
Performance Optimisation and Productivity (POP) プロジェクトの一環として、nAG が本件を担当しました。
ADF モデリング・スイートは、オランダに拠点を置く Software for Chemistry & Materials (SCM) 社によって開発された強力な計算化学パッケージです。このパッケージは、化学・材料工学のための6つのアプリケーションで構成されています。
本件では、ADF モデリング・スイートの幅広い調査を行いました。調査の内容は、新しい機能のパフォーマンスの評価、ボトルネックの特定と修正、ADF,BAND,DFTB の3つのアプリケーションの複合的アプローチのテストなどです。パフォーマンスの分析には、Score-P と Scalasca に加えて、バルセロナ・スーパーコンピューティング・センターの Extrae,Paraver,Dimemas を使用しました。
ADF は、密度汎関数法を用いて分子の構造と反応を予測する計算化学アプリケーションです。nAG の技術コンサルタント Sally Bridgwater は、新しい機能(ハイブリッド交換相関汎関数を用いた中間サイズの分子)に焦点を当てた、開発者にとって興味深い特定の計算を調査しました。
最初の調査で、負荷不均衡が非効率の主な原因であることが分かりました(アイドル時間が発生し、プロセッサが完全に利用されていませんでした)。そして第2の問題は、コア数の増加と共にデータ転送の時間が増加することでした。
ADF は、MPI とノード内の共有 POSIX 配列バッファを用いて並列化されています。これらの共有バッファは、プロファイリングツールによって自動的にキャプチャされないため、Extrae API を使用して手動でプロファイリングする必要がありました。これらの共有配列のロック/アンロックは、負荷不均衡を悪化させ、当初に考えていたよりも多くのアイドル時間をもたらすことが分かりました。
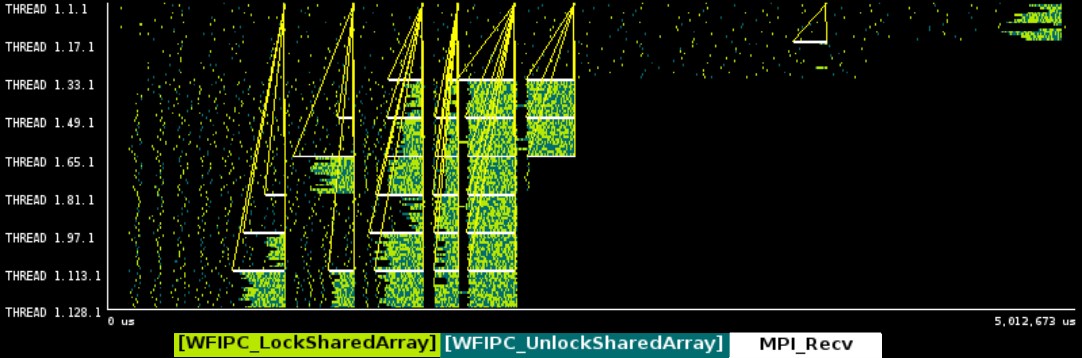
この長いアイドル時間は、負荷分散アルゴリズムが十分頻繁に処理を分散させていないことが原因だと分かりました。 そして、これは特定の場合に使用される不均衡な入力によって悪化しました。 Sally は、より頻繁に処理を分散し、処理のチャンクサイズをチューニングすることで、実行時に2倍の節約を達成できると推定しました。これらの調査により、SCM はパフォーマンスに改善の余地があることを明確に認識しました。
SCM は、(最初に処理をより小さなチャンクに分割したのはもちろんのこと、)負荷分散を管理するための専用のプロセスを使用することで、処理をより頻繁に分散するよう負荷分散スキームを調整しました。SCM はこれらの修正を迅速に行い、推定された2倍の改善を達成しました。
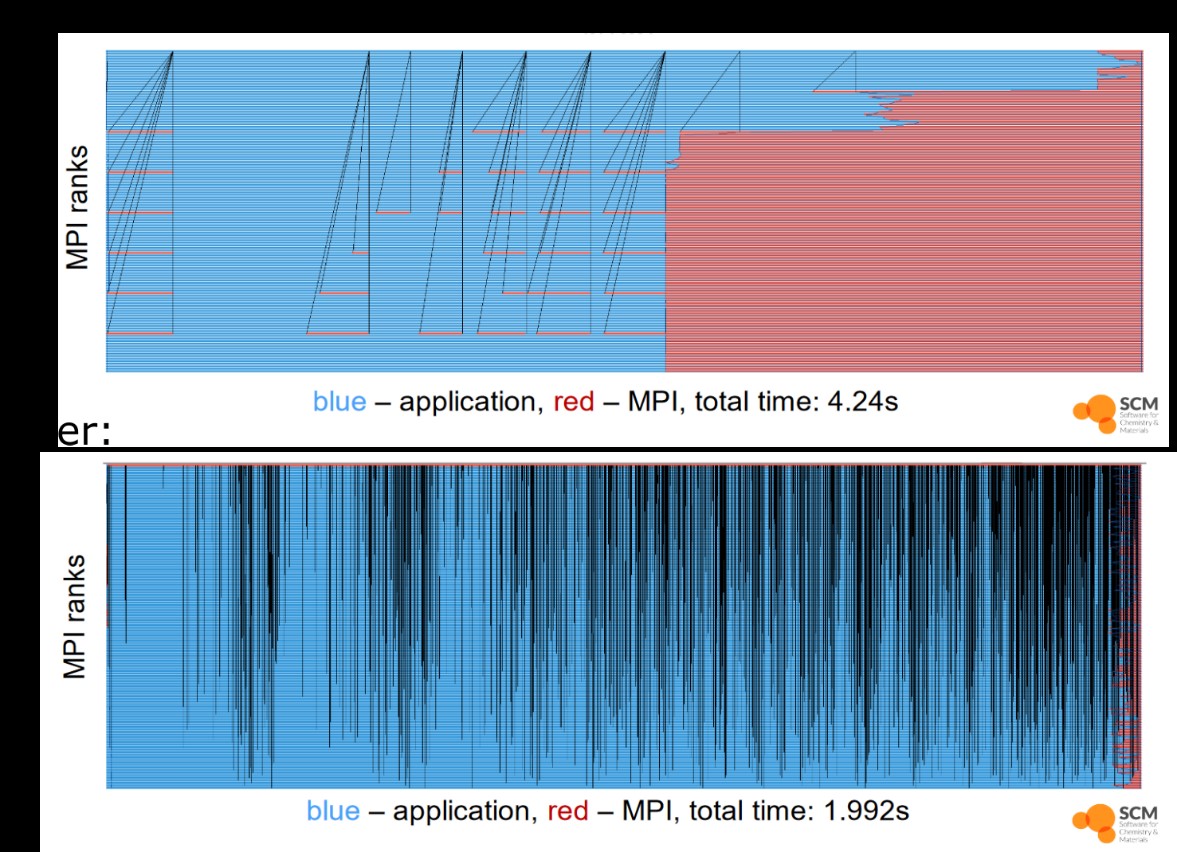
改善前(上)と改善後(下)のタイムラインです。
アイドル時間(赤)が大幅に削減し、実行時間が半減しているのが分かります。
「あなたの分析から、ADF の新しい機能のパフォーマンスに関して新しい洞察が得られました。さらに重要なことは、現在の実装の限界を我々に明確に示し、改善方法を指摘したことです。」 − SCM ソフトウェア開発者、Alexei Yakovlev
nAG の HPC アプリケーションアナリスト Jonathan Boyle は、BAND アプリケーションを調査しました。最初の調査で、中規模のシステムに対する長い実行時間と生成される大量のデータのために、プロファイリングが困難であることが分かりました。しかし、初期の所見として、負荷分散が主なボトルネックであること、そして、これが計算のスケーラビリティーが良くないために悪化していることが分かりました。
BAND のサブコンポーネントに対して2つの詳細な調査を行いました。第1の調査では、重なり行列の計算を調べました。しかし、観測されるパフォーマンスは、計算システムに応じて妥当なものでした。そして、第2の調査を行い、主な問題は、IPC のスケーラビリティの低さによる計算のスケーラビリティの減少であることが分かりました。そして、コード開発者による更なる調査のために、排他時間の最大増加の原因となっているルーチンを特定しました。
第2の調査の焦点は、複素行列の積のパフォーマンスでした。そこでは、各複素行列が2つの共有メモリ実数配列に保持され、各計算ノードに複製されます。これに改善の余地があることが分かり、概念実証を行いました。特定された主なボトルネックは、IPC スケーラビリティの減少と MPI データ転送に費やされる時間の増加でした。計算の大部分は dgemm ルーチン内で行われるため、これが最適化の対象となりました。
Jonathan が行った概念実証は、パフォーマンスを改善するための様々なアプローチをテストし、その中からソースコードで有益なアプローチを実装しました。
実装した最適化は次のとおりです。
- 通信と計算のオーバーラップ
- BLAS の使用の改善(これにより、計算速度が2倍になりました)
- アルゴリズムの再編成(これにより、MPI を介して通信されるデータ量が減りました)
最適化されたサブルーチンは、36 コアの8つの計算ノードにおいて、元のコードと比較して4倍のスピードアップを示しました。
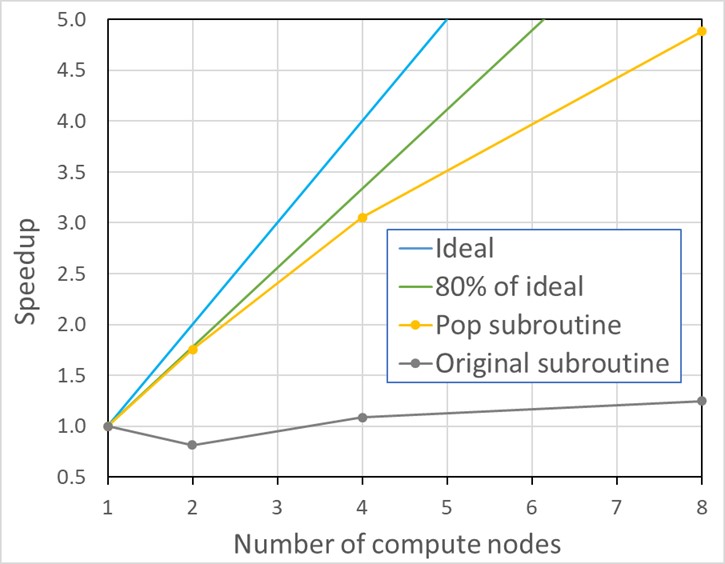
新しいサブルーチンでは、スケーラビリティの大幅な改善が見られます。
nAG の技術コンサルタント Nick Dingle が DFTB アプリケーションに関して行った作業の事例は ここ で読むことができます。