません。
コードは、短い初期化フェーズの後に18回のSCFサイクルを計算し、最後のポストプロセスフェーズで終了します。初期化フェーズは、通常実行時間の数%が掛かります。SCFサイクルとポストプロセスは、それぞれ実行時間の2/3と1/3の割合です。Oban上の実行時間は、2プロセスで42分弱、24プロセスで7.5分掛かりました。MNノード3個(64プロセス)での実行時間は、4分以下でした。
図の上部の色は、計算の経過時間の長さを表し、明るい緑から暗い青まで変化します(例えば、明るい緑は0から10秒、暗い青は35から44秒です)。
図の下部は、MPI時間の大部分がMPI_Allreduce(ピンク)に費やされたことを示しています。MPI_Barrier:赤、MPI_Bcast:黄色も可視化されています。

図1:Paraverによる8MPIプロセスのタイムライン
図2は、8MPIプロセスでScore-Pで採取したデータに対するCubeのスクリーンショットです。ツリーの未展開ノードにはインクルーシブ時間、展開ノードに対してはエクスクルーシブ時間が示されます。これらの値は全プロセスの合算値です。
図の左側は、実行時間とMPI転送バイト数が示され、一部展開されたところにはその相対値が示されています。ここから、1対1通信よりも集団通信が支配的であることが判ります。MPIと計算の相対的な負荷も時間的に示されています。
図の右側は、コールツリーと青で強調表示された上記指標への寄与(全時間)が示されています。このツリーは部分的に展開され、高コストユーザルーチンを示しています。
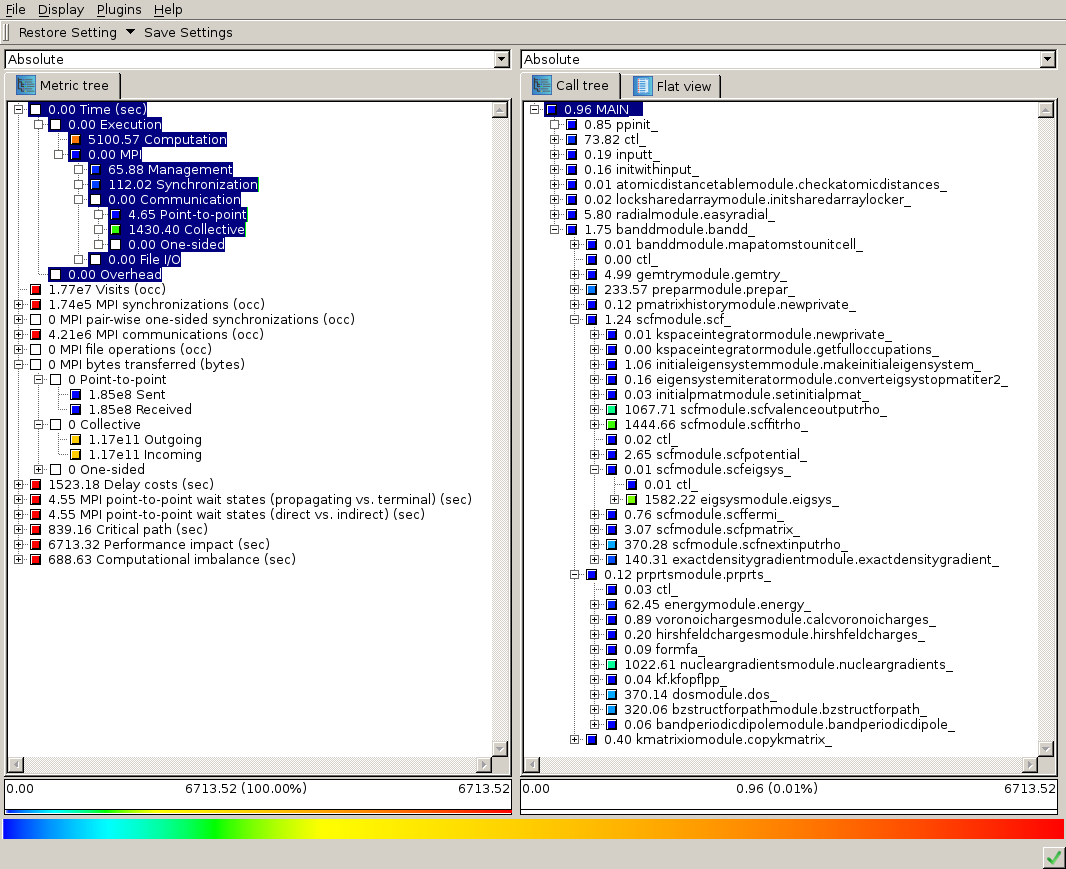
図2:8MPIプロセスのCubeのスナップショット
解析対象
さらに、ObanのExtrae性能データを2つの関心領域(ROI)に分割します。ROI1は、1回目から16回目のSCFサイクルのみを含み、最初と最後のサイクルをそれとは異なるものとして除きます。ROI2は、全ポストプロセスを含みます。
スケール性
図3にはBAND計算の高速化率が示されています。ここで、赤線は線形の場合、青線は観測値です。参照値は、Obanでは2プロセスでの、MNでは16プロセス(1ノード)での実行時間です。共有メモリーマシンにおいても性能は理想値には程遠い値です。インターkonekutoマシンでも同様です。
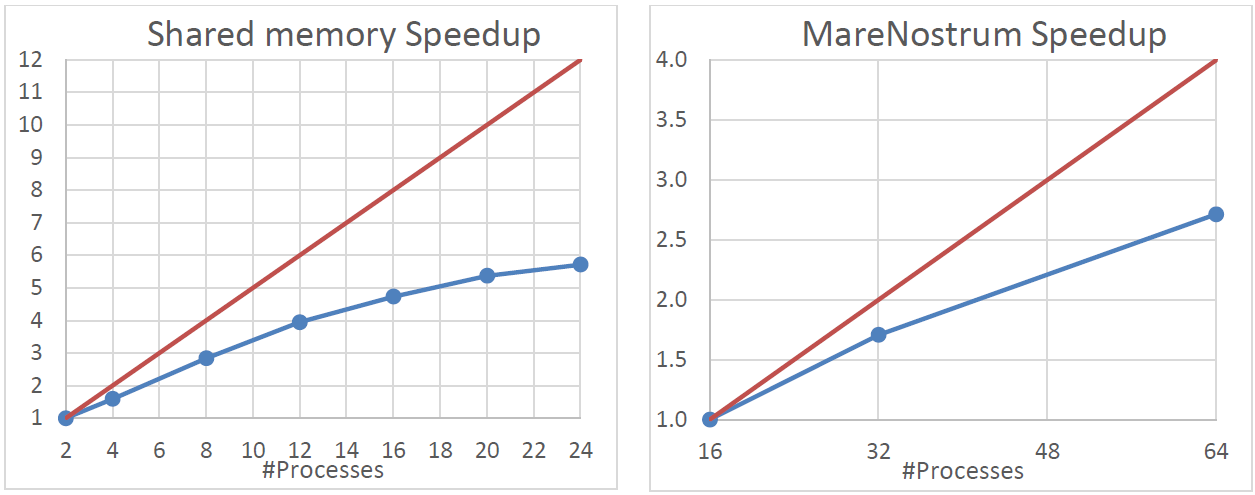
図3:ObanおよびMN上のスケール性
効率
効率に関する指標については、この章で議論します。値は0から1を採り、大きければ良好、1が最適、0.8以下は劣化しているとみなします。表では0.8を境に、それ以上を緑、以下を赤でグラデーションして示します。
このデータの解釈には以下の理解が役立ちます:
- Global efficiency = parallel efficiency * computation efficiency
- Parallel efficiency = load balance * communication efficiency(この値は通常定義される並列効率とは異なります)
これ以外の指標については関連するセクションで簡潔に定義します。詳細についてはPOPプロジェクトのサイト:https://pop-coe.eu/further-information/learning-materialをご覧ください。
ここで、計算、IPC(instructions per cycle)、命令数のスケーラビリティは、ObanおよびMNではそれぞれ2プロセスおよび1ノードを基準とします。さらにデータ採取は、計算の間のみに限ります。即ち、MPIに関する命令数、サイクル数、時間を省きます。
表1と2は、2から24プロセスまでの全計算の値で、性能劣化には2つの要因があります。最初の問題は、4プロセス以降では負荷バランスが悪いことです。 この負荷バランスは4から24プロセスではそれほど大きく低下していません。
もう一つの問題は、コア数が増えると計算のスケーラビリティが劣化することです。この原因の一つは、IPCの減少です。即ち、計算速度の低下です。全命令数を比較すると、多かれ少なかれプロセス数には依存しません。しかしながら、計算のスケーラビリティは、IPCのスケーラビリティよりも劣化しています。よって、別の原因があることが示唆されます。例えばCPUコアの周波数の変動などです。これ以外にIPCのスケーラビリティは12コアを超えると劣化しています。これはNUMAアーキテクチャによるものである可能性が有ります。
その他の効率指標はプロセスが増えても劣化は小さいです。
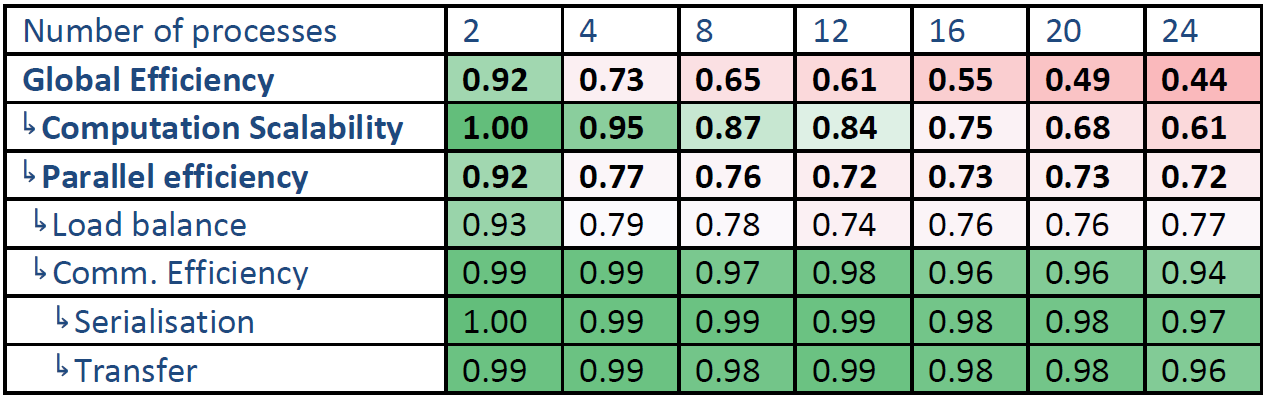
表1:Oban上の時間ベースの全計算効率

表2:Oban上のハードウェアカウンタベースの全計算効率
表3から6は、Oban上でのROI1と2の効率指標を示しています。全体的に同様な状況が示されていますが、ROI1と2の間に大きな違いはありません。ROI1と2は全計算と同様の負荷バランスを示しています。つまり、4プロセスを超えると劣化し、それ以上で極端な劣化はありません。しかしながら、ROI1よりもROI2 の方が若干低くなっています。
対照的に、ROI1はROI2よりも計算スケーラビリティが低いです。これはROI1 はより低いIPC値を持つためです。
ROI2は、プロセス数の増加に伴い通信効率の若干の減少を示します。これは、シリアライゼーション効率と転送効率の減少によるものです。ですが、24プロセスで通信効率0.86という値は悪くありません。
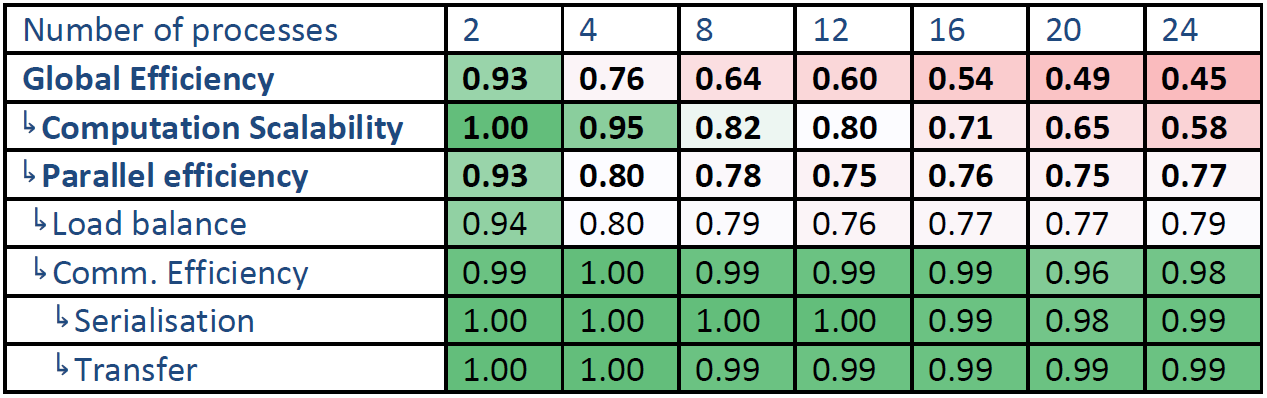
表3:Oban上のROI1の時間ベースの効率

表4:Oban上のROI1のハードウェアカウンタベースの効率
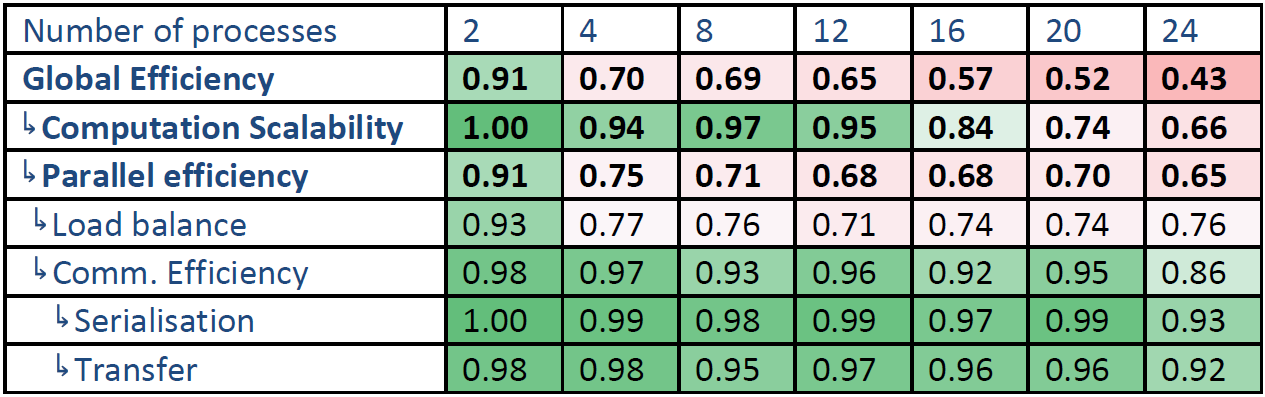
表5:Oban上のROI2の時間ベースの効率

表6:Oban上のROI2のハードウェアカウンタベースの効率
表7と8は、MN上の全計算に対する指標を示します。1ノード(16プロセス)はObanの16プロセスの値と似ています。しかしながら、負荷バランスはノード数の増加に伴いさらに劣化しています。ノード内の効率とは対照的に、ノード間では、命令数のスケーラビリティの劣化がみられます。ですが、IPCスケーラビリティは良好です。言い換えれば、ノードの増加に伴い命令数が増加しています。
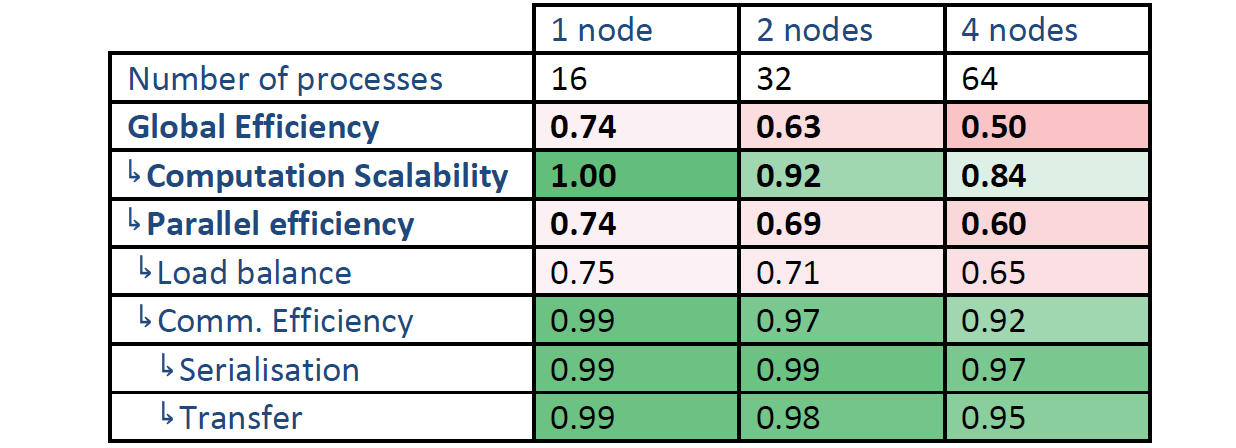
表7:MN上の全計算の時間ベースの効率

表8:MN上の全計算のハードウェアカウンタベースの効率
負荷バランス
負荷バランス効率は、プロセス実行時間の最大値に対する平均値の比として計算され、作業がどの程度均等に割り振られたかを示します。
負荷分散は、このコードの主要な問題の一つで、以下の2つのパターンがあります:
- Oban上では、負荷バランス効率は、2プロセスの0.93から、4から24プロセスに対して0.79から0.74へ減少する。
- MN上では、1ノード(16プロセス)の0.75から、4ノード(64プロセス)の0.65へ減少する。
命令数とIPCの負荷バランス効率を同様に計算した結果を表9に示します(表1の計算負荷バランスと共に記載しました)。これらが示唆するのは、計算的な負荷分散は主にプロセス当たりの命令数(幾つかのプロセスは他より多くの計算量が生じています)の分散によって生じているという事です。IPCにも負荷分散を見ることが出来ます。

表9:Oban上の全計算に対する、計算/命令数/IPCの負荷バランス比較
命令数とIPCの負荷分散は図4から明瞭にみることが出来ます。これは、16プロセス実行時の各プロセスの命令数とIPCを示したものです。高い数値を持つIPCは、多くの命令数を実行するプロセスに対応しています。すなわち、IPCの負荷分散は計算負荷分散を減少させる働きをします。
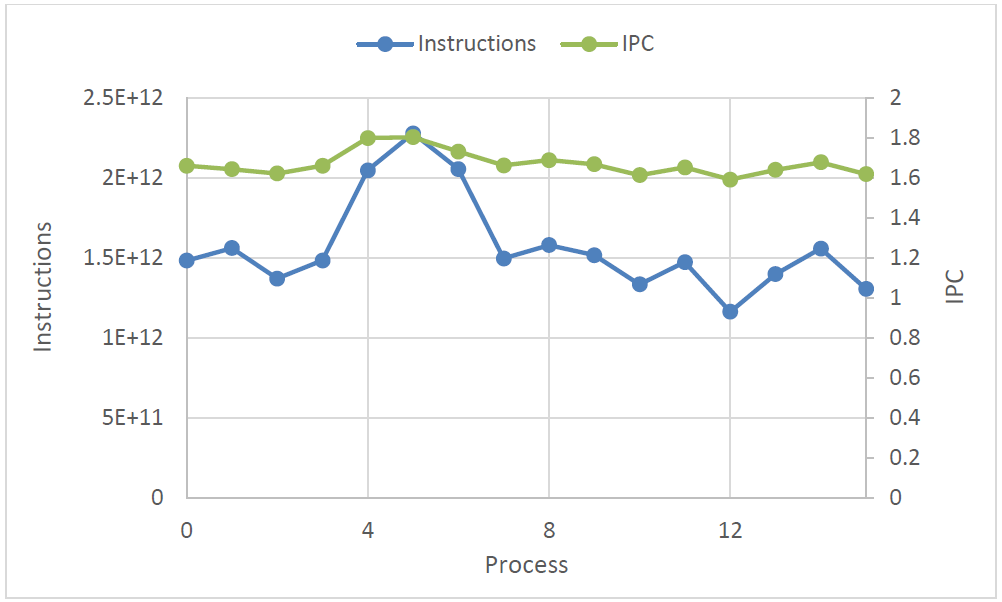
図4:16プロセスでの命令数とIPC
Score-PのデータをScalascaで解析し、どのルーチンが負荷分散に寄与しているかを調べました。表10に、16プロセス実行時の大きい順に10位まで、計算負荷分散が大きなルーチンを示しました。この値は、平均実行時間との差の絶対値を全プロセスで総和を取ったものです。ただし、これらの値にはScore-Pトレース収集から除外されたルーチンからの寄与、例えば MPI関数の呼び出しパスにないMKLと短いユーザー関数への呼び出しなどが含まれます。
| Routine | Computational imbalance(sec) |
| directfockmatrixevaluatormodule.calcfockmatrixdirect | 147.17 |
| functionsetoverlapmodule.updateoverlapasym_new2 | 141.49 |
| functionsettransformmodule.transformfast_real | 118.38 |
| rhofrompmatrixdirectmodule.rhofrompmatrixdirect | 106.15 |
| blochoverlapevalmodule.evaluateoverlapmatricesdirect | 22.30 |
| rhofrompsidirectmodule.rhofrompsidirect | 21.99 |
| pmatpropsdirectmodule.calcpmatpropsdirect | 16.27 |
| preparebasismodule.preparebasis | 15.82 |
| bandzlmfitmodule.blockpropsforzlmfit | 11.04 |
| preparehamiltonianmodule.preparehamiltonian | 9.08 |
このケースでは、4つのルーチンの寄与が特に大きいことが判ります。
計算性能
プロセス数の増加に伴う計算性能の劣化が、このコードのもう一つの問題です。認められる現象は2つあります:
- IPCの減少は単一ノード上で大きい。
- 全命令数はノード数の増加に伴い増加している。
このIPC減少の原因を探るために、レベル1とレベル2のデータキャッシュミスをObanのデータから抽出して1000命令当たりの値として表11に示しました。これらはIPCとは強い相関があるようには見られませんでした。L1 DCMは減少しており、L2 DCMは最初は減少しますが、プロセス数の増加に伴い増加します。
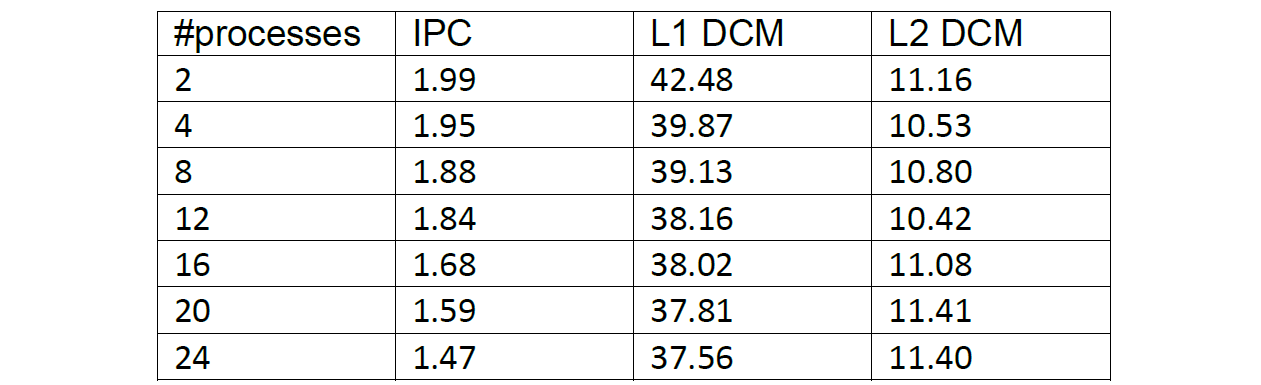
表11:1000命令当たりのレベル1,2データキャッシュミス
IPCの減少はおそらくリソース競合(例えばメモリーアクセス競合)か、NUMAの特性(Obanは2つのNUMAノードを持ちます)、およびノード間通信で追加される仕事が原因による命令数の増加、が要因と考えられます。これらの原因特定には、さらに詳細な調査が必要です。
通信
通信については性能にそれほど大きな問題を与えてはいませんが、以下の現象がみられます:
- Obanのデータでは、プロセス数の増加に伴い、ROI2はシリアライゼーションと転送の効率が小さく減少しています。例えば24プロセスでは、シリアライゼーション効率は0.93、転送効率は0.92です。
- MNのデータでは、ノードの増加に伴い、全計算に対するシリアライゼーションと転送の効率が小さく減少しています。例えば4ノードでは、シリアライゼーション効率は0.97、転送効率は0.95です。
シリアライゼーションとデータ転送は、大きなノード数で増大することが考えられますが、このケースでは強スケーリングを扱っており、4MNノードで十分に大きなサイズになっています。
通信効率は、全てのプロセス時間に対する計算時間の最大の比率で、通信による効率ロスを見るものです。これはシリアライゼーション効率と転送効率の乗算として分割できます。
シリアライゼーション効率からは、プロセス間の依存性、例えばあるプロセスが他のプロセスからの通信呼出しを待ち合わせするなどによる効率ロスを見ることが出来ます。これは、データ転送時間がゼロの完全なネットワーク上で得られるデータ転送効率です。よってここでは、このデータから、プロセスやノード数の増加に伴うシリアライゼーションによるMPI呼出しの待ち合わせ時間の増加をみることが出来ます。
転送効率は、実際のネットワーク上でのデータ転送効率ロスを測るものです。これは実際の実行時間と完全なネットワークでの実行時間の比です。プロセス数が増加するにつれて重要な指標となります。
ここで、Scalascaを用いて4,8,16プロセスでのデータ転送効率を調べました。1対1および集団通信で送受信される総バイト数を表12に示します。集団通信(主にMPI_Allreduce)の値はプロセス数と共に大きく増加しており、さらにプロセス数が増えると性能に大きく影響します。

表12:1対1および集団通信で送受信される総バイト数
まとめ
ここで議論したケースでは、通信効率は総じて良好で、関連するシリアライゼーション/転送効率も共に良好あるいは許容範囲でした。
特定された主要な問題は、負荷分散とスケーラビリティの2つです。これらは性能へ大きな負の影響を与えており、例えば、全計算に対する全体効率はObanの24プロセスにおいて0.44、MareNorstrumの3ノードで0.50でした。
- 負荷バランスは単一ノード上の4プロセス以上で劣化します。
- 負荷バランスはノード数の増加に伴いさらに劣化して行きます。
- 計算スケーラビリティは単一ノード上でプロセス数の増加に伴い低下します。これは部分的にはIPCの減少によって引き起こされますが、IPCの減少は計算性能の低下を十分に説明できません。
- ノード数の増加に伴い命令数が増加します。これは4ノードではそれほど大きな影響がありませんが、より大きなプロセス数においては重大な問題となると考えられます。
ROI1(SCF計算)とROI2(ポストプロセス)のデータは、以下の小さな差異を除きよく似ています:
- ROI2の方が負荷バランスが劣る。
- 計算スケーラビリティはROI1の方が劣る。
- シリアライゼーションと転送効率はROI2の方が多少劣る。
これらの効率劣化をさらに解析するためには、以下の調査作業をお勧めします:
- 計算スケーラビリティ劣化の調査
- IPC減少と他のハードウェアカウンタとの関連性の調査
- NUMAの影響調査
- 他の計算性能の劣化要因の特定
- ノード数増加により命令数が増加するコード領域の特定
- 計算の負荷分散を生じるコード領域における計算量の分布の解析
補足事項:この作業はPOPプロジェクト(*)の任務として担当したnAGのスタッフが実施しました。
(*)EUのHPCプロジェクトPerformance Optimisation and Productivity (POP)は、科学技術研究に対するHPC技術の利用を促進を目的として欧州委員会によって推進されているHPC領域の8つのセンターオブエクセレンスの1つです。POPは2015年に開始され、バルセロナ・スーパーコンピューティングセンターに設置されました。POPプロジェクトには、nAG、ユリッヒおよびシュツットガルト・スーパーコンピューティングセンター、アーヘン大学、Teratecがパートナーとして選ばれました。
POPは、EU内の組織に無料でサービスを提供しており、並列ソフトウェアのパフォーマンスを分析かつ問題を特定してパフォーマンスの改善を提案するプロジェクトです。性能分析ツールとして、バルセロナ・スーパーコンピューティングセンターで開発されたExtraeとParaverが主に用いられています。